
当另一个Excel工作表中满足条件时如何编写特定行[重复]

我正处于Java的学习阶段。我想用Java编写一个程序,它可以读取一个Excel文件(.xlsx)。此文件有一些列和许多行。我想将数据写入另一个Excel文件(.xlsx),仅满足条件,而不是现有文件中的所有数据。
我的Excel工作表如下所示
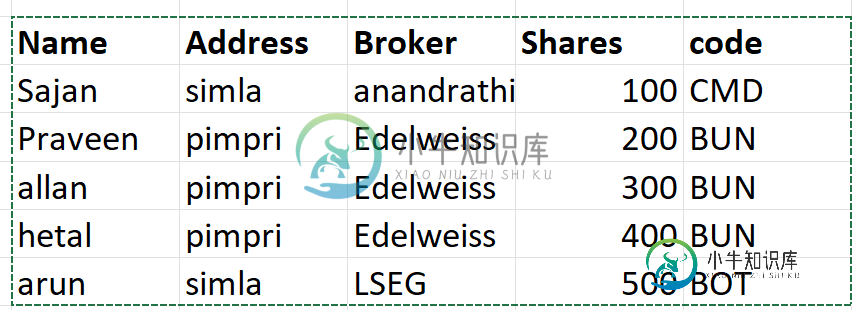
我想只过滤那些带有代理Edelweiss的行,并把它放在另一个Excel表中。我知道如何使用Java将一个Excel中的所有数据复制到另一个Excel中。不知道如何筛选出具体的一行,放到另一个Excel中。
这是我的代码。
FileInputStream file = new FileInputStream(new File("broker.xlsx"));
//Create Workbook instance holding reference to .xlsx file
XSSFWorkbook workbook = new XSSFWorkbook(file);
//Get first/desired sheet from the workbook
XSSFSheet sheet = workbook.getSheetAt(0);
//Iterate through each rows one by one
Iterator<Row> rowIterator = sheet.iterator();
while (rowIterator.hasNext())
{
Row row = rowIterator.next();
//For each row, iterate through all the columns
Iterator<Cell> cellIterator = row.cellIterator();
while (cellIterator.hasNext())
{
Cell cell = cellIterator.next();
//Check the cell type and format accordingly
switch (cell.getCellType())
{
case Cell.CELL_TYPE_NUMERIC:
System.out.print(cell.getNumericCellValue() + "t");
break;
case Cell.CELL_TYPE_STRING:
System.out.print(cell.getStringCellValue() + "t");
break;
}
}
System.out.println("");
}
file.close();
}
catch (Exception e)
{
e.printStackTrace();
}
当我运行Axel Richter的代码时,我得到了以下错误
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/io/output/UnsynchronizedByteArrayOutputStream
at org.apache.poi.poifs.filesystem.FileMagic.valueOf(FileMagic.java:209)
at org.apache.poi.ss.usermodel.WorkbookFactory.create(WorkbookFactory.java:222)
at org.apache.poi.ss.usermodel.WorkbookFactory.create(WorkbookFactory.java:185)
at writefile.main(writefile.java:92)
Caused by: java.lang.ClassNotFoundException: org.apache.commons.io.output.UnsynchronizedByteArrayOutputStream
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
我在我的类路径中包含以下 jar
POI_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/poi-5.2.2.jar
POI_OOXML_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/poi-ooxml-full-5.2.2.jar
XML_BEANS_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/ooxml-lib/xmlbeans-5.0.3.jar
COM_COLL_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/lib/commons-collections4-4.4.jar
COM_COMPRESS_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/ooxml-lib/commons-compress-1.21.jar
COM_CODEC_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/lib/commons-codec-1.15.jar
COM_IO_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/lib/commons-io-2.11.0.jar
COM_MATH_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/lib/commons-math3-3.6.1.jar
LOG_J4_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/lib/log4j-api-2.17.2.jar
SPARSE_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/lib/SparseBitSet-1.2.jar
COM_LOGG_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/ooxml-lib/commons-logging-1.2.jar
CURVE_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/ooxml-lib/curvesapi-1.07.jar
SLF4_LIB=$(TOP_DIR)/jar/poi-bin-5.2.2/ooxml-lib/slf4j-api-1.7.36.jar
共有1个答案
我将把我的评论作为答案。
我会打开源工作表并循环浏览其中的所有行。对于每一行,我将获得存储“Broker”的列的内容。然后,如果该内容等于“雪绒花”,我会将该行放入Java集合,例如一个行列表。之后,我会将Java集合的内容写入结果表。
以下完整示例对此进行了说明。
它包含获取工作表特殊列中最后填充的行和获取工作表特殊行中最后填充的列的方法。即确定工作表的使用单元格范围。
它还包含一个获取标题的方法,该方法将标题映射到列索引。标题必须位于工作表中已用单元格区域的第一行。
它还展示了如何使用CellUtil。copyCell可将单元格从一张图纸复制到另一张图纸。
该代码已经过测试,并使用当前的< code>apache poi 5.2.2运行。
<code>代理的第一页。xlsx看起来像:
代码:
import java.io.FileOutputStream;
import java.io.FileInputStream;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.ss.util.CellUtil;
import java.util.Locale;
import java.util.List;
import java.util.ArrayList;
import java.util.Map;
import java.util.HashMap;
class ExcelFilterRowsToNewWorkbook {
static int getLastFilledRow(Sheet sheet, int col) {
int lastStoredRowNum = sheet.getLastRowNum();
for (int r = lastStoredRowNum; r >= 0; r--) {
Row row = sheet.getRow(r);
if (row != null) {
Cell cell = row.getCell(col);
