
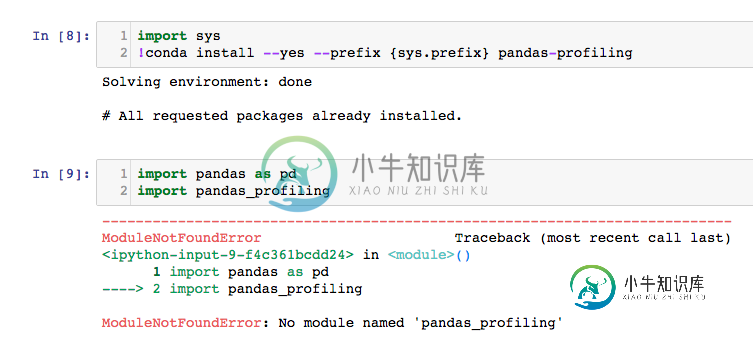
无法导入熊猫档案

共有3个答案


当然,您可以通过 pip 安装,但我喜欢使用 conda 进行尽可能多的安装,以帮助保持环境更易于使用。
conda页面显示了熊猫分析的多个版本:https://anaconda.org/conda-forge/pandas-profiling
安装时需要指定最新版本:
conda install -c conda-forge pandas-profiling=2.6.0
将 2.6.0 替换为最新版本。

非常感谢所有试图帮助我的人。这奏效了。
import sys
!{sys.executable} -m pip install pandas-profiling
-
我已经用和python3.7安装了它,但是当我尝试导入pandas并运行代码时,会出现错误。 Traceback(最近一次调用最后一次):文件/用户/芭比/Python/测试/test.py,第1行,在导入熊猫为pd ModuleNotFoundError:没有名为'熊猫'的模块 如果我尝试再次安装...它说这个。 已满足pip3安装pandas要求:已满足pandas in/usr/local/
-
我在csv原始数据文件中遇到EM Dash问题,导致熊猫无法读取csv。 我在下面运行了一些变体 收到错误:“UnicodeDecodeError:“ascii”编解码器无法解码位置4:序号不在范围(128)中的字节0xef” 其他变化包括 收到错误:“UnicodeDecodeError:'utf8'编解码器无法解码位置0中的字节0xff:无效的开始字节” 收到错误:“行包含空字节” 如果成功,
-
Python是如何将CSV文件读入pandas数据帧的(我可以使用它进行统计操作,可以有不同类型的列,等等)? 我的CSV文件有以下内容: 在R中,我们将使用以下方法读取此文件: 这将返回一个R数据。框架: 有没有类似python的方法来获得相同的功能?
-
我试图从djangotoolbox.fields使用Listfield,但它给我一个错误说: 我做错了什么?
-
问题内容: 不知道这里出了什么问题…我想要的只是本系列中的第一个也是唯一的元素 为什么这样不起作用?以及如何获得第一个元素? 问题答案: 当索引为整数时,您将无法使用位置索引器,因为选择将是模棱两可的(应基于标签还是位置返回?)。您需要明确使用 或传递标签。 由于索引类型是对象,因此可以进行以下操作: 但是对于整数索引,情况有所不同:
-
我有一个1.5GB.dat文件需要作为pandas数据帧导入,我遇到了内存问题(8GB RAM)。如何将dat文件分解成块来执行分析?