
一旦任何一个进程在python中找到匹配项,如何使所有pool.apply_async进程停止

我有以下代码利用多处理程序来遍历大列表并找到匹配项。在任何一个进程中找到匹配项后,如何使所有进程停止?我已经看到了一些示例,但是我似乎都不适合我在这里所做的事情。
#!/usr/bin/env python3.5
import sys, itertools, multiprocessing, functools
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ12234567890!@#$%^&*?,()-=+[]/;"
num_parts = 4
part_size = len(alphabet) // num_parts
def do_job(first_bits):
for x in itertools.product(first_bits, *itertools.repeat(alphabet, num_parts-1)):
# CHECK FOR MATCH HERE
print(''.join(x))
# EXIT ALL PROCESSES IF MATCH FOUND
if __name__ == '__main__':
pool = multiprocessing.Pool(processes=4)
results = []
for i in range(num_parts):
if i == num_parts - 1:
first_bit = alphabet[part_size * i :]
else:
first_bit = alphabet[part_size * i : part_size * (i+1)]
pool.apply_async(do_job, (first_bit,))
pool.close()
pool.join()
谢谢你的时间。
更新1:
我已经实现了@ShadowRanger的出色方法中建议的更改,并且几乎可以按照我想要的方式工作。因此,我添加了一些日志记录以指示进度,并在其中放置一个“测试”键以进行匹配。我希望能够独立于num_parts来增加/减少iNumberOfProcessors。在这个阶段,当我让它们都达到4时,一切都按预期工作,则4个进程开始旋转(控制台额外增加了一个)。当我将iNumberOfProcessors更改为6时,有6个进程加速旋转,但只有其中一个具有任何CPU使用率。因此看来2是空闲的。在上面的解决方案中,我能够在不增加num_parts的情况下设置更高的内核数,并且所有进程都将被使用。
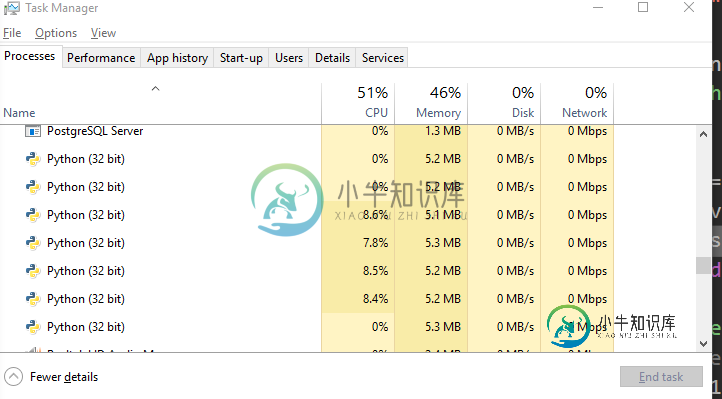
我不确定如何重构这种新方法来为我提供相同的功能。您能否看一下并为我提供一些重构的方向,以便能够彼此独立地设置iNumberOfProcessors和num_parts并仍然使用所有进程?
