
pyspark,在大型RDD中寻找最大值?

我想出了四种方法来解决这个问题,但没有一种方法真正适用于大型RDD,我希望有人能帮助我。
我有一个格式为((x,y),(sim,sim ')的火花RDD,其中x和y是两个索引,sim和sim '是x和y的两个不同的相似性度量。我有兴趣寻找具有最大sim '值的元组。我想出了一些方法来做到这一点,但每种方法都有其问题,最终这些方法都不能应用于大规模的RDD,如10亿元组的RDD。
假设res_dict是((x,y),(sim,sim '))元组的RDD,在pyspark中调用< code>res_dict.collect()时,返回< code >[(0,4),(0.84482865216358305,-0.15517134783641684),(0,5),(0.814141945629517345,-0实际上,初始res_dict要大得多,它经历(n-1)次迭代,并且在每次迭代中,res_dict中的元组数量减少多达(n-ite)。n是初始res_dict中的元组总数,ite是当前迭代的索引,ite=1,....,n-1。
方法1:
res_dict最初由 .repartition(k) 划分为 n 个分区,(k
def f(iterator): yield max(iterator, key = lambda d:d[1][1])
max_list = res_dict.mapPartitions(f)
i_j_sim = max_list.max(key = lambda d:d[1][1])
随着res_dict的大小在每次迭代中减小,显然需要动态决定其分区数,否则将出现空分区并导致错误。所以在传递上面的代码之前,我查找了当前迭代中 res_dict 的非空分区数,并用这个数字重新分区res_dict:
def numNonEmptyPar(anRDD):
par_ind_size = anRDD.mapPartitionsWithIndex(length)
numNonEmp = par_ind_size.filter(lambda d: d[1] != 0).map(lambda x:1).reduce(add) # reduce is quite slow
return numNonEmp
numNonEmpar = numNonEmptyPar(res_dict)
if numNonEmpar < resPar:
resPar = numNonEmpar
res_dict = res_dict.repartition(resPar)
在我看来,.repartition() 不能保证每个分区都是非空的(.coalesce() 也不是)。那么如何使方法 1 起作用呢?
方法2:
i_j_sim = res_dict.glom().
\map(lambda ls : None if len(ls)==0 else max(ls, key=lambda d:d[1][1])).
\filter(lambda d: d!= None).max(lambda d:d[1][1]) # pyspark built-in func: rdd.max()
方法三:
i_j_sim = res_dict.max(key=lambda d: d[1][1])
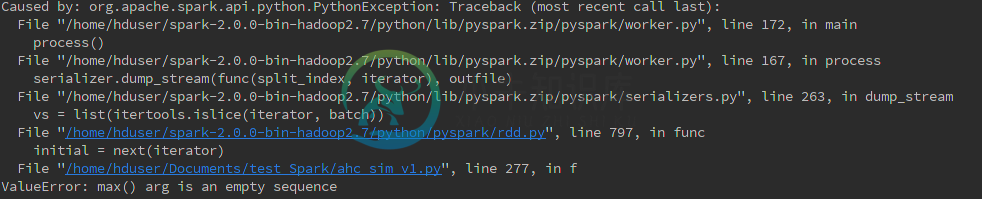
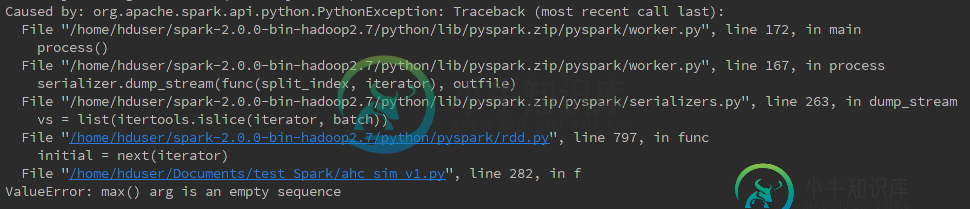
对于方法 2 和方法 3,看起来 max(lambda d:d[1][1]) 是问题所在。我观察到他们为10000个元组的res_dict工作,但对10亿个元组不起作用。所以rdd.max()应该只用一个小的rdd喂食吗?
