
如何有效地计算Julia中的二次型?

我想计算一个二次形式:朱莉娅中的x'Q y。
对于这种情况,最有效的计算方法是什么:
- 没有假设
Q是对称的x和y是相同的(x=y)Q和x=y都是对称的
我知道朱莉娅有点()。但是我想知道它是否比BLAS呼叫更快。
共有3个答案

Julia的LinearAlgebra stdlib有3-参数点的本机实现,也是一个专门用于对称/厄米特矩阵的版本。您可以在这里和这里查看源代码。
您可以使用BenchmarkTools确认它们没有进行分配@b时间或基准工具@ballocated(记住使用$插入变量)。利用了矩阵的对称性,但从源代码看,我不知道x==y如何实现任何严重的加速,除了可能节省一些数组查找。
编辑:要比较BLAS版本和本机版本的执行速度,可以执行以下操作
1.7.0> using BenchmarkTools, LinearAlgebra
1.7.0> X = rand(100,100); y=rand(100);
1.7.0> @btime $y' * $X * $y
42.800 μs (1 allocation: 896 bytes)
1213.5489200642382
1.7.0> @btime dot($y, $X, $y)
1.540 μs (0 allocations: 0 bytes)
1213.548920064238
这是本机版本的一大胜利。对于较大的矩阵,情况会发生变化,不过:
1.7.0> X = rand(10000,10000); y=rand(10000);
1.7.0> @btime $y' * $X * $y
33.790 ms (2 allocations: 78.17 KiB)
1.2507105095988091e7
1.7.0> @btime dot($y, $X, $y)
44.849 ms (0 allocations: 0 bytes)
1.2507105095988117e7
可能是因为BLAS使用线程,而dot不是多线程的。还有一些浮点值的差异。

如果您的矩阵是对称的,请使用对称包装器来提高性能(然后调用不同的方法):
julia> a = rand(10000); b = rand(10000);
julia> x = rand(10000, 10000); x = (x + x') / 2;
julia> y = Symmetric(x);
julia> @btime dot($a, $x, $b);
47.000 ms (0 allocations: 0 bytes)
julia> @btime dot($a, $y, $b);
27.392 ms (0 allocations: 0 bytes)
如果x与y相同,请参见https://discourse.julialang.org/t/most-efficient-way-to-compute-a-quadratic-matrix-form/66606对于选项的讨论(但一般来说,dot仍然很快)。

