
Julia中计算二次型的一种有效方法(最快)

我想计算一个二次型:x'qyin Julia
在这些情况下,最有效的计算方法是什么:
- 没有假设
Q是对称的x和y是相同的(x=y)Q和x=y都是对称的
我知道朱莉娅有点()。但是我想知道它是否比BLAS呼叫更快。
共有3个答案

这是一个BLAS电话。(您可以使用@edit来确认这一点)。

如果矩阵是对称的,则使用symmetric包装器来提高性能(然后调用另一种方法):
julia> a = rand(10000); b = rand(10000);
julia> x = rand(10000, 10000); x = (x + x') / 2;
julia> y = Symmetric(x);
julia> @btime dot($a, $x, $b);
47.000 ms (0 allocations: 0 bytes)
julia> @btime dot($a, $y, $b);
27.392 ms (0 allocations: 0 bytes)
如果x与y相同,请参见https://discourse.julialang.org/t/most-efficient-way-to-compute-a-quadratic-matrix-form/66606对于选项的讨论(但一般来说,dot仍然很快)。

现有的答案都是好的。但是,还有几点:
>
正如奥斯卡指出的那样,朱莉娅在默认情况下确实会在这里简单地调用BLAS,但有些BLAS比其他BLAS更快。特别是,在现代x86硬件上,MKL通常比OpenBLAS快一些。幸运的是,在Julia中,手动选择BLAS后端非常容易。在Julia 1.7或更高版本上的REPL上使用MKL只需键入,即可通过MKL切换到MKL后端。jl包。
虽然默认情况下不使用它,但现在确实存在两个纯Julia线性代数包,可以匹配甚至击败传统的基于Fortran的BLAS。尤其是屋大维。jl:
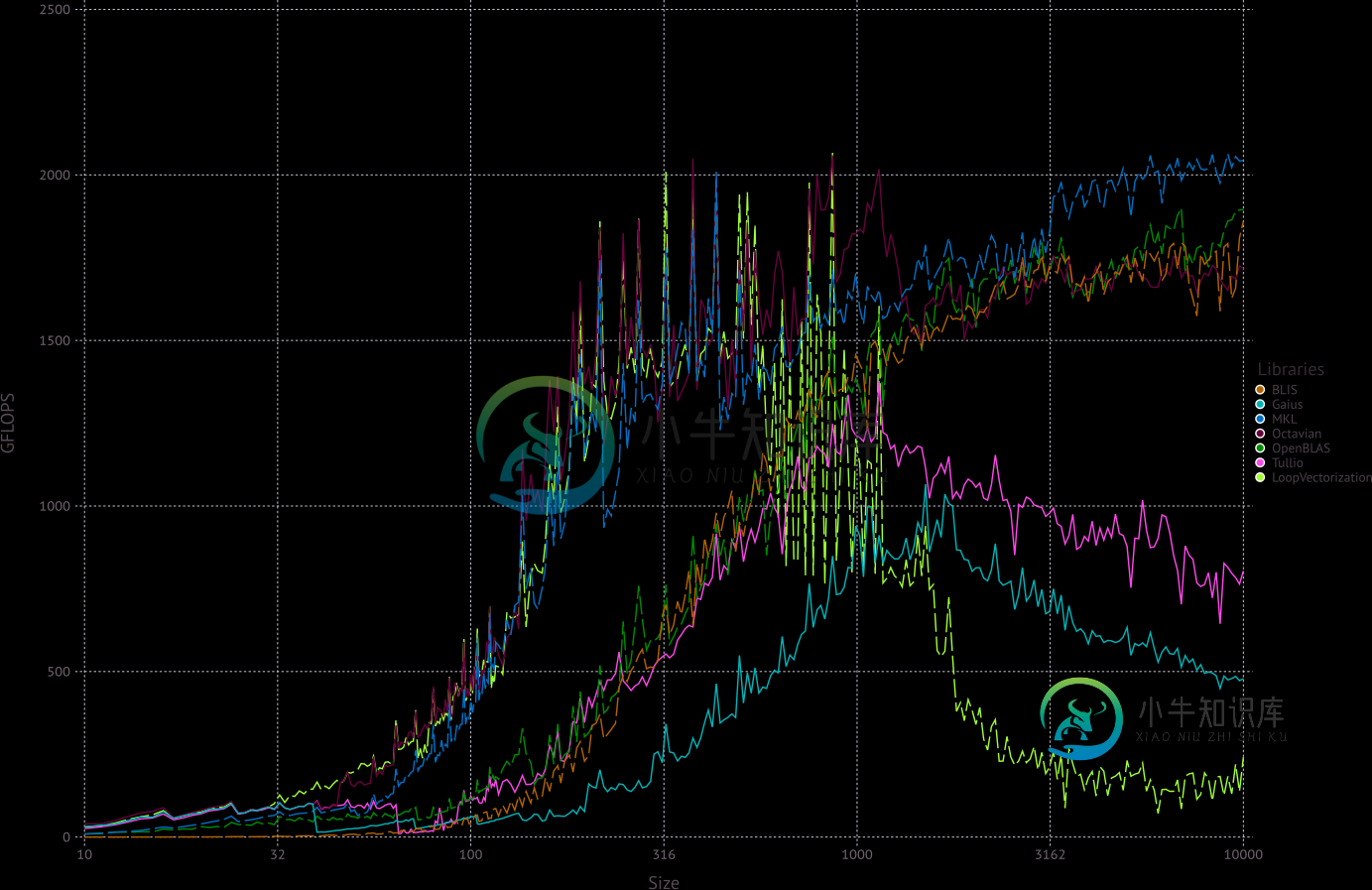
-
我想计算一个二次形式:朱莉娅中的。 对于这种情况,最有效的计算方法是什么: 没有假设 是对称的 和是相同的() 和都是对称的 我知道朱莉娅有。但是我想知道它是否比BLAS呼叫更快。
-
问题内容: 我正在使用Hibernate检索特定查询的行数。假设我有一个名为“ Person”的表,其中包含各种列。这些列之一是“名称”。 如果我想获得带有“安德鲁”名字的人数,以下哪种方法最有效?假设某些/全部之间存在性能差异。使用Hibernate / SQL是否有更好的方法? (1)选择所有列 (2)仅选择名称列 (3)在查询中使用Count (4)在查询中的名称列中使用Count 编辑:对
-
假设您有一个不断收到HTTP请求的服务器。您的老板需要一些统计数据,并要求您计算任何给定时间最后一分钟内的点击数。 你会用什么算法和数据结构来实现这个目标?
-
我需要使用这个设置计算CRC-64到这个精彩的网站:http://www.sunshine2k.de/coding/javascript/crc/crc_js.html 正如您所看到的,我需要“Input Reflected”,这意味着我需要颠倒任何字节的位顺序(有点烦人)。目前,我使用一个查找表(例如0x55->0xAA)实现了这一点,但我想知道CRC是否有任何属性可以用来提高效率。 这是我的代
-
下面是我的函数:
-
问题内容: 我有一个Python列表,我想知道在此列表中计算项目出现次数的最快方法。在我的实际情况下,该项目可能会发生数万次,这就是为什么我想要一种快速的方法。 哪种方法:或更优化? 问题答案: a = [‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘2’, ‘2’, ‘2’, ‘2’, ‘7’, ‘7’, ‘7’, ‘10’, ‘10’] print a.count(“1”) 它