
浅谈pandas筛选出表中满足另一个表所有条件的数据方法

今天记录一下pandas筛选出一个表中满足另一个表中所有条件的数据。例如:
list1 结构:名字,ID,颜色,数量,类型。
list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']]
list2结构:名字,类型,颜色。
list2 = [['a','03',255],['a','06',481]]
如何在list1中找出所有与list2中匹配的元素?要得到下面的结果:list = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03']]。
首先将两个list转化为dataframe.
list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] df1=pd.DataFrame(list1,columns=["名字","ID","颜色","数量","类型"]) list2 = [['a','03',255],['a','06',481]] df2=pd.DataFrame(list2,columns=["名字","类型","颜色"])
数据结构如下:

然后利用pandas.merge函数将其进行内连接。
这个函数的语法是:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)。这函数连接方式和sql的连接类似,由参数how来控制。
最后的代码如下:
import pandas as pd list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] df1=pd.DataFrame(list1,columns=["名字","ID","颜色","数量","类型"]) list2 = [['a','03',255],['a','06',481]] df2=pd.DataFrame(list2,columns=["名字","类型","颜色"]) df=pd.merge(df1,df2,how='inner',on=["名字","类型","颜色"],right_index=True) df.sort_index(inplace=True) print(df)
返回结果按照左表的顺序输出:
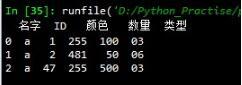
以上这篇浅谈pandas筛选出表中满足另一个表所有条件的数据方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
这似乎很简单,但我似乎无法理解。我知道如何将pandas数据帧过滤到满足条件的所有行,但当我想要相反的结果时,我总是会遇到奇怪的错误。 这是一个例子。(上下文:一个简单的棋盘游戏,棋子在网格上,我们试图给它一个坐标,并返回所有相邻的棋子,但不是实际坐标上的实际棋子) 我认为应该只是否定后面括号中的布尔值,但这似乎不是它的工作方式。 我想让它在5,6时归还母牛,而不是在5,7时归还狼(因为这是当前的
-
问题内容: 使用以下模型: 如果我要查找包含至少一篇文章的订单操作,则可以按预期工作: 但是,如果要查找订单中所有商品的订单操作,正确的方法是什么? 引发错误(我理解为什么会这样)。 问题答案: 一个简单的解决方案: 这只是一个查询,但每篇文章都有一个内部联接。对于多篇文章,Willem更巧妙的解决方案应该会表现更好。
-
问题内容: 我有2张桌子: 表: 表: 现在,我想获取所有位置并过滤两个属性: 我正在尝试构造一些查询,如下所示: …但是仍然无法得到我所需要的。 问题答案: 经过几个小时的合并和尝试,我终于做到了: 我太接近了,因此将所有过滤条件都移至。
-
我们知道在Spark中有三种类型的连接——广播连接、随机连接和排序合并连接: 当小表连接大表时,使用广播加入; 当小表大于广播加入阈值时,使用随机连接; 当大表连接,并且连接键可以排序时,使用排序-合并连接; 如果存在两个大表的连接并且无法对连接键进行排序,会发生什么情况?Spark 将选择哪种联接类型?
-
问题内容: 给定以下示例表架构 客户表 发票表 目的是选择InvoiceID值为10和20(非OR)的所有客户。因此,在此示例中,将返回带有CustID = 1和2的客户。 您将如何构造SELECT语句? 问题答案: 使用: 关键是需要计数等于子句中参数的数量。 的使用是在对帐务编号和发票编号的组合没有唯一约束的情况下- 如果没有重复的机会,则可以从查询中省略DISTINCT:
-
我有两个数据表 和 , 可能比 更大,列更多。我想在中选择两列DT1中的行,其中的两列在中两列的同一行中具有完全匹配项。例如 输出,,我正在寻找的是 我的问题是,当我试图子集时,我也会得到那些只有一列匹配的行 我可以用一个笨重的循环来获得我想要的输出, 但是我想知道是否有更智能的data.table版本。这可能很简单,但是我无法从中拼凑出来。