
从包含在shapefile边界内的netcdf文件中提取数据

我有以下形状文件和 netcdf 文件。
我想从netcdf文件中提取包含在shapefile边界内的数据。
你对我如何做到这一点有什么建议吗?
形状文件对应于SREX区域11北欧(NEU),netcdf文件是CMIP6气候模型数据输出(UA变量)的示例。我想要的输出必须是 netcdf 格式。
更新
到目前为止,我尝试使用NCL和数位长创建一个netcdf掩码,并将此掩码应用于原始netcdf数据集。以下是步骤(和NCL脚本):
#################
## remove plev dimension from netcdf file
cdo --reduce_dim -copy nc_file.nc nc_file2.nc
## convert longitude to -180, 180
cdo sellonlatbox,-180,180,-90,90 nc_file2.nc nc_file3.nc
## create mask
ncl create_nc_mask.ncl
## apply mask
cdo div nc_file3.nc shape1_mask.nc nc_file4.nc
#################
输出几乎是正确的。见下图。但是形状文件的南部边界(SREX 11,NEU)未正确捕获。所以我想生成 netcdf 掩码的 NCL 脚本有问题。
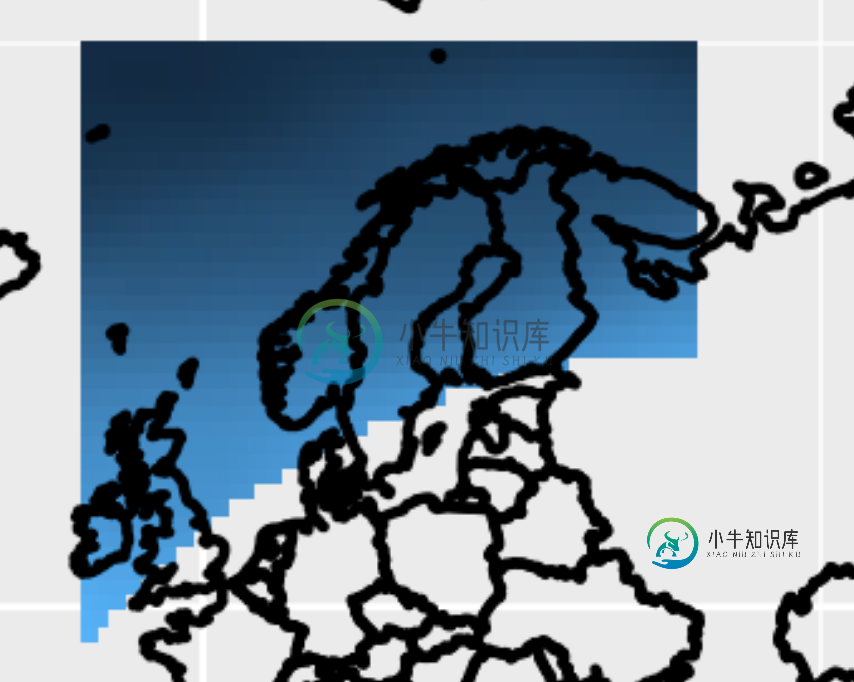
共有2个答案

到目前为止,我想出了这个(我知道这不是完整的解决方案):
1) 要打开shapefile和nc文件,需要安装两个包:
pip3 install pyshp
pip3 install netCDF4
2)然后这是你如何在python中导入它们:
import shapefile
from netCDF4 import Dataset
3)从shapefile读取数据:
with shapefile.Reader("shape1.dbf") as dbf:
print(f'{dbf}\n')
print(f'bounding box: {dbf.bbox}')
shapes = dbf.shapes()
print(f'points: {shapes[0].points}')
print(f'parts: {shapes[0].parts}')
print(f'fields: {dbf.fields}')
records = dbf.records()
dct = records[0].as_dict()
print(f'record: {dct}')
这将为您提供以下输出:
shapefile Reader
1 shapes (type 'POLYGON')
1 records (4 fields)
bounding box: [-10.0, 48.0, 40.0, 75.0]
points: [(-10.0, 48.0), (-10.0, 75.0), (40.0, 75.0), (40.0, 61.3), (-10.0, 48.0)]
parts: [0]
fields: [('DeletionFlag', 'C', 1, 0), ['NAME', 'C', 40, 0], ['LAB', 'C', 40, 0], ['USAGE', 'C', 40, 0]]
record: {'NAME': 'North Europe [NEU:11]', 'LAB': 'NEU', 'USAGE': 'land'}
4) 读取 nc 文件:
nc_fdata = Dataset('nc_file.nc', 'r')
5) 使用此辅助功能查看里面的内容:
def ncdump(nc_fid, verb=True):
def print_ncattr(key):
try:
print("\t\ttype:", repr(nc_fid.variables[key].dtype))
for ncattr in nc_fid.variables[key].ncattrs():
print('\t\t%s:' % ncattr, repr(nc_fid.variables[key].getncattr(ncattr)))
except KeyError:
print("\t\tWARNING: %s does not contain variable attributes" % key)
# NetCDF global attributes
nc_attrs = nc_fid.ncattrs()
if verb:
print("NetCDF Global Attributes:")
for nc_attr in nc_attrs:
print('\t%s:' % nc_attr, repr(nc_fid.getncattr(nc_attr)))
