
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。
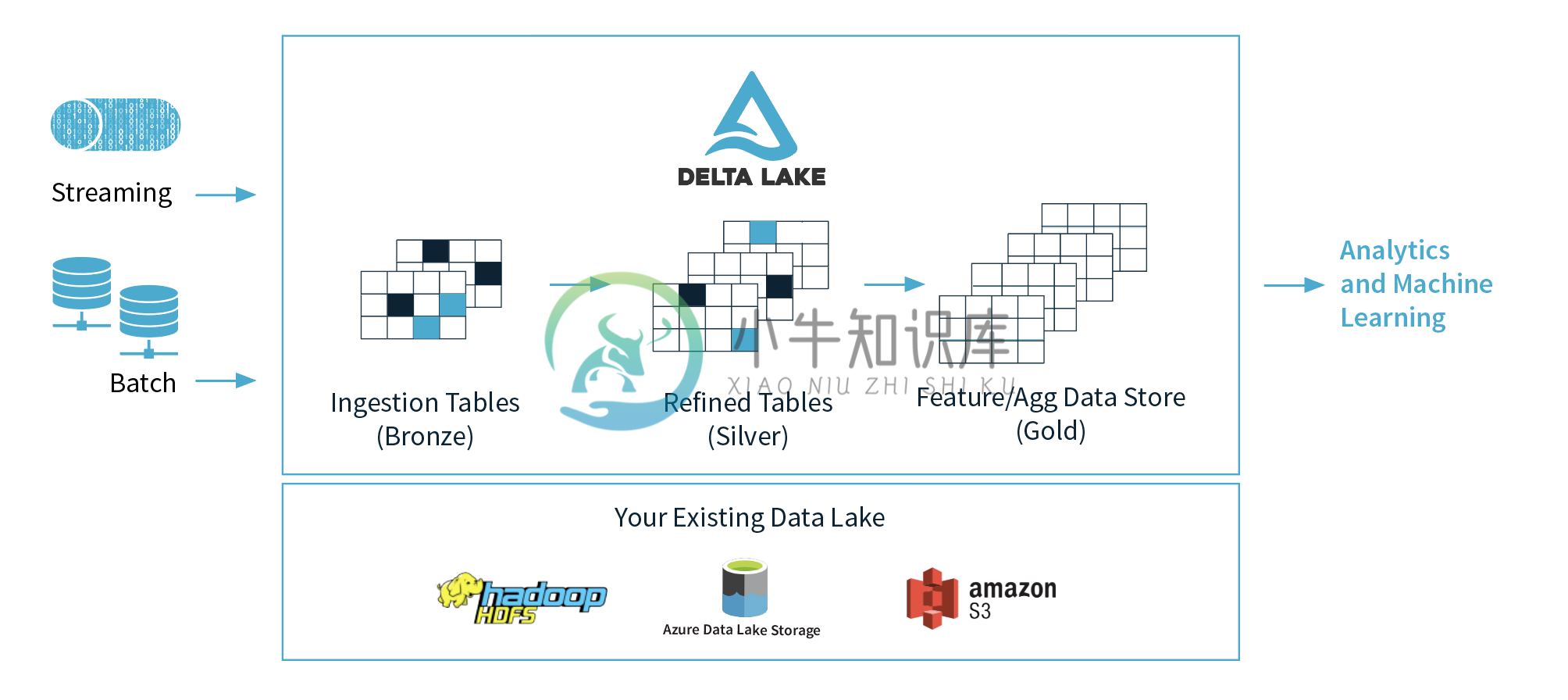
Delta Lake 还提供内置数据版本控制,以便轻松回滚。
主要功能特性
支持 ACID 事务
Delta Lake 在多并发写入之间提供 ACID 事务保证。每次写入都是一个事务,并且在事务日志中记录了写入的序列顺序。事务日志跟踪文件级别的写入并使用乐观并发控制,这非常适合数据湖,因为多次写入/修改相同的文件很少发生。在存在冲突的情况下,Delta Lake 会抛出并发修改异常以便用户能够处理它们并重试其作业。Delta Lake 还提供强大的可序列化隔离级别,允许工程师持续写入目录或表,并允许消费者继续从同一目录或表中读取。读者将看到阅读开始时存在的最新快照。
模式管理(Schema management)
Delta Lake 自动验证正在被写的 DataFrame 模式是否与表的模式兼容。表中存在但不在 DataFrame 中的列设置为 null。如果 DataFrame 有表中不存在的列,则此操作会引发异常。Delta Lake 具有显式添加新列的 DDL 以及自动更新模式的能力。
可扩展元数据处理
Delta Lake 将表或目录的元数据信息存储在事务日志中,而不是 Metastore 中。这允许 Delta Lake 在恒定时间内列出大型目录中的文件,同时在读取数据时非常高效。
数据版本
Delta Lake 允许用户读取表或目录之前的快照。当文件被修改文件时,Delta Lake 会创建较新版本的文件并保留旧版本的文件。当用户想要读取旧版本的表或目录时,他们可以在 Apache Spark 的读取 API 中提供时间戳或版本号,Delta Lake 根据事务日志中的信息构建该时间戳或版本的完整快照。这允许用户重现之前的数据,并在需要时将表还原为旧版本的数据。
统一流和批处理 Sink
除批量写入外,Delta Lake 还可用作 Apache Spark structured streaming 的高效流式 sink。结合 ACID 事务和可扩展的元数据处理,高效的流式 sink 现在可以实现大量近实时分析用例,而无需同时维护复杂的流式传输和批处理管道。
数据存储格式采用开源的
Delta Lake 中的所有数据都是使用 Apache Parquet 格式存储,使 Delta Lake 能够利用 Parquet 原生的高效压缩和编码方案。
记录更新和删除
这个功能马上可以使用。Delta Lake 将支持 merge, update 和 delete 等 DML 命令。这使得数据工程师可以轻松地在数据湖中插入/更新和删除记录。 由于 Delta Lake 以文件级粒度跟踪和修改数据,因此它比读取和覆盖整个分区或表更有效。
数据异常处理
Delta Lake 还将支持新的 API 来设置表或目录的数据异常。工程师能够设置一个布尔条件并调整报警阈值以处理数据异常。当 Apache Spark 作业写入表或目录时,Delta Lake 将自动验证记录,当数据存在异常时,它将根据提供的设置来处理记录。
100% 兼容 Apache Spark API
这点非常重要。开发人员可以将 Delta Lake 与他们现有的数据管道一起使用,仅需要做一些细微的修改。比如我们之前将处理结果保存成 Parquet 文件,如果想使用 Delta Lake 仅仅需要做如下修改:

参考:过往记忆大数据
-
