
将DataFrame写入Parquet或Delta似乎没有并行化-耗时太长

问题陈述
我已将分区的 CSV 文件读入 Spark 数据帧。
为了利用Delta表的改进,我尝试将其作为Delta导出到Azure Data Lake Storage Gen2内的一个目录中。我在Databricks笔记本中使用以下代码:
%scala
df_nyc_taxi.write.partitionBy("year", "month").format("delta").save("/mnt/delta/")
整个数据帧大约有160 GB。
硬件规格
我正在使用具有12个内核和42 GB RAM的集群运行此代码。
然而,看起来整个写作过程都由Spark/Database ricks顺序处理,例如非并行方式:
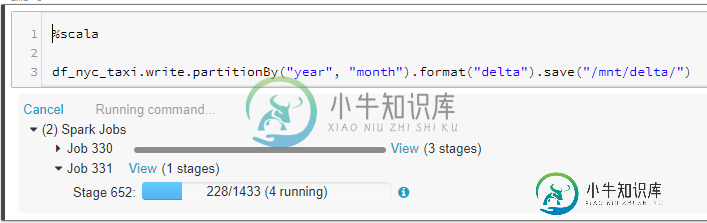
DAG 可视化效果如下所示:
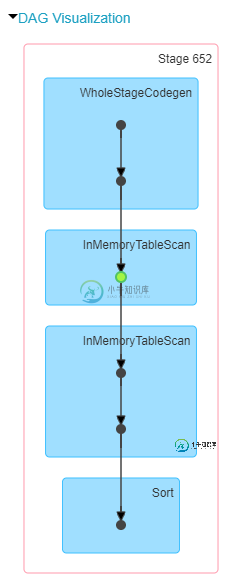
总而言之,这看起来需要1-2个小时才能执行。
问题
- 有没有办法让Spark并行写入不同的分区?
- 可能是问题在于我尝试将增量表直接写入 Azure 数据湖存储吗?
共有2个答案

这与另一个答案类似,但是,我在重新分区后添加了一个持久化
from pyspark.sql import functions as F
df_nyc_taxi.repartition(1250,F.col("year"), col("month"))\
.persist(StorageLevel.MEMORY_AND_DISK).write.partitionBy("year", "month")\
.format("delta").save("/mnt/delta/")

要跟进@eliasah的评论,也许你可以试试这个:
import org.apache.spark.sql.functions
df_nyc_taxi.repartition(col("year"), col("month"), lit(rand() * 200)).write.partitionBy("year", "month").format("delta").save("/mnt/delta/")
@eliasah的回答很有可能是每个目录只创建一个文件“/mnt/delta/year=XX/month=XX”,每个文件只由一个工人写数据。额外的列将进一步分割数据(在这种情况下,我将每个原始文件中的数据分成200个更小的分区,如果愿意,您可以编辑它),以便更多的工作人员可以并发写入。
附言:对不起,我还没有足够的代表来评论:'D
-
我正在使用从JSON事件流转换而来的Dataframes处理事件,这些数据流最终被写为Parquet格式。 但是,有些JSON事件在键中包含空格,我希望在将数据帧转换为Parquet之前记录并过滤/删除这些事件,因为被认为是Parquet模式(CatalystSchemaConverter)中的特殊字符,如下面[1]所列,因此列名中不应允许。 我如何在Dataframe中对列名进行这样的验证,并在
-
问题内容: 如何在不设置集群计算基础架构(例如Hadoop或Spark)的情况下,将大小适中的Parquet数据集读取到内存中的Pandas DataFrame中?我只想在笔记本电脑上使用简单的Python脚本在内存中读取这些数据,但是数量很少。数据不驻留在HDFS上。它位于本地文件系统上,也可能位于S3中。我不想启动并配置其他服务,例如Hadoop,Hive或Spark。 我以为Blaze /
-
如何在不设置集群计算基础设施(如Hadoop或Spark)的情况下将大小适中的Parket数据集读取到内存中的Pandas DataFrame中?这只是我想在笔记本电脑上使用简单的Python脚本在内存中读取的适度数据。数据不驻留在HDFS上。它要么在本地文件系统上,要么可能在S3中。我不想启动和配置其他服务,如Hadoop、Hive或Spark。 我原以为Blaze/Odo会使这成为可能:Odo
-
问题内容: 我正在使用下面的代码将43列和大约2,000,000行的DataFrame写入SQL Server的表中: 不幸的是,尽管它确实适用于小型DataFrame,但它要么非常慢,要么对于大型DataFrame超时。关于如何优化它的任何提示? 我尝试设置 谢谢。 问题答案: 我们求助于使用azure-sqldb-spark库,而不是使用Spark的默认内置导出功能。这个库给你一个这是一个方法
-
df.write.format(“delta”).mode(“append”).save(“ ”) 目前,这个表上没有分区,这可能是一个可能的修复,但在沿着这条路线前进之前,我是否遗漏了一些关于如何并行地获得不冲突的插入的东西?
-
问题内容: 您好,感谢您的宝贵时间和考虑。我正在Google Cloud Platform / Datalab中开发Jupyter Notebook。我创建了一个Pandas DataFrame,并希望将此数据框架同时写入Google Cloud Storage(GCS)和/或BigQuery。我在GCS中有一个存储区,并通过以下代码创建了以下对象: 我已经尝试过基于Google Datalab文