nc_dims = [dim for dim in nc_fid.dimensions] # list of nc dimensions
# Dimension shape information.
if verb:
print("NetCDF dimension information:")
for dim in nc_dims:
print("\tName:", dim)
print("\t\tsize:", len(nc_fid.dimensions[dim]))
print_ncattr(dim)
# Variable information.
nc_vars = [var for var in nc_fid.variables] # list of nc variables
if verb:
print("NetCDF variable information:")
for var in nc_vars:
if var not in nc_dims:
print('\tName:', var)
print("\t\tdimensions:", nc_fid.variables[var].dimensions)
print("\t\tsize:", nc_fid.variables[var].size)
print_ncattr(var)
return nc_attrs, nc_dims, nc_vars
nc_attrs, nc_dims, nc_vars = ncdump(nc_fdata)
我猜您将需要名为“ua”的变量,因为它具有经度和纬度地址等。
因此,为了构建遮罩,您必须从“ua”中提取所有内容,其中经度和纬度位于形状文件的边界框值之间。

重新使用一些旧的脚本/代码,我很快就想出了Python解决方案。它基本上只是在所有网格点上循环,并检查每个网格点是在形状文件中的多边形内部还是外部。结果是变量<code>mask</code>(带有<code>True/False</code>的数组),它可以用于屏蔽NetCDF变量。
注意:这使用Numba(所有<code>@jit</code>行)来加速代码,尽管在本例中这不是真正必要的。如果你没有Numba,你可以直接评论出来。
import matplotlib.pyplot as pl
import netCDF4 as nc4
import numpy as np
import fiona
from numba import jit
@jit(nopython=True, nogil=True)
def distance(x1, y1, x2, y2):
"""
Calculate distance from (x1,y1) to (x2,y2)
"""
return ((x1-x2)**2 + (y1-y2)**2)**0.5
@jit(nopython=True, nogil=True)
def point_is_on_line(x, y, x1, y1, x2, y2):
"""
Check whether point (x,y) is on line (x1,y1) to (x2,y2)
"""
d1 = distance(x, y, x1, y1)
d2 = distance(x, y, x2, y2)
d3 = distance(x1, y1, x2, y2)
eps = 1e-12
return np.abs((d1+d2)-d3) < eps
@jit(nopython=True, nogil=True)
def is_left(xp, yp, x0, y0, x1, y1):
"""
Check whether point (xp,yp) is left of line segment ((x0,y0) to (x1,y1))
returns: >0 if left of line, 0 if on line, <0 if right of line
"""
return (x1-x0) * (yp-y0) - (xp-x0) * (y1-y0)
@jit(nopython=True, nogil=True)
def is_inside(xp, yp, x_set, y_set, size):
"""
Given location (xp,yp) and set of line segments (x_set, y_set), determine
whether (xp,yp) is inside polygon.
"""
# First simple check on bounds
if (xp < x_set.min() or xp > x_set.max() or yp < y_set.min() or yp > y_set.max()):
return False
wn = 0
for i in range(size-1):
# Second check: see if point exactly on line segment:
if point_is_on_line(xp, yp, x_set[i], y_set[i], x_set[i+1], y_set[i+1]):
return False
# Calculate winding number
if (y_set[i] <= yp):
if (y_set[i+1] > yp):
if (is_left(xp, yp, x_set[i], y_set[i], x_set[i+1], y_set[i+1]) > 0):
wn += 1
else:
if (y_set[i+1] <= yp):
if (is_left(xp, yp, x_set[i], y_set[i], x_set[i+1], y_set[i+1]) < 0):
wn -= 1
if wn == 0:
return False
else:
return True
@jit(nopython=True, nogil=True)
def calc_mask(mask, lon, lat, shp_lon, shp_lat):
"""
Calculate mask of grid points which are inside `shp_lon, shp_lat`
"""
for j in range(lat.size):
for i in range(lon.size):
if is_inside(lon[i], lat[j], shp_lon, shp_lat, shp_lon.size):
mask[j,i] = True
if __name__ == '__main__':
# Selection of time and level:
time = 0
plev = 0
# Read NetCDF variables, shifting the longitudes
# from 0-360 to -180,180, like the shape file:
nc = nc4.Dataset('nc_file.nc')
nc_lon = nc.variables['lon'][:]-180.
