
使用BeautifulSoup搜索Yahoo Finance

我正在尝试从“关键统计信息”页面中获取有关Yahoo中的代码的信息(因为Pandas库中不支持此功能)。
AAPL示例:
from bs4 import BeautifulSoup
import requests
url = 'http://finance.yahoo.com/quote/AAPL/key-statistics?p=AAPL'
page = requests.get(url)
soup = BeautifulSoup(page.text, 'lxml')
enterpriseValue = soup.findAll('$ENTERPRISE_VALUE', attrs={'class': 'yfnc_tablehead1'}) #HTML tag for where enterprise value is located
print(enterpriseValue)
编辑:谢谢安迪!
问题:这正在打印一个空数组。如何更改findAll退货598.56B?
问题答案:
好吧,find_all返回的列表为空的原因是因为该数据是通过单独的调用生成的,仅通过GET向该URL发送请求就无法完成。如果浏览Chrome /
Firefox上的“网络”标签并按XHR进行过滤,则通过检查每个网络操作的请求和响应,您还可以找到应该发送GET请求的URL 。
在这种情况下,它是https://query2.finance.yahoo.com/v10/finance/quoteSummary/AAPL?formatted=true&crumb=8ldhetOu7RJ&lang=en- US®ion=US&modules=defaultKeyStatistics%2CfinancialData%2CcalendarEvents&corsDomain=finance.yahoo.com,我们可以在这里看到:
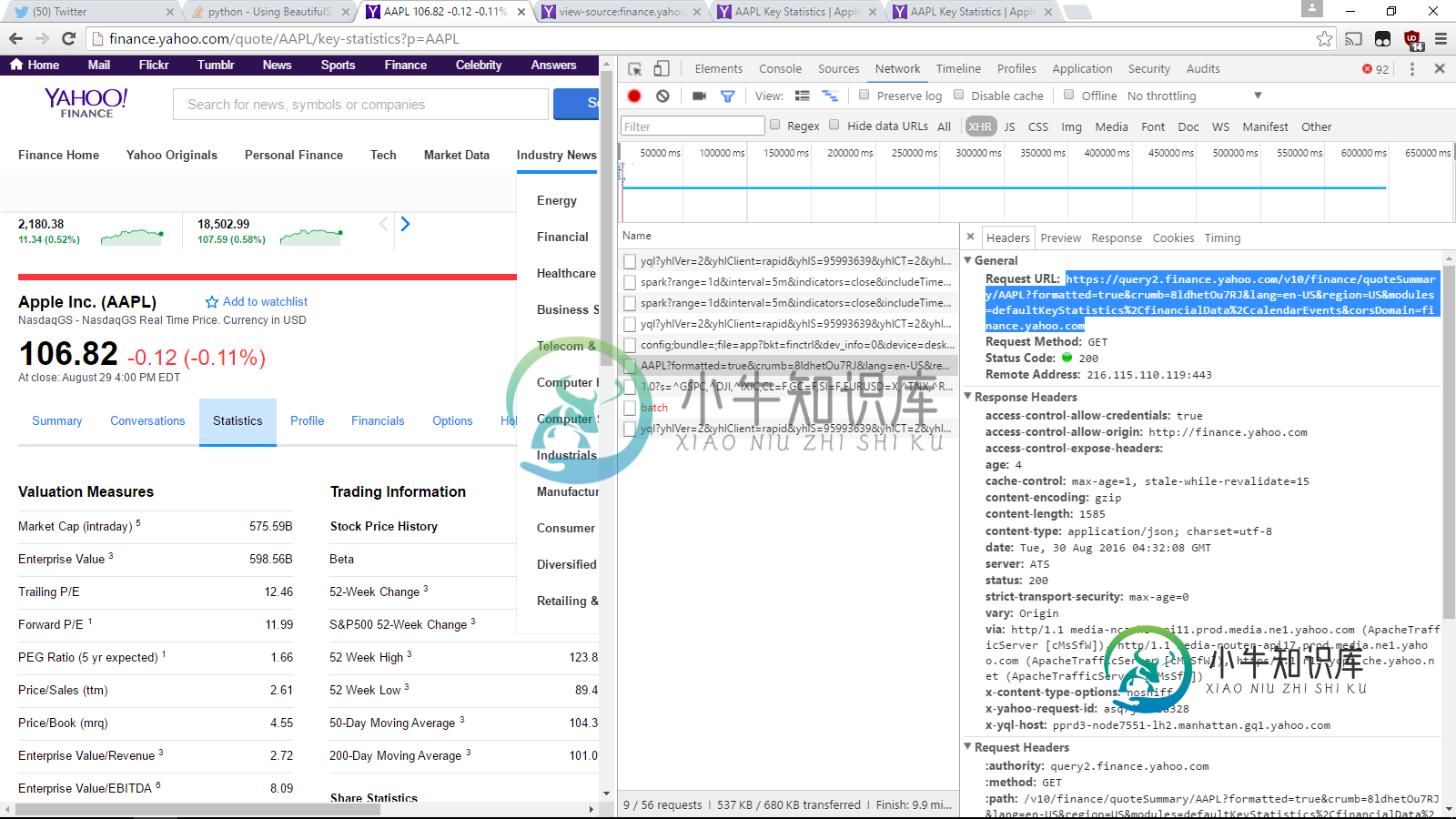
那么,我们如何重新创建它呢?简单!:
from bs4 import BeautifulSoup
import requests
r = requests.get('https://query2.finance.yahoo.com/v10/finance/quoteSummary/AAPL?formatted=true&crumb=8ldhetOu7RJ&lang=en-US®ion=US&modules=defaultKeyStatistics%2CfinancialData%2CcalendarEvents&corsDomain=finance.yahoo.com')