现有的答案都是好的。但是,还有几点:
>
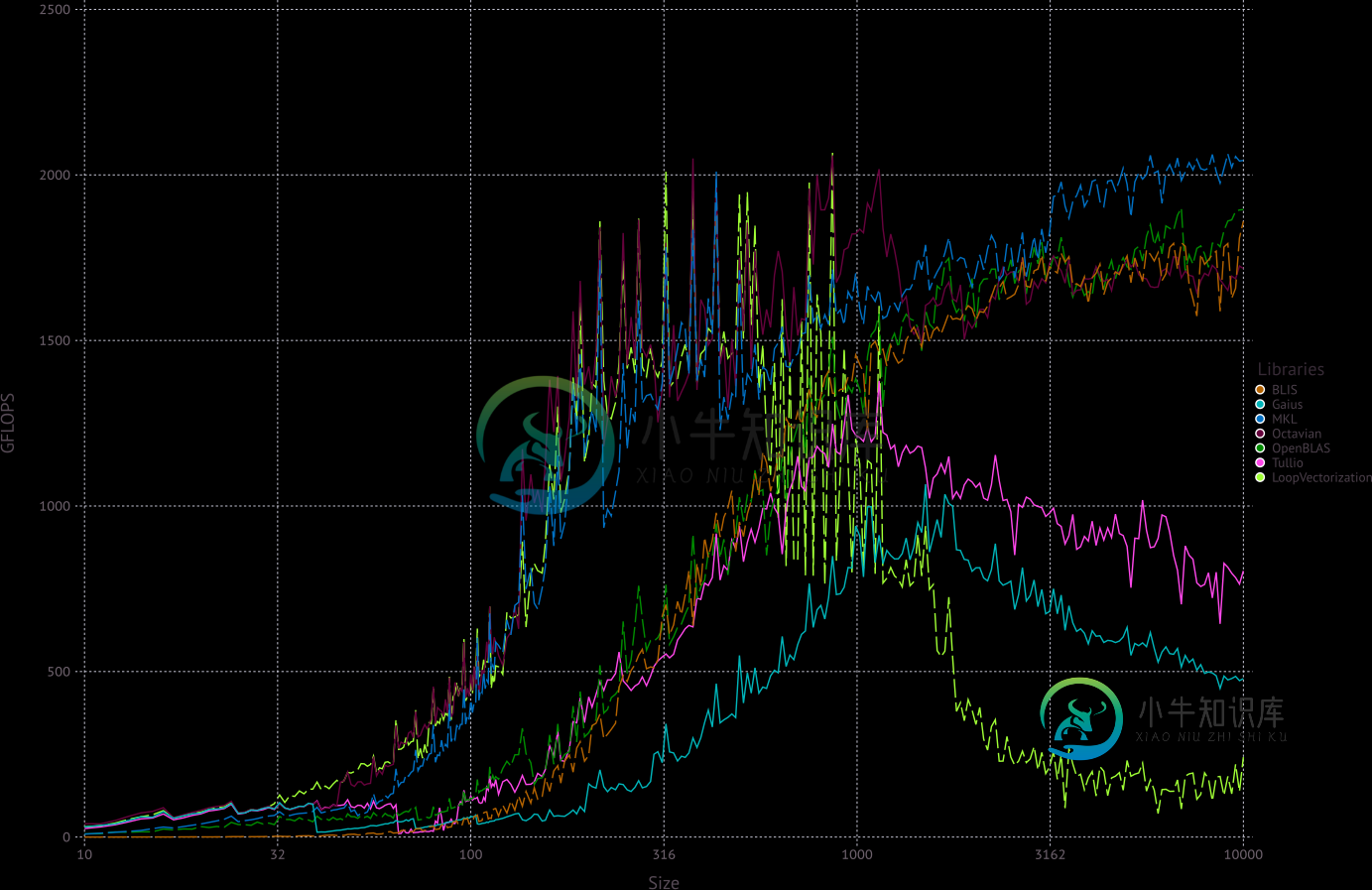
虽然朱莉娅在默认情况下确实会在这里简单地调用BLAS,正如奥斯卡所指出的,一些BLASes比其他的更快。特别是,在现代x86硬件上,MKL通常比OpenBLAS快一些。幸运的是,在Julia中手动选择BLAS后端非常容易。只需在Julia 1.7或更高版本的REPL上使用MKL键入,即可通过MKL. jl包切换到MKL后端。
虽然默认情况下不使用它,但现在确实存在两个纯Julia线性代数包,可以匹配甚至击败传统的基于Fortran的BLAS。尤其是屋大维。jl:
-
我想计算一个二次型:in Julia 在这些情况下,最有效的计算方法是什么: 没有假设 是对称的 和是相同的() 和都是对称的 我知道朱莉娅有。但是我想知道它是否比BLAS呼叫更快。
-
正如您所看到的,瓶颈是由3个循环给出的,这些循环使应用程序变慢;此外,对本体的每一类都执行计算分离过程。 是否有更有效的方法来获得不交点,并检查公理是否被断言或派生?
-
问题内容: 这是我目前的方式。有什么办法可以使用矩阵运算吗?X是数据点。 问题答案: 您是否要使用高斯核进行图像平滑?如果是这样,则scipy中有一个函数: 更新的答案 这应该可以工作- 尽管仍不能100%准确,但它会尝试考虑网格每个像元内的概率质量。我认为在每个像元的中点使用概率密度的准确性稍差,尤其是对于小内核。有关示例,请参见https://homepages.inf.ed.ac.uk/rb
-
问题内容: 计算对象的键/属性数量的最快方法是什么?是否可以在不迭代对象的情况下执行此操作?即不做 (Firefox确实提供了一个魔术属性,但是在版本4的某个位置将其删除。) 问题答案: 要在任何与 ES5兼容的环境 (例如Node,Chrome,IE 9+,Firefox 4+或Safari 5+)中执行此操作: 浏览器兼容性 Object.keys文档(包括可以添加到非ES5浏览器的方法)
-
问题内容: 假设我有以下由四行三列组成的2D numpy数组: 生成包含所有列之和的一维数组的有效方法是什么(如)?无需遍历所有列就能做到这一点吗? 问题答案: 请查看的文档,特别注意该参数。汇总列: 或者,总结行: 其他聚合函数一样,并且,例如,也采取了参数。 从暂定NumPy的教程: 许多一元运算(例如计算数组中所有元素的总和)都作为该类的方法实现。默认情况下,这些操作适用于数组,就好像它是数
-
问题内容: 我想计算一个文本文件中所有单词的频率。 如果目标文本文件如下所示,则应返回: 在一些帖子之后,我已经用纯python实现了它。但是,我发现由于巨大的文件大小(> 1GB),纯python方法是不够的。 我认为借用sklearn的能力是一个候选人。 如果让CountVectorizer为每一行计数频率,我想您将通过累加每一列来获得字频率。但是,这听起来有点间接。 用python计算文件中