
在Firestore中创建追随者和跟随模型的最好方法是什么?

我试着让追随者和追随者像这样建模。所以每个用户都有following和followers子集合
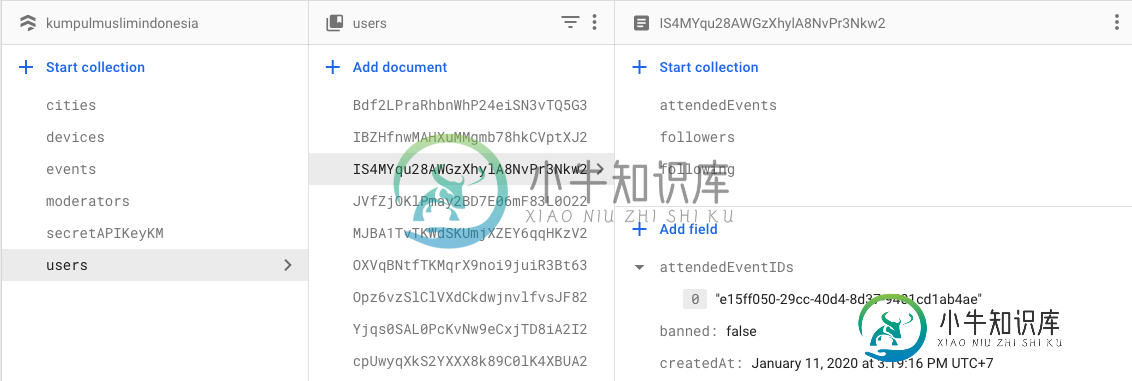
我只在下面的子集合中保存文档中的最小数据,如配置文件图片路径、uid和全名
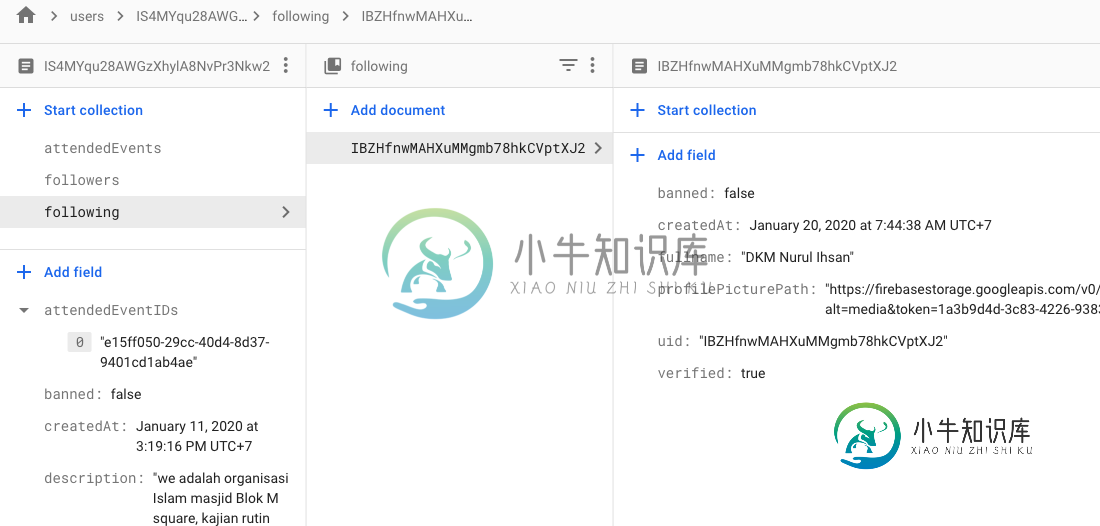
但该模型存在的问题是,当用户在“Users”父集合中更改其个人资料图片或显示名称时,跟随者的子集合中的名称和个人资料图片不会更新。
exports.callableUpdateUserDataInOtherDocuments = functions.https.onCall(async (data, context) => {
try {
const verifiedUserSnapshot = await db.doc(`users/${context.auth.uid}`).get()
const userData = verifiedUserSnapshot.data()
// update display name in following subcollection of the followers
const changeUserDataInFollowersPromises = []
const followersSnapshot = await db.collection(`users/${context.auth.uid}/followers`).get()
followersSnapshot.forEach( doc => {
const followerID = doc.data().uid
const p = db.doc(`users/${followerID}/following/${userData.uid}`).update({
fullname: userData.fullname,
profilePicturePath: userData.profilePicturePath
})
changeUserDataInFollowersPromises.push(p)
})
return Promise.all(changeUserDataInFollowersPromises)
} catch(error) {
console.log(error)
return null
}
})
共有1个答案

实际上,对于您的情况,在用户有许多追随者的情况下,您将需要执行许多操作。您需要平衡思考系统的方式,因为Firestore和Cloud功能将能够处理和扩展性能,所以您不会面临任何与此相关的问题。
然而,账单可能是你面临的主要问题。对于您的用例,它有必要在这么长的时间内更新数据库。
