
如何在Java8(Spring Boot)应用程序中设置最大非堆内存?

我有20个Spring Boot(2.3)嵌入式Tomcat应用程序运行在8GB的Linux上。所有应用程序Java1.8个应用程序。机器运行内存溢出,结果Linux开始杀死我的一些应用程序进程。
使用Linux top和Spring Boot admin,我注意到最大内存堆设置为2GB:
java -XX:+PrintFlagsFinal -version | grep HeapSize
因此,20个应用程序中的每一个都试图获得2GB的堆大小(物理内存的1/4)。使用SpringBootAdmin,我只能看到使用了~128MB。因此,我通过java-Xmx512m将最大堆大小减少到512
现在,Spring Boot admin显示:
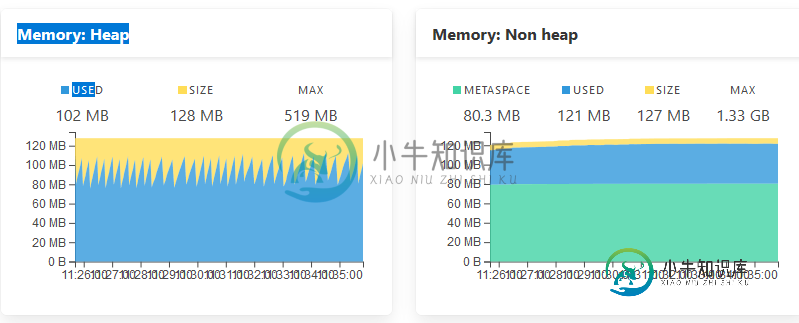
1.33 GB分配给非堆空间,但只使用了121 MB。为什么这么多被分配到非堆空间?我怎样才能减少?
使现代化
根据顶部,每个Java过程大约需要2.4GB(VIRT):
KiB Mem : 8177060 total, 347920 free, 7127736 used, 701404 buff/cache
KiB Swap: 1128444 total, 1119032 free, 9412 used. 848848 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2547 admin 20 0 2.418g 0.372g 0.012g S 0.0 4.8 27:14.43 java
.
.
.
更新2
我运行jcmd 7505 VM.native_memory为其中一个进程,它报告:
7505:
Native Memory Tracking:
Total: reserved=1438547KB, committed=296227KB
- Java Heap (reserved=524288KB, committed=123808KB)
(mmap: reserved=524288KB, committed=123808KB)
- Class (reserved=596663KB, committed=83423KB)
(classes #15363)
(malloc=2743KB #21177)
(mmap: reserved=593920KB, committed=80680KB)
- Thread (reserved=33210KB, committed=33210KB)
(thread #32)
(stack: reserved=31868KB, committed=31868KB)
(malloc=102KB #157)
(arena=1240KB #62)
- Code (reserved=254424KB, committed=27120KB)
(malloc=4824KB #8265)
(mmap: reserved=249600KB, committed=22296KB)
- GC (reserved=1742KB, committed=446KB)
(malloc=30KB #305)
(mmap: reserved=1712KB, committed=416KB)
- Compiler (reserved=1315KB, committed=1315KB)
(malloc=60KB #277)
(arena=1255KB #9)
- Internal (reserved=2695KB, committed=2695KB)
(malloc=2663KB #19903)
(mmap: reserved=32KB, committed=32KB)
- Symbol (reserved=20245KB, committed=20245KB)
(malloc=16817KB #167011)
(arena=3428KB #1)
- Native Memory Tracking (reserved=3407KB, committed=3407KB)
(malloc=9KB #110)
(tracking overhead=3398KB)
- Arena Chunk (reserved=558KB, committed=558KB)
(malloc=558KB)
共有2个答案

除了已经说明的内容之外,这里还有一篇关于JVM中的元空间的非常好的文章,默认情况下,它保留了大约1GB的空间(尽管它实际上可能没有使用那么多)。因此,如果您有许多小型应用程序,并且希望减少使用/保留的内存量,那么您还可以使用标志-XX:MaxMetaspaceSize进行调整。

首先-否,未分配1.33GB。在屏幕截图上,您分配了127MB的非堆内存。1.33GB是最大限制。
我看到您的元空间大约是80MB,这应该不会造成问题。剩下的记忆可以由很多东西组成。压缩类、代码缓存、本机缓冲区等。。。
要获得消耗堆外内存的详细视图,可以查询MBeanjava。lang:type=MemoryPool,name=*,例如通过带有MBean插件的VisualVM。
然而,你的应用程序可能只是消耗了太多的本地内存。例如,来自Netty的许多I/O缓冲区可能是罪魁祸首(被java.nio.DirectByteBuffer使用)。如果这是罪魁祸首,您可以使用标记-Djdk限制,或使用DirectByteBuffers的缓存。尼奥。maxCachedBufferSize-XX:MaxDirectMemorySize设置限制。为了确定到底是什么在消耗RAM,您必须创建一个堆转储并对其进行分析。
所以回答你的问题“为什么这么多被分配到非堆空间?我怎样才能减少?"分配给非堆空间的不多。其中大部分是用于I/O和JVM内部的本机缓冲区。没有通用开关或标志来一次限制所有不同的缓存和池。
现在来解决房间里的大象。我认为你真正的问题源于内存很少。您说过您在8GB机器上运行20个JVM实例,但堆空间限制为512MB。20 x 512MB=10GB的堆,这超过了8GB总内存的容量。这是在你在堆外/本机内存中计数之前。您需要提供更多的硬件资源,减少JVM计数,或者进一步减少堆/元空间和其他限制(我强烈建议不要这样做)。
-
我正在使用camel-spring boot starter运行kafka消费者应用程序。SpringBoot应用程序实现CommandLineRunner。在我的应用程序中配置了以下属性。 我试图在端口8080上公开springboot执行器指标,但我在公开endpoint方面面临挑战,因为它是非Web应用程序。urlhttp://localhost:8080/actuator/metrics给
-
如何设置Apache Ignite通过运行时可用的最大堆内存?文件似乎没有涵盖这项非常基本的任务。此外,如何验证设置是否实际工作? 我读到命令行选项可用于将JVM参数从传递到JVM进程,但我无法找到它实际工作的证据。例如,如果我按如下方式启动Ignite: 它在命令行中不明确地列出了和。
-
问题内容: 如何从Java程序中获取VM的最小和最大堆大小设置? 问题答案: 最大堆大小: 您可能会发现一些有趣的其他计算:
-
我在运行单个节点的火花。 我的应用程序(java-web)使用的内存比可用的少。我发现这条线很有用。 对于本地模式,您只有一个执行器,而这个执行器是您的驱动程序,所以您需要设置驱动程序的内存。*也就是说,在本地模式下,当您运行spark-submit时,JVM已经启动了默认内存设置,因此在conf中设置“spark.driver.memory”实际上不会对您有任何帮助。相反,您需要运行spark-
-
我们有一个需求,即应用程序jvm总内存太高,并且根据输入数据集而变化。因此我们不知道要使用-xmx命令行选项设置的最大堆大小。所需的总内存大于默认的最大堆大小(总物理内存的1/4)。 当我们没有给出任何GC人体工程学命令行参数时,内存在9-9.5GB(系统中的总物理内存为38GB)之后没有增长。而应用程序就会在这一点上卡住。 如果我们将Xmx值设为20 GB,则应用程序正在运行。但是我们不确定最大
-
我有Kafka Streams java应用程序启动并运行。我试图使用KSQL创建简单的查询,并使用Kafka流来实现复杂的解决方案。我希望将KSQL和Kafka流作为Java应用程序运行。 我打算通过https://github.com/confluentinc/ksql/blob/master/ksqldb-examples/src/main/java/io/confluent/ksql/em