
将递归sql转换转换为spark

我们正在获取具有以下字段的订单数据(仅显示相关字段)
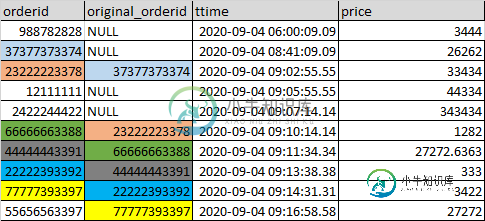
- 具有NULLoriginal_orderid的订单可以被认为是父订单
- 其中一些父母订单可能有子订单,子订单的original_orderid映射到父母的订单。
- 子顺序可以产生另一个子顺序,如图像所示,带有颜色编码。
与原始文本相同的数据:
+-----------+----------------+---------------------+----------+
|orderid |original_orderid|ttime |price |
+-----------+----------------+---------------------+----------+
|988782828 |0 |2020-09-0406:00:09.09|3444.0 |
|37377373374|0 |2020-09-0408:41:09.09|26262.0 |
|23222223378|37377373374 |2020-09-0409:02:55.55|33434.0 |
|2111111 |0 |2020-09-0409:05:55.55|44334.0 |
|2422244422 |0 |2020-09-0409:07:14.14|343434.0 |
|66666663388|23222223378 |2020-09-0409:10:14.14|1282.0 |
|44444443391|66666663388 |2020-09-0409:11:34.34|27272.6363|
|22222393392|44444443391 |2020-09-0409:13:38.38|333.0 |
|77777393397|22222393392 |2020-09-0409:14:31.31|3422.0 |
|55656563397|77777393397 |2020-09-0409:16:58.58|27272.0 |
+-----------+----------------+---------------------+----------+
作为转换,我们需要将所有子节点映射到它们的原始父节点(original_orderid为NULL),并获得该顺序可能具有的级别数。预期成果将是:

这是从sqlserver到火花迁移工作的一部分。在sql server中,这是在递归访问父视图的视图中实现的。
我们可以用这样的伪代码在火花中尝试这种转换:
val df = spark.read(raw_data_file)
val parent = df.filter(col(original_orderid).isNull)
.select(col(orderid).as("orderid"), col(order_id).as("parent_orderid")
val children = df.filter(col(original_orderid).isNotNull).sort(col(ttime))
var prentCollection = //Collect parent df in collection
val childrenCollection = //Collect child df in collection
//Traverse through the sorted childrenCollection
for (child <- childrenCollection) ={
if child.original_orderid in parentCollection.orderid.alias(parent)
insert into parentCollection - child.orderid as orderid, parent.parent_orderid as parent_orderid, child.ttime as ttime, child.price as price
}
此解决方案需要收集驱动程序中的所有数据,因此无法分发,不适合大数据集。
你能不能建议我任何其他的方法,使它在火花中的更大的数据集工作,或者对上面现有的数据集进行任何改进。
共有1个答案