nc_lat = nc.variables['lat'][:]
nc_ua = nc.variables['ua'][time,plev,:,:]
# Read shapefile and first feature
fc = fiona.open("shape1.shp")
feature = next(iter(fc))
# Extract array of lat/lon coordinates:
coords = feature['geometry']['coordinates'][0]
shp_lon = np.array(coords)[:,0]
shp_lat = np.array(coords)[:,1]
# Calculate mask
mask = np.zeros_like(nc_ua, dtype=bool)
calc_mask(mask, nc_lon, nc_lat, shp_lon, shp_lat)
# Mask the data array
nc_ua_masked = np.ma.masked_where(~mask, nc_ua)
# Plot!
pl.figure(figsize=(8,4))
pl.subplot(121)
pl.pcolormesh(nc_lon, nc_lat, nc_ua, vmin=-40, vmax=105)
pl.xlim(-20, 50)
pl.ylim(40, 80)
pl.subplot(122)
pl.pcolormesh(nc_lon, nc_lat, nc_ua_masked, vmin=-40, vmax=105)
pl.xlim(-20, 50)
pl.ylim(40, 80)
pl.tight_layout()
编辑
要将掩码写入NetCDF,可以使用以下方法:
nc_out = nc4.Dataset('mask.nc', 'w')
nc_out.createDimension('lon', nc_lon.size)
nc_out.createDimension('lat', nc_lat.size)
nc_mask_out = nc_out.createVariable('mask', 'i2', ('lat','lon'))
nc_lon_out = nc_out.createVariable('lon', 'f8', ('lon'))
nc_lat_out = nc_out.createVariable('lat', 'f8', ('lat'))
nc_mask_out[:,:] = mask[:,:] # Or ~mask to reverse it
nc_lon_out[:] = nc_lon[:] # With +180 if needed
nc_lat_out[:] = nc_lat[:]
nc_out.close()
-
我有海洋pH、o2等的全球4D NetCDF文件。每个文件有1个变量和4个维度(时间、经度、纬度和深度)。我希望从不包含NA的每个单元格的最底部深度提取数据。我尝试使用带有负超实验室的NCO的nks: 但是,这只为我提供了最深的箱(即-5700米深度箱)的数据,输出了海洋中所有较浅区域的NaN。有没有办法以类似的方式提取数据,但指定我想要每个单元格最深的非 NaN 值? 我能够使用 R、CDO 或
-
我有许多坐标(大约20000),我需要从许多NetCDF文件中提取数据,每个文件大约有30000个时间步(未来的气候场景)。使用这里的解决方案效率不高,原因是每个i,j将“dsloc”转换为“dataframe”所花费的时间(请看下面的代码)。**可以从这里下载NetCDF文件示例** 结果是: 这意味着每个i、j需要大约9秒来处理。考虑到大量的坐标和netcdf文件以及大量的时间步长,我想知道是
-
我有一个R代码,它从单个. nc4文件中提取每个月的每日值。我有49个netcdf文件。我想使用循环从所有这些文件中提取数据并将它们写入唯一的csv文件中。 我有一个文件的代码,但我需要多个文件的帮助。
-
我有一个 netCDF 文件,我希望使用 R 中的“ncdf”包从由纬度/经度边界定义的子集(即经纬度/经度定义的框)中提取子集。 下面是我的netCDF文件的摘要。它有两个维度(纬度和经度)和一个变量(10U_GDS4_SFC)。它本质上是一个包含风值的平面/长网格: 纬度变量从 90 到 -90,经度变量从 0 到 360。 我希望使用以下地理角边界提取整个网格的子集: 左下角:纬度:34.5
-
我有一个海洋温度的 NetCDF 文件。它有 1 个变量(“temp”)和 4 个维度(时间、纬度、纬度和深度)。我想只提取每次最大深度的温度,lon和lat,以获得海底温度光栅砖。我愿意使用 R 或在终端中使用气候数据运算符。 NetCDF 文件的属性 提前感谢!
-
我有一个KML文件如下: 我想分别提取每个placemark的名称以及与该placemark关联的LineString标记中的所有坐标,结果如下: 我已经尝试了这里提出的所有解决方案,但没有一个适合我的数据。事实上,那里的所有解决方案都是高度通用的,并且没有提供用于检查它们的测试数据。 更新:我在下面的代码中取得了一些进展,它允许提取所有的位置标记和线性坐标(我只是忘记了该死的命名空间): 但是仍