
FactoryFinder性能/缓存不良

我有一个相当大的java ee应用程序,它有一个巨大的类路径来执行大量的xml处理。目前,我正试图通过取样探查器来加速我的一些功能和定位缓慢的代码路径。
我注意到的一件事是,特别是我们的代码中有transformerfactory.newinstance(...)等调用的部分非常慢。我一直跟踪到FactoryFinder方法FindServiceProvider,总是创建一个新的ServiceLoader实例。在ServiceLoaderjavadoc中,我找到了关于缓存的以下说明:
提供程序是懒惰地定位和实例化的,即按需提供。服务加载器维护到目前为止已加载的提供程序的缓存。迭代器方法的每次调用都返回一个迭代器,该迭代器首先按实例化顺序生成缓存的所有元素,然后缓慢地定位和实例化任何剩余的提供程序,依次将每个提供程序添加到缓存中。可以通过reload方法清除缓存。
private static <T> T findServiceProvider(final Class<T> type)
throws TransformerFactoryConfigurationError
{
try {
return AccessController.doPrivileged(new PrivilegedAction<T>() {
public T run() {
final ServiceLoader<T> serviceLoader = ServiceLoader.load(type);
final Iterator<T> iterator = serviceLoader.iterator();
if (iterator.hasNext()) {
return iterator.next();
} else {
return null;
}
}
});
} catch(ServiceConfigurationError e) {
...
}
}
对FindServiceProvider的每次调用都调用ServiceLoader.load。这每次都会创建一个新的ServiceLoader。这样看来根本没有使用ServiceLoaders缓存机制。每个调用都会扫描类路径以查找所请求的ServiceProvider。
我已经试过了:
- 我知道您可以设置像
javax.xml.transform.transformerFactory这样的系统属性来指定特定的实现。这样,FactoryFinder就不使用ServiceLoader进程和它的超快。可悲的是,这是一个jvm范围的属性,并且会影响在我的jvm中运行的其他java进程。例如,我的应用程序随附Saxon,应该使用com.saxonica.config.EnterpriseTransformerFactory。一旦设置了system属性,我的另一个应用程序就无法启动,因为它的类路径上没有com.saxonica.config.EnterpriseTransformerFactory。所以这似乎不是我的选择。 - 我已经重构了调用
TransformerFactory.newInstance并缓存TransformerFactory的每个位置。但是在我的依赖项中有许多地方我不能重构代码。
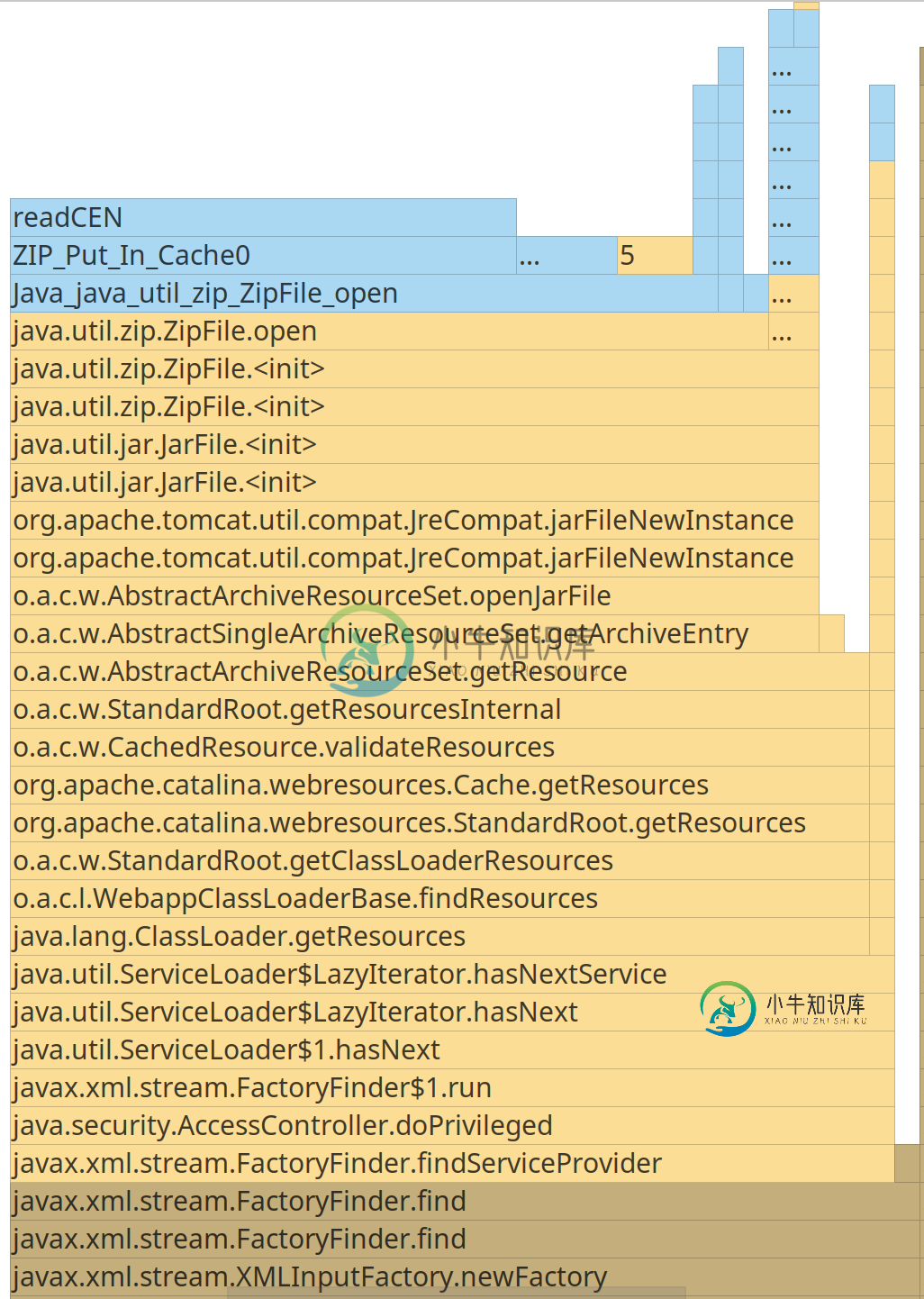