data = r.json()
这将以形式返回JSON响应dict。在此处浏览,dict直到找到需要的数据:
financial_data = data['quoteSummary']['result'][0]['defaultKeyStatistics']
enterprise_value_dict = financial_data['enterpriseValue']
print(enterprise_value_dict)
>>> {'fmt': '598.56B', 'raw': 598563094528, 'longFmt': '598,563,094,528'}
print(enterprise_value_dict['fmt'])
>>> '598.56B'
-
问题内容: 我正在使用BeautifulSoup在特定页面上寻找用户输入的字符串。例如,我想查看字符串“ Python”是否位于页面上:http : //python.org 当我使用时: find_string返回 但是当我使用: find_string返回预期 这两个语句之间有什么区别,使得当要搜索的单词实例不止一个时,第二条语句可以工作 问题答案: 以下行正在寻找 确切的 Navigable
-
问题内容: 我有这个: 但是,我可以将id作为通配符搜索,因为可以是,等等。 问题答案: 您可以提供可调用的过滤器: 或@DSM指出 因为BeautifulSoup将识别RegExp对象并调用其方法。
-
我一直在尝试使用Java的二分搜索方法在单词数组(一个词典)中搜索一个特定的字符串,然后确定该字符串是单词、前缀还是不是单词。如果返回的索引大于或等于零,则字符串为单词。如果返回的索引小于零,那么我必须确定它不是一个单词,还是一个前缀。
-
问题内容: 我在获取nHibernate.Search来创建索引时遇到了麻烦。 如果我使用nHibernate.dll和nHibernate.Search.dll的1.2.1.4,则可以正确创建索引,并且可以使用Luke(Lucene实用程序)对其进行检查。创建了一个segments文件以及一个Fragments文件等 但是,当我使用nHibernate.dll和nHibernate.Search
-
我在处理一个单词搜索问题。我正确地实现了dfs搜索,但在其他地方有一些琐碎的错误。
-
问题内容: 如何检索网页链接并使用Python复制链接的URL地址? 问题答案: 这是在中使用类的一小段代码: