
在Azure DevOps中,是否有GUI方法来禁用基于YAML的管道中的任务?

使用经典发布管道,可以进入管道,进入一个阶段,并非常快速地启用/禁用该阶段内的任务
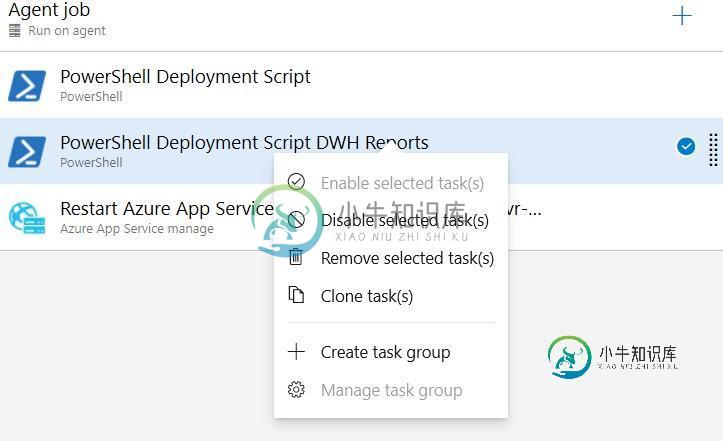
您将如何处理YAML管道?
共有3个答案

您不能从GUI真正做到这一点。好吧,你可以用#注释掉它们。在编辑部

现在,对于运行时参数,您有一个GUI选项。如果取消选中复选框(请参阅下面的图片),则可以将该参数传递给管道。
据我所知,有三种方法可以在任务中实现运行时参数,您也可以在作业/阶段中应用大多数逻辑(作业/阶段[当前]没有“已启用”属性除外);
parameters:
- name: RunTask
displayName: Run task?
type: boolean
default: true
steps:
- pwsh: Write-Host "always run this task"
- pwsh: Write-Host "skip this task when checkbox unticked..."
condition: eq(${{ parameters.RunTask }}, true)
- pwsh: Write-Host "skip this task when checkbox unticked..."
enabled: ${{ parameters.RunTask }}
- ${{ if eq(parameters.RunTask, true) }}:
- pwsh: Write-Host "skip this task when checkbox unticked..."

除了用#注释掉任务之外,这里我还提供了另一种解决方法:
您可以尝试设置变量:启用=false,然后在YAML文件中使用该变量。
steps:
- task: PublishSymbols@2
displayName: 'Publish symbols path'
inputs:
SearchPattern: '**\bin\**\*.pdb'
PublishSymbols: false
enabled: false
continueOnError: true
如果设置为这种方式,此任务将不会在作业中运行。
本例中提到了此方法,您可以参考它了解详细信息。
-
我是yaml的新手,我有一个关于用于多行的管道符号()的问题。YAML有类似下面的语法吗? 测试:6+ parser$ParserException:第17行,第12列:需要“block end”,但发现:block mapping start“。
-
我正在做一个关于kafka流和KTable的poc。我想知道是否有任何方法在kafka中存储数据(键-值对或键-对象对),或者通过流、KTable、状态存储,这样我就可以检索基于键和值的数据库。我创建了一个基于topic的kstream,在该kstream上推送了一些消息,并使用wordcountalgo在kstream上创建的ktable中填充了值。类似这样的事情: 我无法获取基于值的记录。 h
-
我想获取不同域下的网页,这意味着我必须在“scrapy crawl myspider”命令下使用不同的蜘蛛。然而,由于网页的内容不同,我不得不使用不同的管道逻辑将数据放入数据库。但是对于每个spider,它们都必须经过settings.py中定义的所有管道。是否有其他优雅的方法为每个卡盘使用单独的管道?
-
我已经在我的环境中配置了一个发布管道,作为开发- 我的问题是,是否有可能在各个阶段禁用手动部署,比如在测试阶段完成之前,我们不应该部署到uat。 现在,我们将能够手动运行uat阶段,即使开发和测试阶段没有完成或者我们还没有运行这些阶段。
-
问题内容: 我最近尝试使用一些基于浏览器的IDE,例如cloud9 IDE。但是它不直接支持对Java程序进行编码。而且我还读到我们需要遵循某些繁琐的过程来编写和编译Java代码。 是否有任何基于浏览器的IDE将允许我直接编码,编译和共享Java应用程序?另外,它是否支持Java Web应用程序? 问题答案: 它很小,但是http://ideone.com可以让您编译和共享基本Java程序。 我目
-
问题内容: 编辑:我改变了一些例子,以获得想法: 喜欢 …而无需创建公共接口并为Integer和Float创建子类来实现它 如果没有,类似这样的东西可能会更有意义并且有用 如果呢?是一个通配符,为什么我们不应该限制某些类型? 问题答案: 在非常极端的情况下(没有的Java 7之前的版本),我也希望能够做到这一点。例如 不管实际的类型是什么,这都允许我打电话。换句话说,将包含所有提供的类型的“ AP