您可以递归地加入并累积父数组。下面是一个使用Spark v2.1的快速原型
val addToArray = udf((seq : Seq[String] , item: String) => seq :+ item)
//v2.4.0 use array_union
val concatArray = udf((seq1 : Seq[String] , seq2 : Seq[String]) => seq1 ++ seq2)
//v2.4.0 use element_at and size
val lastInArray = udf((seq: Seq[String]) => seq.lastOption.getOrElse(null))
//v2.4.0 and up use slice
val dropLastInArray = udf((seq: Seq[String]) => seq.dropRight(1))
val raw="""|988782828 |0 |2020-09-0406:00:09.09|3444.0 |
|37377373374|0 |2020-09-0408:41:09.09|26262.0 |
|23222223378|37377373374 |2020-09-0409:02:55.55|33434.0 |
|2111111 |0 |2020-09-0409:05:55.55|44334.0 |
|2422244422 |0 |2020-09-0409:07:14.14|343434.0 |
|66666663388|23222223378 |2020-09-0409:10:14.14|1282.0 |
|44444443391|66666663388 |2020-09-0409:11:34.34|27272.6363|
|22222393392|44444443391 |2020-09-0409:13:38.38|333.0 |
|77777393397|22222393392 |2020-09-0409:14:31.31|3422.0 |
|55656563397|77777393397 |2020-09-0409:16:58.58|27272.0 |"""
val df= raw.substring(1).split("\\n").map(_.split("\\|").map(_.trim)).map(r=> (r(0),r(1),r(2),r(3))).toSeq.toDF ("orderId","parentId","ttime","price").withColumn("parents",array(col("parentId")))
def selfJoin(df :DataFrame) : DataFrame = {
if (df.filter(lastInArray(col("parents")) =!= lit("0")).count > 0)
selfJoin(df.join(df.select(col("orderId").as("id"), col("parents").as("grandParents")), lastInArray(col("parents")) === col("id"),"left").withColumn("parents",when(lastInArray(col("parents")) =!= lit("0"),concatArray(col("parents"),col("grandParents"))).otherwise(col("parents"))).drop("grandParents").drop("id"))
else
df
}
selfJoin(df).withColumn("level",size(col("parents"))).withColumn("top parent",lastInArray(dropLastInArray(col("parents")))).show
-
我有一个关于如何将“递归”转换为“尾部递归”的问题。 这不是家庭作业,只是在我试图润色算法书籍中的递归定理时出现的一个问题。 我熟悉使用递归的两个典型示例(阶乘和斐波那契序列),也知道如何以递归方式和尾部递归方式实现它们。 我的代码如下(我使用Perl只是为了使其简单,但可以轻松地转换为C/Java/C)。 运行代码时,输出如下: 递归函数在返回之前使用不同的参数调用自己两次。我尝试了几种方法将其
-
我想知道是否有一些通用方法可以用foo(…)转换“正常”递归foo(…) 作为尾部递归的最后一个调用。 例如(scala): 函数语言将递归函数转换为等价尾部调用的一般解决方案: 一种简单的方法是将非尾部递归函数包装在蹦床单子中。 所以pascal函数不再是递归函数。然而,蹦床单子是需要完成的计算的嵌套结构。最后,是一个尾递归函数,它遍历树状结构,解释它,最后在基本情况下返回值。 Rúnar Bj
-
我只是想知道这样的函数是否可以递归地完成。我觉得很难,因为它自己叫了两次。 这是我在javascript中的非尾部递归实现。(是的,我知道大多数javascript引擎不支持TCO,但这只是理论上的。)目标是找到给定数组(arr)中具有特定长度(大小)的所有子列表。例如:getSublistsWithFixedSize([1,2,3],2)返回[[1,2]、[1,3]、[2,3]]
-
问题内容: 我正在尝试将以下SQL查询转换为HQL,并且遇到了一些问题。直线逐行转换不起作用,我想知道是否应该在HQL中使用内部联接? 查询返回客户订单状态更改之间的时间(以秒为单位)。 状态名称和日期会动态插入查询中。 编辑:刚刚尝试过 并收到异常“ 外部或完全连接后必须跟路径表达式 ” 问题答案: 通常,您使用对象上的属性指定HQL连接,例如,如果类Foo和Bar和Foo.bar是Bar类型,
-
问题内容: 是否每个递归函数都有一个等效的for循环?(两者都达到相同的结果)。 我有这个递归函数: 假设单词是Set [],并且单词[i] =单词长度为i的集合。 我想做的是:使用一个单词(例如,“ stackoverflow”,没有空格)启动递归,我试图查找该单词是否可以切成子单词(“ stack”,“ over”,“ flow”) ..子词的最小长度为3,并且假设长度为i的子词在Set wo
-
问题内容: 我正在尝试将数据从简单的对象图转换为字典。我不需要类型信息或方法,也不需要能够再次将其转换回对象。 我发现了有关从对象的字段创建字典的问题,但它不是递归执行的。 对于python来说相对较新,我担心我的解决方案可能很丑陋,或者是非Python的,或者以某种晦涩的方式破坏了,或者仅仅是普通的NIH。 我的第一次尝试似乎一直有效,直到我使用列表和字典对其进行尝试为止,并且似乎更容易的是仅检