PS:方法3的完整追溯是
ssh://hduser@159.84.139.244:22/usr/bin/python -u /home/hduser/Documents/test_Spark/ahc_sim_v1.py
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
16/10/14 14:47:30 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[Stage 5:==>(23 + 4) / 32][Stage 6:> (0 + 12) / 32][Stage 8:> (0 + 0) / 32]16/10/14 14:48:30 WARN TaskSetManager: Lost task 4.0 in stage 6.0 (TID 68, 159.84.139.245): java.io.StreamCorruptedException: invalid stream header: 12018301
at java.io.ObjectInputStream.readStreamHeader(ObjectInputStream.java:804)
at java.io.ObjectInputStream.<init>(ObjectInputStream.java:299)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.<init>(JavaSerializer.scala:63)
at org.apache.spark.serializer.JavaDeserializationStream.<init>(JavaSerializer.scala:63)
at org.apache.spark.serializer.JavaSerializerInstance.deserializeStream(JavaSerializer.scala:122)
at org.apache.spark.serializer.SerializerManager.dataDeserializeStream(SerializerManager.scala:146)
at org.apache.spark.storage.BlockManager$$anonfun$getRemoteValues$1.apply(BlockManager.scala:524)
at org.apache.spark.storage.BlockManager$$anonfun$getRemoteValues$1.apply(BlockManager.scala:522)
at scala.Option.map(Option.scala:146)
at org.apache.spark.storage.BlockManager.getRemoteValues(BlockManager.scala:522)
at org.apache.spark.storage.BlockManager.get(BlockManager.scala:609)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:661)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:281)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:63)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.api.python.PairwiseRDD.compute(PythonRDD.scala:390)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:79)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:47)
at org.apache.spark.scheduler.Task.run(Task.scala:85)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:274)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
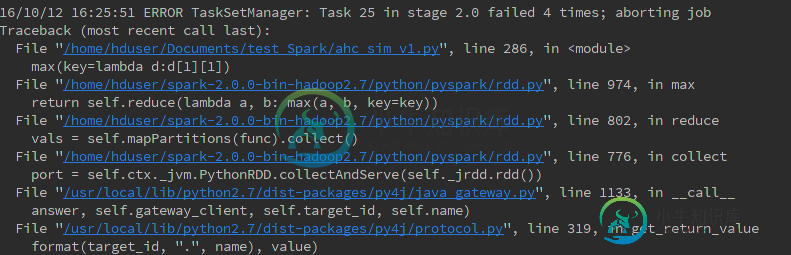
[Stage 5:==>(24 + 4) / 32][Stage 6:> (0 + 12) / 32][Stage 8:> (0 + 0) / 32]16/10/14 14:48:31 ERROR TaskSetManager: Task 10 in stage 6.0 failed 4 times; aborting job
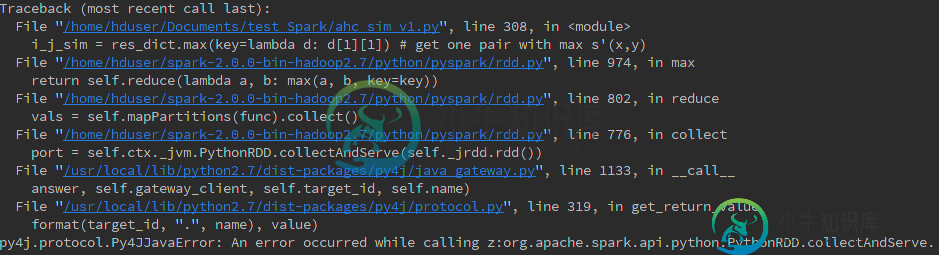
Traceback (most recent call last):
File "/home/hduser/Documents/test_Spark/ahc_sim_v1.py", line 320, in <module>
i_j_sim = res_dict.max(key=lambda d: d[1][1]) # get one pair with max s'(x,y)
File "/home/hduser/spark-2.0.0-bin-hadoop2.7/python/pyspark/rdd.py", line 974, in max
return self.reduce(lambda a, b: max(a, b, key=key))
File "/home/hduser/spark-2.0.0-bin-hadoop2.7/python/pyspark/rdd.py", line 802, in reduce
vals = self.mapPartitions(func).collect()
File "/home/hduser/spark-2.0.0-bin-hadoop2.7/python/pyspark/rdd.py", line 776, in collect
port = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd())
File "/usr/local/lib/python2.7/dist-packages/py4j/java_gateway.py", line 1133, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "/usr/local/lib/python2.7/dist-packages/py4j/protocol.py", line 319, in get_return_value
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 10 in stage 6.0 failed 4 times, most recent failure: Lost task 10.3 in stage 6.0 (TID 101, 159.84.139.247): java.io.StreamCorruptedException: invalid stream header: 12018301
at java.io.ObjectInputStream.readStreamHeader(ObjectInputStream.java:804)
at java.io.ObjectInputStream.<init>(ObjectInputStream.java:299)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.<init>(JavaSerializer.scala:63)
at org.apache.spark.serializer.JavaDeserializationStream.<init>(JavaSerializer.scala:63)
at org.apache.spark.serializer.JavaSerializerInstance.deserializeStream(JavaSerializer.scala:122)
at org.apache.spark.serializer.SerializerManager.dataDeserializeStream(SerializerManager.scala:146)
at org.apache.spark.storage.BlockManager$$anonfun$getRemoteValues$1.apply(BlockManager.scala:524)
at org.apache.spark.storage.BlockManager$$anonfun$getRemoteValues$1.apply(BlockManager.scala:522)
at scala.Option.map(Option.scala:146)
at org.apache.spark.storage.BlockManager.getRemoteValues(BlockManager.scala:522)
at org.apache.spark.storage.BlockManager.get(BlockManager.scala:609)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:661)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:281)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:63)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.api.python.PairwiseRDD.compute(PythonRDD.scala:390)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:79)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:47)
