
JSoup CSS/DOM问题

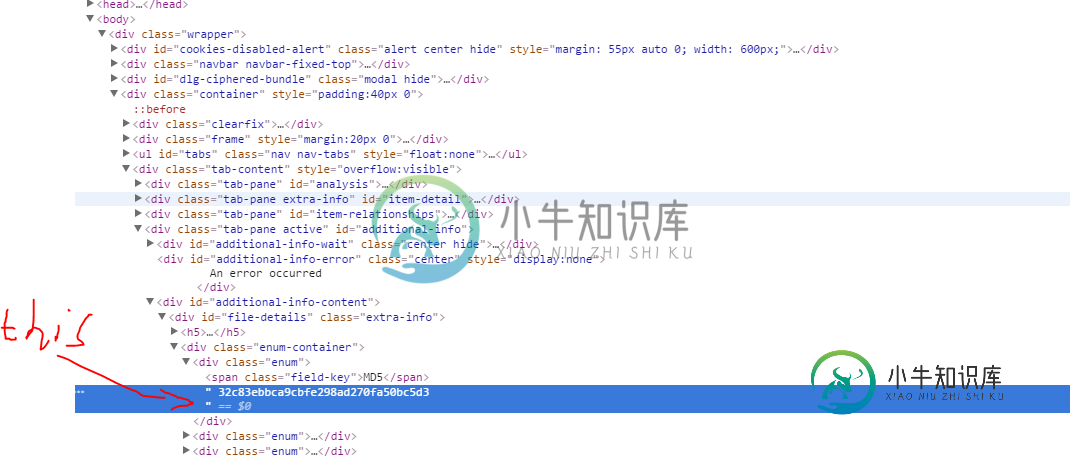
1.(来自:https://www . virus total . com/en/file/7 b6b 268 cbca 9d 421 AABB 5 f 08533d caba 50 e0f 7887 b 07 ef 2 BD 66 BF 218 b 35 ff/analysis/)
我想在图片中获取文本,在Google开发人员工具中,我会这样做(我基本上进入了跨度的另一个子节点以在DevTools中找到md5,但在Jsoup中它似乎不同,只返回“md5”文本)
document.getElementById(“附加信息内容”).childNodes[1].childNodes[1].inerHTML
我无法使用JSoup dom/selector获得它。(如果可以同时给出这两个示例)
2.
如何在Jsoup中指定CSS中的子级?例如,我右键单击图片中蓝色标记线上方的span class字段,然后单击“复制选择器”:
#file-details > div:nth-child(2) > div:nth-child(1) > span
它给了我文件详细信息作为第一个div,甚至认为它不是文档中唯一的文件详细信息,但好吧,让我们说它应该是这样的(?):
#additional-info-content > div:file-details > div:nth-child(2) > div:nth-child(1) > span
我如何设法将其翻译成带有孩子的工作JSoup CSS脚本?(如果可能的话,那么DOM示例也是如此)
3.
在寻找特定值/节点时,是否有很好的洞察力来了解如何寻找以及如何找到正确的路径?
我现在做的基本上是打开开发者工具,然后单击一个唯一的div类名,我检查DevTools内的属性窗口以查找子节点,并继续使用子节点进行挖掘,直到找到正确的路径…(就像我在第一个问题中复制的那样)
有更好的方法来看待这个问题吗?
我的意思是,使用DevTools控制台非常简单,只需编写。儿童[1]。子节点[3]。children[1]虽然在查看属性时看到了我需要的正确属性,但我知道这不是我猜测的正确方式?
共有1个答案

1)
// connect to url and retrieve source code as document
Document doc = Jsoup
.connect(url)
.userAgent("Mozilla/5.0")
.referrer("http://www.google.com")
.get();
String md5= doc
// use CSS selector to grab only enums which contain md5
.select("div#file-details.extra-info > div.enum-container > div.enum:contains(md5)")
// use the first element in the result set
.first()
// use only its text node and ignore the text node of the span
.ownText();
2)有很多方法可以指定孩子。您可以使用 CSS 选择器或一些 jsoup 的便利方法。
如果我想从以下html中提取文本foo:
<html>
<body>
<div>
<span><b>foo</b></span>
<span><b>bar</b></span>
</div>
</body>
</html>
其中每一个都会产生相同的结果:
doc.select("div > span > b").last().ownText();
doc.select("div > span > b").get(1).ownText();
doc.select("div > span:last-child > b").text();
doc.select("div > span:last-child").text();
doc.select("div > span").last().text();
doc.select("div > span").get(1).text();
doc.select("div > span:last-child > b").first().ownText();
doc.select("span > b").last().text();
决定采用哪种方式实际上取决于您正在解析的文档的HTML结构。有关更多示例,请参见CSS选择器。
3)检查源代码,而不是浏览器中呈现的代码。杰苏普不调用脚本。如果页面的 DOM 在 OnLoad 上发生更改,则需要在解析页面之前呈现该页面。以下是如何执行此操作的示例:https://stackoverflow.com/a/38572859/1176178
-
在本章中,将学习如何访问XML文档的信息单元的XML DOM节点。 XML DOM的节点结构允许开发人员在树周围导航以查找特定信息并同时访问信息。 访问节点 以下是可以访问节点的三种方式 - 通过使用方法 通过循环遍历或遍历节点树 通过使用节点关系导航节点树 1. getElementsByTagName() 此方法允许通过指定节点名称来访问节点的信息。它还允许访问节点列表和节点列表长度的信息。
-
我正在运行laravel 5.4在Ubuntu 16.04服务器与PHP7。 我在本地版本的应用程序上安装此软件包没有问题。
-
我可以通过以下方式访问dev中的用户名: 有没有其他方法可以通过webdriver访问ShadowDOM元素?
-
问题内容: 是否可以使用Selenium / Chrome Webdriver访问Shadow DOM中的元素? 正如预期的那样,使用普通元素搜索方法不起作用。我已经在w3c上看到了对switchToSubTree规范的引用,但找不到任何实际的文档,示例等。 有人成功吗? 问题答案: 不幸的是,webdriver规范似乎还不支持此功能。 我的侦探被发现: http://www.w3.org/TR/
-
问题内容: 是用PHP生成的SVG对象。 一片空白。(因此,我无法通过JS访问svg的元素。)它应该可以工作,看看这个问题。我究竟做错了什么?如何获得SVG? 问题答案: 您需要等待SVG加载完毕,然后才能访问contentDocument:
-
我正在测试一个使用shadow dom的新应用程序,如下所示: 有人知道我如何访问文件选择器控件中的元素吗?特别是关闭图标?