
spark数据集覆盖spark 2.4中不工作的特定分区

在我的工作中,最后一步是将执行的数据存储在配置单元表中,分区位于“date”列。有时,由于作业失败,我需要单独为特定的分区重新运行作业。正如所观察到的,当我使用下面的代码时,spark会在使用覆盖模式时覆盖所有分区。
ds.write.partitionBy("date").mode("overwrite").saveAsTable("test.someTable")
在浏览了多个博客和stackoverflow之后,我按照以下步骤只覆盖特定的分区。
Step 1: Enbable dynamic partition for overwrite mode
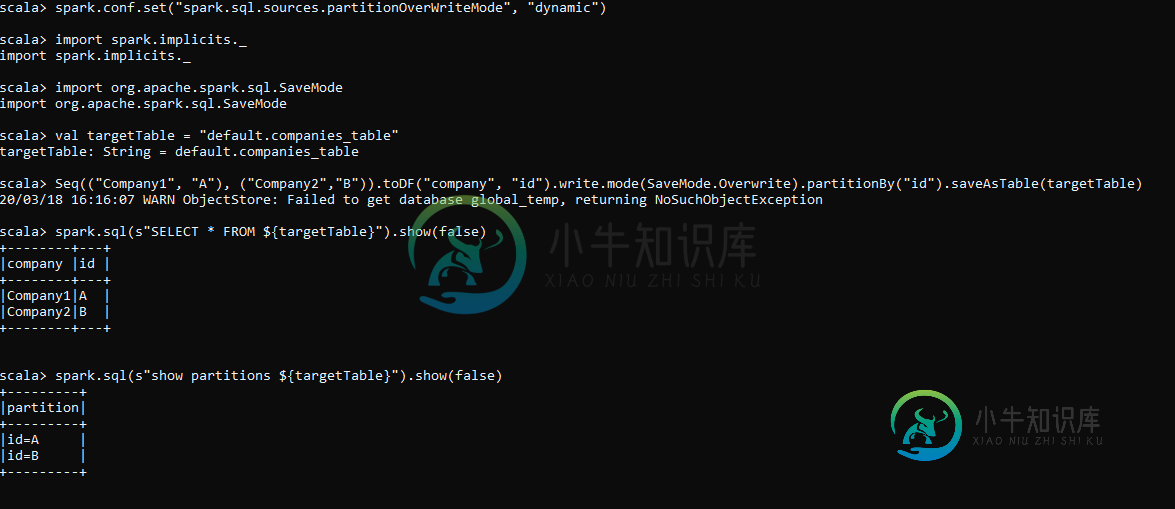
spark.conf.set("spark.sql.sources.partitionOverWriteMode", "dynamic")
Step 2: write dataframe to hive table using saveToTable
Seq(("Company1", "A"),
("Company2","B"))
.toDF("company", "id")
.write
.mode(SaveMode.Overwrite)
.partitionBy("id")
.saveAsTable(targetTable)
spark.sql(s"SELECT * FROM ${targetTable}").show(false)
spark.sql(s"show partitions ${targetTable}").show(false)
Seq(("CompanyA3", "A"))
.toDF("company", "id")
.write
.mode(SaveMode.Overwrite)
.insertInto(targetTable)
spark.sql(s"SELECT * FROM ${targetTable}").show(false)
spark.sql(s"show partitions ${targetTable}").show(false)
根据本博客https://www.waitingforcode.com/apache-spark-sql/html" target="_blank">apache-spark-sql-hive-insertinto-command/read,“insertinto”应该只覆盖特定的分区
如果我先创建表,然后使用“insertinto”方法,它工作得很好




我想知道,通过SaveToTable创建配置单元表和手动创建表有什么区别?为什么它在第一个场景中不起作用?有人能帮我吗?
共有1个答案

试着用小写W!
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
不是
spark.conf.set("spark.sql.sources.partitionOverWriteMode", "dynamic")
它愚弄了我。如果您查看,您的脚本中使用了两个变体。
-
我想覆盖特定的分区,而不是spark中的所有分区。我正在尝试以下命令: 其中df是具有要覆盖的增量数据的数据帧。 hdfs基本路径包含主数据。 当我尝试上述命令时,它会删除所有分区,并将df中存在的分区插入hdfs路径。 我的要求是只覆盖df中指定hdfs路径上的那些分区。有人能帮我一下吗?
-
我使用,但这给我带来了partitionBy和intsertInto不能同时使用的问题。
-
我仍然是python的新手,我已经尝试过这种方式覆盖txt文件上的一行 ''' 答案 =输入(“俄/秒/升/米:”) ''' 它会替换txt文件上的所有文本行,无论我想做什么,当我选择R时,它会写入txt文件的第一行,当我选择S时,它会写入txt文件的第三行 我现在已经尝试过了 ''' ''' 有人能告诉我正确的方向吗
-
我们有没有可能在Spark中先按一列分区,然后再按另一列聚类? 在我的例子中,我在一个有数百万行的表中有一个< code>month列和一个< code>cust_id列。我可以说,当我将数据帧保存到hive表中,以便根据月份将该表分区,并按< code>cust_id将该表聚类成50个文件吗? 忽略按< code>cust_id的聚类,这里有三个不同的选项 第一种情况和最后一种情况在 Spark
-
问题内容: 我有一个愚蠢的困惑,当我们重写父类方法时,此派生的重写方法是否仍保留父类方法的代码,或者这是我们可以定义的新方法? 问题答案: 阅读本文以使概念更清晰。http://docs.oracle.com/javase/tutorial/java/IandI/override.html 通常,当我们想要扩展超类的方法或想要更改完整的逻辑时,我们就会这样做。 例如: 超类具有使用冒泡排序的排序方