if (cell != null && cell.getCellType() != CellType.BLANK) return row.getRowNum();
}
}
return -1; // the sheet is empty in that col
}
static int getLastFilledColumn(Sheet sheet, int rowIdx) {
int lastStoredCellNum = sheet.getRow(rowIdx).getLastCellNum();
Row row = sheet.getRow(rowIdx);
if (row != null) {
for (int c = lastStoredCellNum; c >= 0; c--) {
Cell cell = row.getCell(c);
if (cell != null && cell.getCellType() != CellType.BLANK) return cell.getColumnIndex();
}
}
return -1; // the sheet is empty in that row
}
static Map<Integer, String> getHeadings(Sheet sheet) {
DataFormatter dataFormatter = new DataFormatter(new Locale("en", "US"));
dataFormatter.setUseCachedValuesForFormulaCells(true);
int firstRow = sheet.getFirstRowNum();
int firstCol = sheet.getRow(firstRow).getFirstCellNum();
int lastCol = getLastFilledColumn(sheet, firstRow);
Map<Integer, String> headings = new HashMap<Integer, String>();
Row row = sheet.getRow(firstRow);
if (row != null) {
for (int c = firstCol; c <= lastCol; c++) {
Cell cell = row.getCell(c);
headings.put(c, dataFormatter.formatCellValue(cell));
}
}
return headings;
}
static List<Row> filterRows(Sheet sheet, String filterHeading, String filterValue) {
int filterCol = -1;
Map<Integer, String> headings = getHeadings(sheet);
for (Map.Entry<Integer, String> entry : headings.entrySet()) {
if (entry.getValue().equals(filterHeading)) {
filterCol = entry.getKey();
break;
}
}
List<Row> rows = new ArrayList<Row>();
// add the headings row
int firstRow = sheet.getFirstRowNum();
rows.add(sheet.getRow(firstRow));
// add the fildered rows
if (filterCol > -1) {
DataFormatter dataFormatter = new DataFormatter(new Locale("en", "US"));
dataFormatter.setUseCachedValuesForFormulaCells(true);
int firstCol = sheet.getRow(firstRow).getFirstCellNum();
int lastCol = getLastFilledColumn(sheet, firstRow);
int lastRow = getLastFilledRow(sheet, firstCol);
for (int r = firstRow; r <= lastRow; r++) {
Row row = sheet.getRow(r);
if (row != null && lastCol >= filterCol) {
Cell cell = row.getCell(filterCol);
String cellContent = dataFormatter.formatCellValue(cell);
if (cellContent.equals(filterValue)) {
rows.add(row);
}
}
}
}
return rows;
}
public static void main(String[] args) throws Exception {
try (Workbook workbookSrc = WorkbookFactory.create(new FileInputStream("./broker.xlsx")) ) {
Sheet sheetSrc = workbookSrc.getSheetAt(0);
// get filtered rows
List<Row> rowsSrc = filterRows(sheetSrc, "Broker", "Edelweiss");
// add filtered rows in new workbook
try (Workbook workbookDest = WorkbookFactory.create(true);
FileOutputStream fileout = new FileOutputStream("./brokerFiltered.xlsx") ) {
Sheet sheetDest = workbookDest.createSheet();
int r = 0;
for (Row rowSrc : rowsSrc) {
Row rowDest = sheetDest.createRow(r++);
for (Cell cellSrc : rowSrc) {
Cell cellDest = rowDest.createCell(cellSrc.getColumnIndex());
CellUtil.copyCell(cellSrc,
cellDest,
new CellCopyPolicy(),
new CellCopyContext()
);
}
}
workbookDest.write(fileout);
}
}
}
}
< code>brokerFiltered.xlsx的第一页如下所示:
-
希望有人能帮我!我已经被困了一段时间了...提前谢谢! 在工作簿1中,如果Sheet1中的D列(起始行19及更高)等于“SOW”,则将整行复制到Sheet1工作簿2中的第一个可用行(第19行之后)。复制后,继续扫描D列中的项目以获取更多“SOW”实例。 背景-我正在尝试复制整行,因为我必须从A行复制该行:NL-大约有175行需要通过 下面是我尝试过的两个代码,但都没有用。他们基本上什么都不做,没有
-
我有一张包含两张纸的谷歌纸。一个("")在不同的日期标题下有一系列值(星期日、星期一、星期二......),每天都更新。因此,列标题中的日期每天都在变化,每个标题下的值也在变化。这两个表中的列都是,标题在每个表的第1行,值在第2行。在另一张表()中,是一周中的天数下的值的静态列表。 我想使用条件格式来突出显示中的值,如果它们高于中相应日期下的值。我知道使用函数来引用另一个工作表,并且可以编写一个自
-
对所有人,谢谢你提前的时间。 我们已经有了工作代码,可以在Excel中用vb将数据从一个wrksht移动到另一个wrksht。 如有任何帮助,我们将不胜感激。 2/22/19 以下是我的回应。 在第二个工作簿上,在第一列上进行搜索时,工作表称为orderlog 谢谢
-
我有一些预定的任务: 这就是我想要的样子。网络上有一些解决方案,但它们似乎都相当复杂,对我来说不太管用,而这似乎是一个相当常见的问题。
-
在编写实现类文件接口的类时,我们可以从模块继承一个抽象基类,例如,如图所示,使迭代器在Python中表现得像类文件对象。 另一方面,在类型注释中,我们应该使用从<code>类型派生的类。IO</code>(例如<code>TextIO</code>)表示这样的对象,如文件或类文件对象的类型提示所示?或io的类型检查问题。联合中的TextIOBase。 然而,这似乎并不像我预期的那样有效: 在这段代
-
如果可能请帮忙。多谢.