
指定预测期不限制预测产出

我试图建立一个长达10年的时间序列的ARIMA模型,并用它来预测未来一年。为了测试我的模型,我在9年的数据上进行训练,预测1年的数据,并将预测值与当年的实际值进行比较。
问题:我告诉预测()将其预测的期限限制为365年,即1年。但是当我绘制输出时,它似乎输出9年或大约3285的“h=”。为什么会发生这种情况?
##The time series is 3650 daily observations of rainfall
x <- ts(x$obs, start=c(2007, 10), end=c(2017, 9), frequency = 365)
##create training set - first 9 years of observations
x_train <- subset(x, start = 1, end = 3285)
##test set - last year of observations
x_test <- subset(x, start = 3286, end = 3650)
##fit the model
x_train_fit <- auto.arima(x_train, seasonal=FALSE, xreg=fourier(x_train, K=1))
##forecast using the model
x_fcast_test <- forecast(x_train_fit,h=365, xreg=fourier(x_train, K=1))
plot(x_fcast_test, col="black")
lines(x_test,col="red")
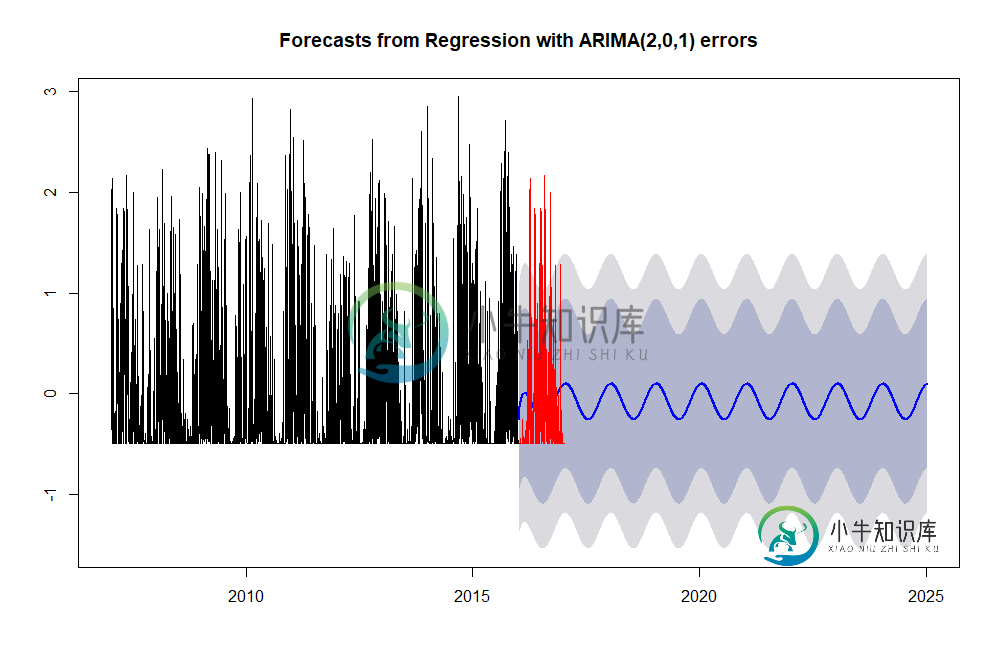
更新:罗布·海曼下面的答案是正确的。预测周期的数量将被设置为xreg的行数,因为当使用xreg时,它有利于h=,所以我的h=没有被使用。因此,将整个训练集作为exreg传入,创建了一个与训练集长度相等的预测。
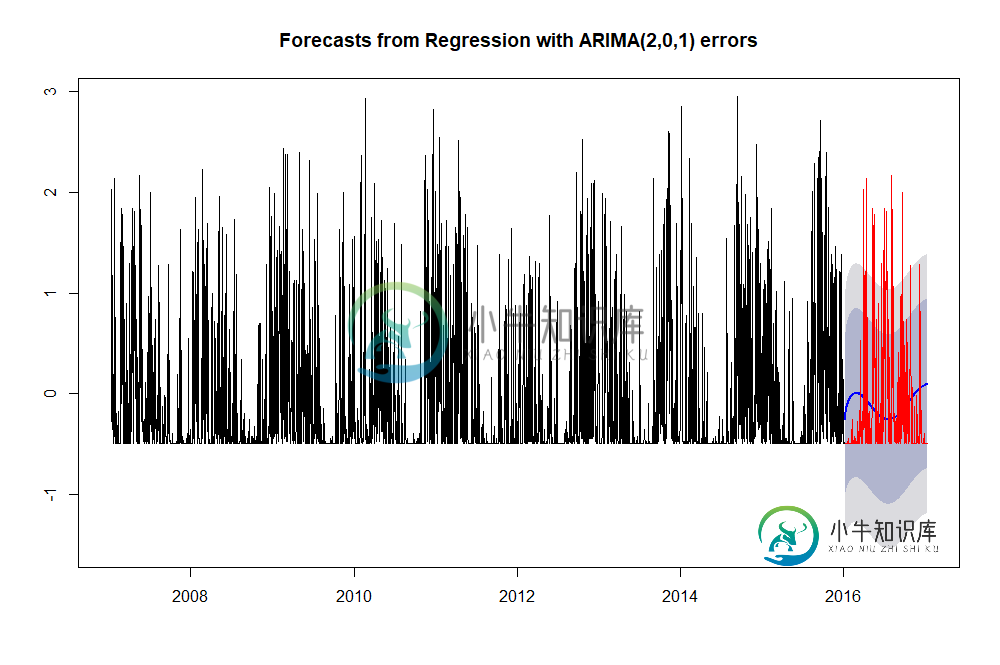
x_fcast_test <- forecast(x_train_fit,h=365, xreg=fourier(x_test, K=1))
plot(x_fcast_test, col="black")
lines(x_test,col="red")
共有1个答案

始终值得阅读提供的帮助文件。在这种情况下:
h:预测的周期数。如果使用xreg,则忽略h,并将预测周期的数量设置为xreg的行数。