Delta Lake 概论 读者交流群已经开通了,有需要的可以私信进入读者交流群 开始之前请参考前面的文章 数仓建模—实时数仓架构发展史 数仓建模—数仓架构发展史 数据存储层遇到的一些问题 早先基于Hive的数仓或者传统的文件存储形式(比如Parquet/ORC),都存在一些长期难以解决的问题: 小文件的问题 并发读写问题 有限的更新支持 海量元数据(例如分区)导致Hive metastore不堪
-
Delta lake 与湖仓一体 数据湖提供了一个完整的、权威的数据存储,可以赋能数据分析、商业智能和机器学习。 什么是数据湖 数据湖是以原始格式保存大量数据的集中式存储位置。与分层数据仓库(将数据存储在文件或文件夹中)相比,数据湖使用扁平体系结构和对象存储来存储数据。 对象存储存储储数据的时候会存储数据的据元数据标记和唯一标识符,这使得跨区域查找和检索数据更加容易,并提高了性能。通过利用廉价的
-
Delta Lake与实时计算 前面我们已经花了大量的篇幅在介绍Delta Lake,而且我们介绍了多种场景中去使用Delta Lake,你可以参考下面的文章 Spark SQL Scala版 使用 Delta Lake Spark SQL Shell 版 使用Delta Lake Spark SQL SQL 版 使用 Delta Lake Spark SQL Python版 使用 Delta L
-
Delta Lake 简介 Delta Lake是一个可靠的开源存储层,它提供ACID事务,可伸缩的元数据处理,并支持流/批统一。Delta Lake可以运行在现有数据湖之上,并完全和Apache Spark APIs兼容 Delta Lake 具体提供如下特性: Spark上的ACID事务:可序列化的隔离级别确保Reader永远看不到不一致的数据; 可扩展的元数据处理:利用Spark的分布式处理
-
Delta Lake 并发控制 Delta Lake 提供了读写之间ACID 的语义保证,这意味着: 对于支持的存储系统,跨多个集群的多个写入可以同时修改表分区并查看表的一致快照视图,并且这些写入有串行顺序。 读取可以继续看到 Apache Spark 作业开始时使用的表的一致快照视图,即使在作业期间修改了表也是如此。 乐观并发控制 Delta Lake 使用乐观并发控制来提供写入之间的事务保证。
-
Delta Lake 安装 下载并安装spark2.4.5版本 https://mirror.bit.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz 这里我用于测试,随便选了一个版本,你可以去官网选择你自己的版本。 第二步:spark-shell使用Delta0.5 导入了jar包,就能运行了,必须注意版本问题 bin/s
-
Spark SQL 使用 Delta Lake 读者交流群已经开通了,有需要的可以私信进入读者交流群 前面我们介绍过了 Delta Lake可以解决我们数据更新和小文件合并的问题,我们知道数据湖三驾马车的特性如下: Iceberg 的设计初衷更倾向于定义一个标准、开放且通用的数据组织格式,同时屏蔽底层数据存储格式上的差异,向上提供统一的操作 API,使得不同的引擎可以通过其提供的 API 接入;
-
Delta Lake 版本管理 前面我们在学习Delta Lake 时间旅行的时候已经提到过这个版本管理了,但是我们没有深入探究,其实版本管理这个概念并不陌生,我们知道我们用的git 就是一个开源的分布式版本控制系统,还有就是我们的业务系统数据库也经常做按照时间的快照备份,其实这也是版本的一种。 Delta Lake 版本管理与时间旅行 Delta Lake 版本管理的原理也是Delta Lake
