
OneNote解析--如何找到文档中的文本Blobs?

我正在为.one文件扩展名创建一个解析器,完成后我将把它添加到Apache Tika项目中。
下面是我正在创建的APL2.0许可开放源代码项目:https://github.com/nddipiazza/onenote-parser-java
我在这里使用了规范文档:https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-one/73D22548-A613-4350-8C23-07D15576BE50

我无法查看解析结果中的Section1TextArea1和Section1TextArea2。所以我缺少了一些关键的数据解析元素之类的东西。
它肯定在OneNote文件本身中。我可以在十六进制查看器中看到它:
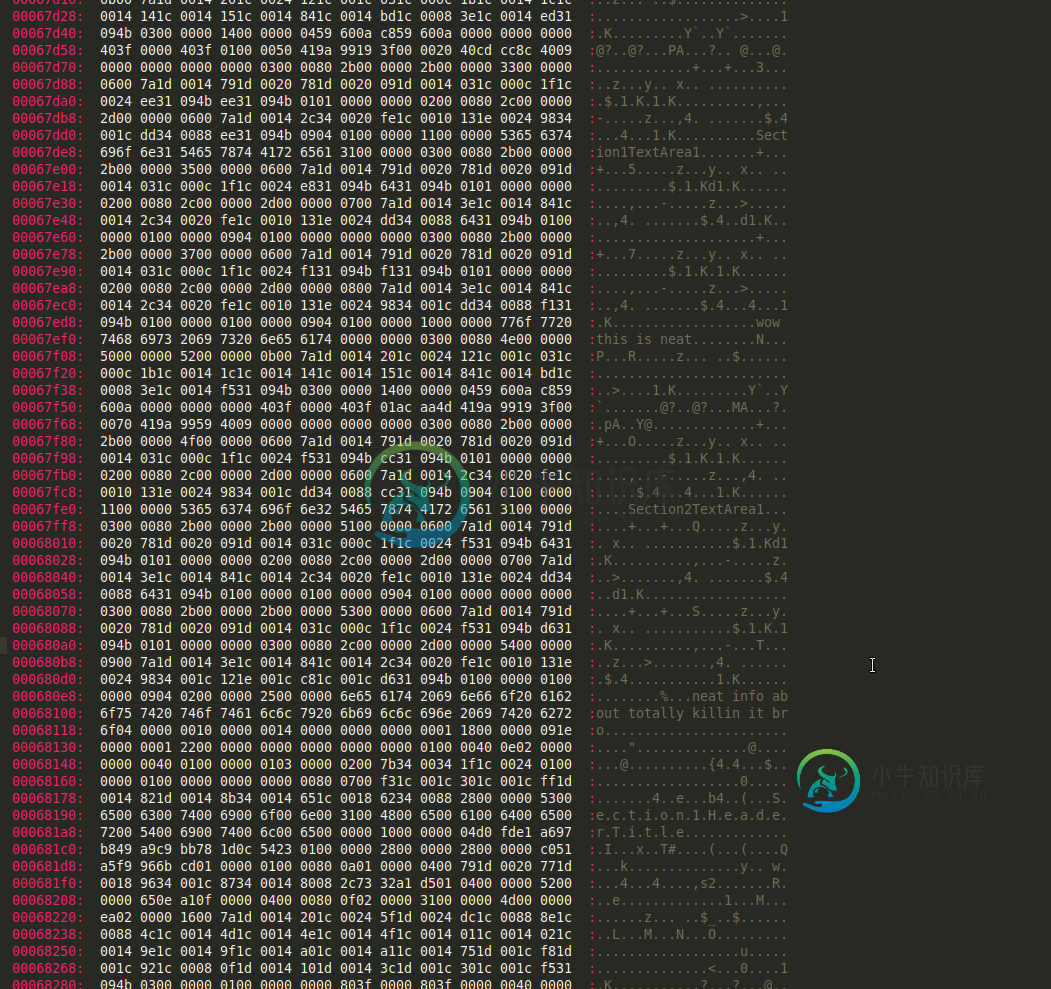
以下是JSON解析输出:https://gist.github.com/nddipiazza/02d2252d357b3b02a6b9ab1050474267
我觉得规范文档缺少了解析这种专有格式所需的一些非常重要的信息。
我缺少什么主要因素导致我无法获得实际的文本内容?
共有1个答案

我想通了。OneNote中的属性值可以有以下两种:
- 二进制内容
- ASCII文本内容
- UTF-16LE内容。
有各种各样的它们洒在整个。
-
我无法理解为什么当我通过的文本符合格式时,我会得到DateTimeParseException错误。下面是导致该问题的代码: 奇怪的是。每当我查询用户一段时间(让我们以00:02:30为例),它就会完全按照我想要的方式运行。但是当我使用我的方法(从文本文件中提取时间)时,它会出现错误: 线程“main”java.time.format.DateTimeParseException中出现异常:无法分
-
问题内容: 我愿意将文件保存在用户的“我的文档”文件夹中。 我试图得到这样的位置: 然后,我意识到这在将语言设置为另一种语言(例如法语)的系统中不起作用。 还有另一种方法可以有效地获取“我的文档”文件夹吗? 问题答案: 如果您不介意使用Swing,显然可以使用以下技巧: (来源:http : //www.rgagnon.com/javadetails/java-0572.html)
-
问题内容: SVG元素包含一个数据属性()。有时有必要仅从SVG文件加载,解析和提取路径信息。 题 如何从SVG文件加载,解析和提取SVG路径信息? 问题答案: 总览 使用ApacheBatik加载和解析SVG文件。该解决方案在将SVG文件转换为MetaPost的初期阶段显示了Java代码。这应该为如何使用Java从SVG文件中加载,解析和提取内容提供一个总体思路。 图书馆 您将需要以下库: 加载
-
我们正在使用PowerShell脚本创建Office 365组,这个过程已经到位,我们对此很满意。 但是,我想知道是否可以通过图形API触发默认OneNote文档的创建?似乎在创建组时,只有有人手动访问文档库并单击OneNote文档,它才真正被创建(即时)。我得出了这个结论,因为如果我们在组本身上运行一个Get UnifiedGroup(将结果存储在),则以下属性为空:
-
我想知道这怎么可能。假设我正在搜索,那么的得分应该比的得分要多。如何提升那些文档?。我已经试过了。 我正在尝试使用,如下所示。但不管用。我用的是Lucene4.0
-
此链接(http://www.lenovo.com/psref/pdf/psref450.pdf)中的PDF包含许多类似这样的表格: 我想以编程方式从这些表中提取数据和结构。 我尝试过的事情:使用 Tika:不幸的是,表格被转换为空格分隔的段落 - 并且某些字符串包含空格,因此无法拆分它们。 Python的PDFMiner:由于缺少字体而返回断言错误。我怀疑 HTML 与 Ika 的输出相似,尽管