您在xreg参数中传递了训练数据,因此您可以获得与观测值一样多的预测值。
您可能打算将测试数据用于xreg参数。
-
在解释字节码执行的虚拟机中,一般都会有上一篇说的switch结构,而字节码的类型显然不止前面列出的那些,一个很简单的语言都可能有上百个字节码,于是引入了另一个问题,假设用C或C++实现,在很多编译器中,switch实际会被编译成一连串的if...else if... ... ...else,执行的时候,每条指令都从头开始判断,执行某些指令时,需要成百甚至上千的比较次数,严重影响运行效率。当然这个问
-
主要内容:1. 运行时异常,2. 检查异常在本教程中,我们将演示如何使用TestNG expectedExceptions来测试代码中的预期异常抛出。 创建一个名称为 ExpectedExceptionTest 的 Maven 工程,其结构如下所示 - 1. 运行时异常 此示例显示如何测试运行时异常。 如果方法抛出一个运行时异常 — ,它会获得通过。 创建一个测试文件:TestRuntime.java ,其代码如下所示 - 运行上面代码,
-
如果语句更多地依赖于分支预测,而v表查找更多地依赖分支目标预测,那么
-
分支目标预测(BTP)与分支预测(BP)不同。我知道BTP会找到分支将跳转到的位置,而BP只是决定可能采取哪个分支。 BTP依赖BP吗,如果BTP不使用BP来预测哪个分支被采用,它怎么可能知道分支的目标呢? 我不明白为什么会有这么大的差异?一旦分支被预测为被占用,找到目标并不像读取指令中的地址一样简单吗?
-
今天sola要介绍一款很好用的插件Kadence WooCommerce Email Designer,该插件可以实现WooCommerce邮件定制、预览和测试,一个插件实现三个功能,而且实现的很漂亮。 WooCommerce邮件定制 用WordPress Customizer的方式定制邮件,对于熟练使用WordPress的人来说可谓轻车熟路。编辑header、footer,定制邮件宽度,更改背景
-
我目前正在编写一个Intel 8042驱动程序,并编写了两个循环来等待一些缓冲区准备就绪: 如您所见,我在循环中插入了指令。我最近才知道它,很自然地想尝试一下。 由于 的内容是不可预测的,因为它是 I/O 读取,因此分支预测器将使用循环指令填充管道:经过一些迭代后,它会注意到总是采用一个分支,类似于这里的情况。 如果分支预测器真的在其预测中包含I/O指令,那么上述是正确的,我不确定。 那么分支预测