-
问题内容: 我需要存储一个2d矩阵,其中包含邮政编码以及每个邮政编码之间的距离(以km为单位)。我的客户有一个计算距离的应用程序,然后将其存储在Excel文件中。目前,有952个地方。因此,矩阵将具有952x952 = 906304条目。 我试图将其映射到HashMap [Integer,Float]。整数是两个字符串在两个位置(例如“ A”和“ B”)的哈希码。浮点值是它们之间的距离(以公里为单
-
主要内容:1.大数据生态技术,2.数据存储,3.数据存储的发展,4.数据存储的方式1.大数据生态技术 数据存储处理: 清洗, 关联, 规范化, 组织建模, 通过数据质量的检测, 数据分析然后提供相应的数据服务 离线数仓: 实时数仓: 以Kafka, cancal/Maxwell/FlinkCdc为区分, 离线数仓为Hive, Sqoop 实时数仓:分层: Ods, Dwd, Dim, Dwm, Dws, Ads 离线数仓分层: Ods. Dwd, Dws, Dwt, Ads 实
-
问题内容: 前言:前几天,我在考虑为新应用程序使用新的数据库结构,并意识到我们需要一种有效地存储历史数据的方法。我想让其他人看一看,看看这种结构是否有任何问题。我意识到这种存储数据的方法很可能以前就已经发明了(我几乎可以肯定已经有了),但是我不知道它是否有名称,并且我尝试过的一些Google搜索都没有产生任何结果。 问题:假设您有一个订单表,并且订单与下订单的客户的客户表相关。在正常的数据库结构中
-
问题内容: 在我们的项目中,我们使用ELK堆栈将日志存储在集中位置。但是,我注意到,ElasticSearch的最新版本支持各种聚合。此外,Kibana 4支持不错的图形方式来构建图形。现在,即使是最新版本的grafana也可以与Elastic Search 2数据源一起使用。 因此,这是否意味着ELK堆栈现在可以用于存储系统内部收集的计量信息,还是不能认为它是现有解决方案(石墨,流入db等)的重
-
我正在寻找一种安全的方式来存储用户的敏感媒体像驾照图片。据我所知,没有办法从Firebase存储规则访问Firebase实时数据库,以查看用户是否被授权查看媒体。如果我错了就纠正我。文档中有一些允许某些用户访问介质的方法,但这对我来说并不可行,因为可能有多个用户将访问介质,并且他们的权限状态可能在将来更改。 null
-
数据存储 Cookie 浏览器中的 Cookie 是指小型文本文件,通常在 4KB 大小左右。(由键值对构成用 ; 隔开)大部分时候是在服务器端对 Cookie 进行设置,在头文件中 Set-Cookie 来对 Cookie 进行设置。 页面可以访问当前页的 Cookie 也可以访问父域的 Cookie。 属性 属性 默认值 作用 Name(必填) 名 Value(必填) 值 Domain 当前文
-
前端数据存储工具 YDN-DB forerunner AlaSQL LokiJS lovefiled Dexie.js localForage pouchdb
-
问题内容: 我正在开发一个J2ME应用程序,该应用程序具有要存储在设备上的大量数据(大约1MB,但是可变)。我不能依靠文件系统,所以我卡住了记录管理系统(RMS),该系统允许多个记录存储,但每个记录存储空间都有限。我最初的目标平台Blackberry将每个限制为64KB。 我想知道是否还有其他人必须解决在RMS中存储大量数据的问题,以及他们如何进行管理?我正在考虑必须计算记录大小并在多个存储区中拆