
Mongodb查询聚合和Groupby复合过滤器,求和,百分比查询

我有一个复杂的组查询。
数据如下:
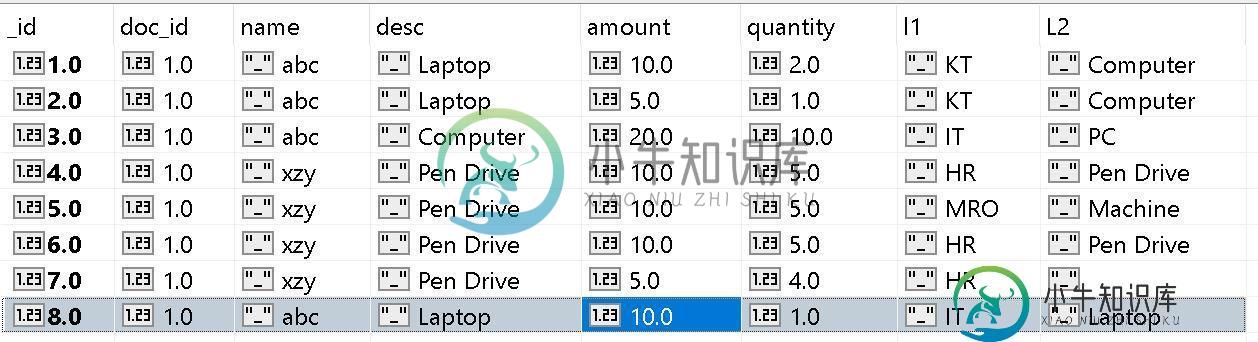
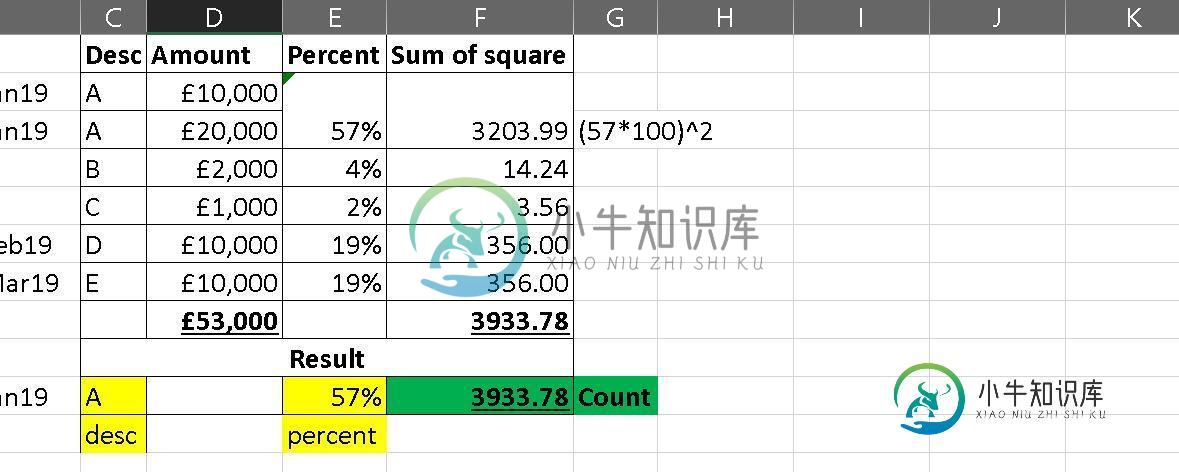
汇总如下:
-
null
...
},
"_id" : {
"name" : "abc"
},
"amount" : 45.0,
"count" : 4.0,
"desc" : {
"value" : "Laptop", // based on highest sum amount in group:'abc' i.e. 25.0 for laptop
"count" : 5061.72, // (56*100)^2 + (44*100)^2
"percent" : 25.0*100/45.0 = 56.0
},
...
共有1个答案

不明白你需要的计算数。但是,您可以使用以下查询来满足您的需要:
db.collection.aggregate([
{
$match: {
"doc_id": 1
}
},
{
$group: {
_id: {
name: "$name",
desc: "$desc"
},
amount: {
$sum: "$amount"
},
count: {
$sum: 1
},
}
},
{
$sort: {
"_id.name": 1,
"amount": -1
}
},
{
$group: {
_id: "$_id.name",
amount: {
$sum: "$amount"
},
count: {
$sum: "$count"
},
desc: {
$first: {
value: "$_id.desc",
descAmount: "$amount"
}
}
},
},
{
$addFields: {
"desc.percent": {
$multiply: [
{
$divide: [
"$desc.descAmount",
"$amount"
]
},
100
]
}
}
}
])
技巧是两次分组,中间有一个排序,以获得sub-total和第一个元素(每个名称的sub-total最大的元素)。现在您可以根据需要调整您的计数计算。
你可以在这里测试。
-
我使用Nodejs和MongoDB与expressjs和mongoose库,创建一个具有用户、文章和评论模式的博客API。下面是我使用的模式。
-
主要内容:aggregate() 方法,管道MongoDB 中的聚合操作用来处理数据并返回计算结果,聚合操作可以将多个文档中的值组合在一起,并可对数据执行各种操作,以返回单个结果,有点类似于 SQL 语句中的 count(*)、group by 等。 aggregate() 方法 您可以使用 MongoDB 中的 aggregate() 方法来执行聚合操作,其语法格式如下: db.collection_name.aggregate(aggr
-
假设我有一个MongoDB集合,其中包含以下信息: 我想计算按州分组的订单总价的总和,其中项目为“苹果”,颜色为“红色”。我的问题是: 但是,我希望能够将我的结果cust\u id包含在\u id中,它是一个数组/映射/一些结构,其中包含构成我的合计的所有客户id的列表。因此,我希望我的输出包含 是否有办法处理此mongo聚合/查询?或者是一种更好的方式来构造此查询,以便我可以按州分组计算红苹果的
-
问题内容: 我有两种日志消息: 第一个消息是已发送消息的类型,第二个消息是确认消息已传递的消息。 它们之间的区别是后缀,我已将其与“ id”分开并可以对其进行查询。 这些消息将按以下格式解析并存储在elasticsearch中: 我想找出哪些消息已成功发送,哪些没有成功。我是Elasticsearch的初学者,所以我真的很努力。 我目前正在尝试术语聚合,但是我所能实现的就是以下代码: 向我显示已发
-
>[danger] 注意!!! 使用聚合功能时,必须给它一个别名,以便能够从模型中访问它 > 聚合函数的计算,都是排除了 null 值,所以COUNT( id ) 一般推荐用非空的主键来计算 COUNT 计算数量 const { Sequelize } = app; // 查询班级总人数,按照姓名聚合 const ret = await Student.findAll({ attribut
-
在应用中我们经常会用到一些统计数据,例如当前所有(或者满足某些条件)的用户数、所有用户的最大积分、用户的平均成绩等等,ThinkPHP为这些统计操作提供了一系列的内置方法,包括: 方法 说明 count 统计数量,参数是要统计的字段名(可选) max 获取最大值,参数是要统计的字段名(必须) min 获取最小值,参数是要统计的字段名(必须) avg 获取平均值,参数是要统计的字段名(必须) sum