
复制数据“存储连接”强制使用ADF中的blob存储,而不是ADLS Gen2

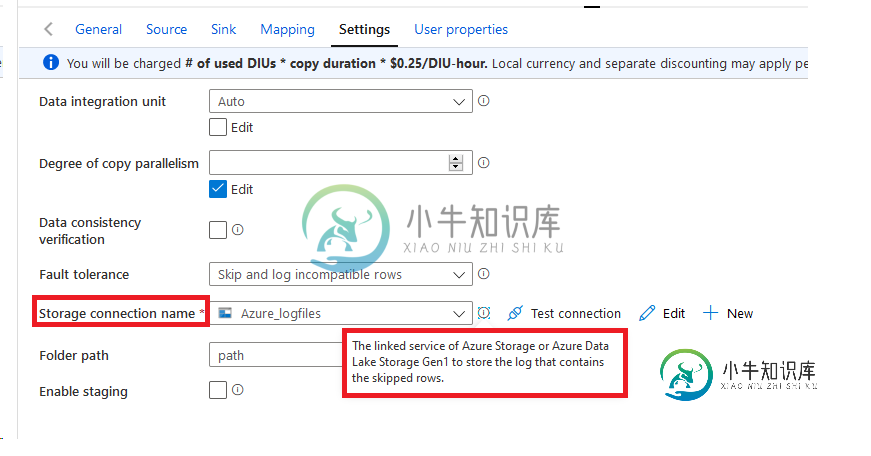
我有一个从ADLS Gen2输入的数据工厂(只有这在我们公司是兼容的)。它工作得很好。下图是“复制数据”活动的设置。如图中所示,存储日志(丢失的行数据)时,我们被迫使用blob存储或gen 1数据湖。我们如何使用ADLS Gen2进行此操作?看来是个瓶颈。如果此类数据存储在Gen2之外,我们将有自满的问题
共有1个答案

在我这边没问题,请尝试直接编辑您活动的定义json:
这是我的 json:
{
"name": "pipeline3",
"properties": {
"activities": [
{
"name": "Copy data1",
"type": "Copy",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "BinarySource",
"storeSettings": {
"type": "AzureBlobFSReadSettings",
"recursive": true
},
"formatSettings": {
"type": "BinaryReadSettings"
}
},
"sink": {
"type": "BinarySink",
"storeSettings": {
"type": "AzureBlobFSWriteSettings"
}
},
"enableStaging": false,
"logStorageSettings": {
"linkedServiceName": {
"referenceName": "AzureDataLakeStorage1",
"type": "LinkedServiceReference"
}
},
"validateDataConsistency": false
},
"inputs": [
{
"referenceName": "Binary1",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "Binary2",
"type": "DatasetReference"
}
]
}
],
"annotations": []
}
}
-
我试图将一个Azure Blob存储容器挂载到一个DataBricks实例上,虽然挂载确实有效,但它似乎没有使用存储容器。 我在这里漏掉了什么?
-
我正在从 Azure 数据工厂运行数据砖 python 活动。我想从 Azure blob 存储/数据湖中选择 python/shell 脚本,而不是 dbfs 路径。我目前的ADF数据砖蟒蛇活动不允许没有“dbfs:/”。 你能帮我一下吗?
-
我正在尝试使用Azure Blob存储。我成功上传了一些图像,但突然我得到了错误: 远程主机强制关闭了现有连接 我研究了一下,每当我试图检查Blob容器是否存在时,都会引发异常。 这是我的代码: BlobClient getter属性:(注意,我已将连接字符串中的敏感数据标记为**) 抛出异常的实际代码: 准确地说,异常发生在我检查容器是否存在的行。 我不知道怎么了。我确信连接字符串是正确的(我复
-
我想通过运行在Azure VM上的FTP服务器与用户共享Azure Blob存储中的文件。 据我所知,您不能在VM上挂载Blob存储,但可以使用“网络使用”挂载Azure文件共享。 Blob存储上的文件将以增量方式上载,因此理想情况下,我希望在上载时将其复制到Azure文件,Azure功能似乎是理想的方式,因为它们很容易为我设置和处理Blob存储上的触发器。 我如何使用Azure功能将文件从Blo
-
我上传图像使用平均堆栈和Multer模块 我可以从angular中检索图像,甚至可以将图像路径发布到Mongoose集合 问题是,我希望有一个图像数组,但在发布到mongoose时,它会将每个图像存储为一个新记录 图像模式 POST API 收藏已保存 如果我发布两张图像,它将按如下所示进行存储,但我希望两张图像都保存在同一记录中,即在内 ** ** 请帮忙。
-
我对block blob存储是如何工作的有点困惑,所以我对这些限制是如何工作的有点困惑(从我读到的内容来看,大多数人甚至不会接近这些限制,但我仍然想知道它是如何应用的)。我一直在读这篇文章 限制似乎是这样的 块BLOB存储文本和二进制数据,最多约4.7TB。块BLOB由可以单独管理的数据块组成。 或者block blob是否意味着如果我有img001并且它是1GB,它将被分离成块,并且限制为50,