在serviceLoaders$lazyiterator.hasnextService中使用了大部分资源。此方法调用ClassLoader上的GetResources来读取META-INF/services/javax.xml.stream.xmlinputFactory文件。仅这个电话每次就需要大约35毫秒。
是否有一种方法可以指示Tomcat更好地缓存这些文件,以便更快地提供服务?
共有1个答案

35毫秒听起来像是涉及到磁盘访问时间,这指出了OS缓存的问题。
如果类路径上有任何目录/非JAR条目会减慢速度。另外,如果资源不存在于第一个被选中的位置。
ClassLoader.getResource可以被重写,如果您可以通过配置设置线程上下文类加载器(我已经很多年没有接触tomcat了),或者只是thread.SetContextClassLoader。
-
我必须使用StackExhange.redis C#在redis缓存中频繁添加N个(独立的)项,每个项都有不同的过期时间,以便在客户端有最小的时间,在服务器端有最小的阻塞和成本。Redis服务器每秒将收到数百个get请求,所以我不想打乱get时间。 我已经阅读了这里的文档并在这里回答。我找不到一个执行此操作的方法。考虑到不同的选择: null
-
ES 内针对不同阶段,设计有不同的缓存。以此提升数据检索时的响应性能。主要包括节点层面的 filter cache 和分片层面的 request cache。下面分别讲述。 filter cache ES 的 query DSL 在 2.0 版本之前分为 query 和 filter 两种,很多检索语法,是同时存在 query 和 filter 里的。比如最常用的 term、prefix、rang
-
如果我试图缓存一个巨大的(例如:100GB表),当我对缓存的执行查询时,它会执行全表扫描吗?火花将如何索引数据。火花留档说: Spark SQL可以通过调用Spark,使用内存中的列格式缓存表。目录cacheTable(“tableName”)或dataFrame。缓存()。然后Spark SQL将只扫描所需的列,并将自动调整压缩以最小化内存使用和GC压力。你可以打电话给spark。目录uncac
-
在本章中,我们将了解Grav中的性能和缓存概念。 表现(Performance) 术语“性能”指的是系统性能,使其能够处理更高的系统负载并修改系统以处理更高的负载。 考虑以下与Grav表现有关的要点 - 要获得更好的opcache性能,可以使用PHP opcache和usercache 。 opcache适用于PHP 5.4,使用PHP 5.5,PHP 5.6和Zend opcache可以更快地运
-
问题内容: 运行时,我看到了一系列的 硬件缓存事件 ,如下所示: 这些事件似乎大多基于测试返回合理的值,但是我想知道如何确定将这些事件映射到系统上的硬件性能计数器事件? 也就是说,这些事件肯定是在Skylake CPU上使用一个或多个基础x86 PMU计数器实现的-但是我怎么知道哪个? 您可以查找其他硬件事件,但不能查找“硬件缓存事件”。 问题答案: 用户@Margaret指出注释中的合理答案-阅
-
问题内容: 我正在用numpy编写一些中等性能的代码。该代码将位于计算的最内层循环中,其运行时间以小时为单位。快速计算表明,在计算的某些变化中,此代码将被执行大约10 ^ 12次。 因此,函数是计算sigmoid(X),另一个函数是计算其导数(梯度)。Sigmoid具有以下特性:对于 y = sigmoid(x),dy / dx = y(1-y) 在numpy的python中,它看起来像: 可以看