我做了一个搜索,我找到了下面的讨论链接,这些讨论可能会帮助你决定你的系统以及它将如何工作。
-
null
-
本文向大家介绍解释领导者和追随者的概念。相关面试题,主要包含被问及解释领导者和追随者的概念。时的应答技巧和注意事项,需要的朋友参考一下 答:在Kafka的每个分区中,都有一个服务器充当领导者,0到多个服务器充当追随者的角色。
-
我将PHP和MySQL用于社交网络系统 我有MySQL表命名为member_feed,在这个表中我为每个成员保存提要,我的表结构是: 在这个表中,我有超过1.2亿条记录,每个成员都有一套记录。 我目前的工作是从MySQL迁移到MongoDB,我是MongoDB的新手。所以我需要将此表转换为MongoDB中的集合。我想为member_feed表建立我的收藏,比如: 1-表格中的每一行member_f
-
问题内容: 我正在寻找创建一个可重用的函数,该函数将生成一个随机密钥,该随机密钥具有选定长度(可从2到1000+)的可打印ACSII字符。我认为可打印的ASCII字符应为33-126。它们的密钥不需要完全唯一,只要在完全相同的毫秒内生成就可以唯一(因此不起作用)。 我正在考虑将结合使用,并且可能会起作用。 这是要走的路,还是其他最佳方法? 编辑: 也将不起作用,因为它没有长度参数,这就是PHP给您
-
问题内容: 类似于[a-zA-Z0-9]字符串: na1dopW129T0anN28udaZ 或十六进制字符串: 8c6f78ac23b4a7b8c0182d 长期以来,我的意思是2K和更多字符。 问题答案: 这在我的盒子上大约有200MBps。有明显的改进空间。 您只需要生成所需的字符串即可。显然,您可以在途中或其他情况下调整字符集。 这个模型的好处是,它只是一个,因此您可以使用它制作任何东西。
-
我正在尝试使用Selenium chrome webdriver和BeautifulSoup为一个拥有8万粉丝的帐户获取twitter粉丝数据。我在剧本中面临两个问题: 1) 在加载所有跟随者后滚动到页面底部以获取整个页面源代码时,我的脚本不会一直滚动到底部。加载随机数量的追随者后,它停止在两者之间滚动,然后开始遍历每个追随者配置文件以获取其数据。我希望它加载页面上的所有追随者,然后开始遍历配置文
-
我需要创建一个Firestore文档,并在下一步中使用它的documentID。这一切都很好,但我希望应用程序脱机工作,所以我不能脱机创建文档和查询它的ID。 我认为可以将docID设置为创建docuement的DateTime对象。这样,它就不会在以后意外地重新创建和重写(因为他们需要获得毫秒的权利)。 这样我就可以创建文档,并在下一步中使用它的id创建更多的文档。当我连接互联网时,一切都将与F