at org.apache.spark.scheduler.Task.run(Task.scala:85)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:274)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1450)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1438)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1437)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1437)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:811)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:811)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:811)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1659)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1618)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1607)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:632)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1871)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1884)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1897)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1911)
at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:893)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:358)
at org.apache.spark.rdd.RDD.collect(RDD.scala:892)
at org.apache.spark.api.python.PythonRDD$.collectAndServe(PythonRDD.scala:453)
at org.apache.spark.api.python.PythonRDD.collectAndServe(PythonRDD.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:237)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:280)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:128)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:211)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.io.StreamCorruptedException: invalid stream header: 12018301
at java.io.ObjectInputStream.readStreamHeader(ObjectInputStream.java:804)
at java.io.ObjectInputStream.<init>(ObjectInputStream.java:299)
at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.<init>(JavaSerializer.scala:63)
at org.apache.spark.serializer.JavaDeserializationStream.<init>(JavaSerializer.scala:63)
at org.apache.spark.serializer.JavaSerializerInstance.deserializeStream(JavaSerializer.scala:122)
at org.apache.spark.serializer.SerializerManager.dataDeserializeStream(SerializerManager.scala:146)
at org.apache.spark.storage.BlockManager$$anonfun$getRemoteValues$1.apply(BlockManager.scala:524)
at org.apache.spark.storage.BlockManager$$anonfun$getRemoteValues$1.apply(BlockManager.scala:522)
at scala.Option.map(Option.scala:146)
at org.apache.spark.storage.BlockManager.getRemoteValues(BlockManager.scala:522)
at org.apache.spark.storage.BlockManager.get(BlockManager.scala:609)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:661)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:281)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:63)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.api.python.PairwiseRDD.compute(PythonRDD.scala:390)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:319)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:79)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:47)
at org.apache.spark.scheduler.Task.run(Task.scala:85)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:274)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
... 1 more
Process finished with exit code 1
方法四:
max_sim_pr = res_dict.values().values().treeReduce(lambda a,b: max(a,b))
i_j_sim = res_dict.filter(lambda d:d[1][1] == max_sim_pr).first()

似乎对于方法2、3和4,真正的问题发生在.减少()上,但我不知道为什么,也不知道如何解决它。
共有1个答案

我发现了问题。错误是因为我没有相同的火花默认值。conf文件。在我将这个conf文件的内容与集群中的每个节点保持一致之后,结果证明方法2、3和4工作正常。但方法1不起作用,在我看来,rdd。repartition()无法确保分区是非空的,即使此rdd中的元素数大于分区数。我还注意到.repartition()需要大量的洗牌,所以我改为.colease(),它在我的测试中运行得更快。
-
我有一个RDD[标签点],我想找到标签的最小值和最大值,并应用一些转换,例如从所有这些标签中减去数字5。问题是我已经尝试了各种方法来获取标签,但没有任何工作正常。 如何仅访问 RDD 的标签和功能?有没有办法将它们作为列表[双精度]和列表[向量]例如? 我无法转到数据帧。
-
我想找出面积最大的国家。 我的数据集如下 有人能帮我写mapreduce程序吗? 我的映射器和缩减器代码如下 制图员 减速机
-
我有一个熊猫数据框,有两列,一列是温度,另一列是时间。 我想做第三和第四列,叫做最小和最大。这些列中的每一个都将填充nan's,除非有一个局部min或max,那么它将具有该极值的值。 这里是一个数据的样本,本质上我试图识别图中所有的峰值和低点。 有没有内置的熊猫工具可以做到这一点?
-
本文向大家介绍寻找一数组中前K个最大的数相关面试题,主要包含被问及寻找一数组中前K个最大的数时的应答技巧和注意事项,需要的朋友参考一下 考察点:数组
-
是否可以在MongoDB中找到最大的文档大小? 显示的是平均大小,这并不具有代表性,因为在我的例子中,大小可能会有很大差异。