这是更新的代码:
#!/usr/bin/env python3.5
import sys, itertools, multiprocessing, functools
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ12234567890!@#$%^&*?,()-=+[]/;"
num_parts = 4
part_size = len(alphabet) // num_parts
iProgressInterval = 10000
iNumberOfProcessors = 6
def do_job(first_bits):
iAttemptNumber = 0
iLastProgressUpdate = 0
for x in itertools.product(first_bits, *itertools.repeat(alphabet, num_parts-1)):
sKey = ''.join(x)
iAttemptNumber = iAttemptNumber + 1
if iLastProgressUpdate + iProgressInterval <= iAttemptNumber:
iLastProgressUpdate = iLastProgressUpdate + iProgressInterval
print("Attempt#:", iAttemptNumber, "Key:", sKey)
if sKey == 'test':
print("KEY FOUND!! Attempt#:", iAttemptNumber, "Key:", sKey)
return True
def get_part(i):
if i == num_parts - 1:
first_bit = alphabet[part_size * i :]
else:
first_bit = alphabet[part_size * i : part_size * (i+1)]
return first_bit
if __name__ == '__main__':
# with statement with Py3 multiprocessing.Pool terminates when block exits
with multiprocessing.Pool(processes = iNumberOfProcessors) as pool:
# Don't need special case for final block; slices can
for gotmatch in pool.imap_unordered(do_job, map(get_part, range(num_parts))):
if gotmatch:
break
else:
print("No matches found")
更新2:
好的,这是我尝试@noxdafox建议的尝试。根据他提供的建议,我整理了以下内容。不幸的是,当我运行它时,我得到了错误:
…第322行,在apply_async中引发ValueError(“ Pool not running”)。
谁能给我一些有关如何使它工作的指导。
基本上,问题是我的第一次尝试是进行多处理,但不支持在找到匹配项后取消所有进程。
我的第二次尝试(基于@ShadowRanger的建议)解决了该问题,但是破坏了能够独立扩展进程数和num_parts大小的功能,这是我的第一次尝试。
我的第三次尝试(基于@noxdafox的建议)抛出上面概述的错误。
如果有人可以给我一些指导,说明如何维护我的第一次尝试的功能(能够独立扩展进程的数量和num_parts的大小),并添加一旦发现匹配项便取消所有进程的功能,将不胜感激。
感谢您的时间。
这是基于@noxdafox建议的第三次尝试的代码:
#!/usr/bin/env python3.5
import sys, itertools, multiprocessing, functools
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ12234567890!@#$%^&*?,()-=+[]/;"
num_parts = 4
part_size = len(alphabet) // num_parts
iProgressInterval = 10000
iNumberOfProcessors = 4
def find_match(first_bits):
iAttemptNumber = 0
iLastProgressUpdate = 0
for x in itertools.product(first_bits, *itertools.repeat(alphabet, num_parts-1)):
sKey = ''.join(x)
iAttemptNumber = iAttemptNumber + 1
if iLastProgressUpdate + iProgressInterval <= iAttemptNumber:
iLastProgressUpdate = iLastProgressUpdate + iProgressInterval
print("Attempt#:", iAttemptNumber, "Key:", sKey)
if sKey == 'test':
print("KEY FOUND!! Attempt#:", iAttemptNumber, "Key:", sKey)
return True
def get_part(i):
if i == num_parts - 1:
first_bit = alphabet[part_size * i :]
else:
first_bit = alphabet[part_size * i : part_size * (i+1)]
return first_bit
def grouper(iterable, n, fillvalue=None):
args = [iter(iterable)] * n
return itertools.zip_longest(*args, fillvalue=fillvalue)
class Worker():
def __init__(self, workers):
self.workers = workers
def callback(self, result):
if result:
self.pool.terminate()
def do_job(self):
print(self.workers)
pool = multiprocessing.Pool(processes=self.workers)
for part in grouper(alphabet, part_size):
pool.apply_async(do_job, (part,), callback=self.callback)
pool.close()
pool.join()
print("All Jobs Queued")
if __name__ == '__main__':
w = Worker(4)
w.do_job()
问题答案:
您可以检查该问题,以查看解决您的问题的实现示例。
这也适用于current.futures池。
只需将map方法替换为,apply_async并在调用者的列表上进行迭代即可。
这样的事情。
for part in grouper(alphabet, part_size):
pool.apply_async(do_job, part, callback=self.callback)
石斑鱼食谱
-
一旦找到匹配项(在本例中为16),不会立即返回,而是阻塞,直到剩余的线程完成。在这种情况下,调用方在找到匹配项后返回之前将额外等待5秒。
-
问题内容: 在我正在研究的基于Linux的项目中,我需要能够找到我的所有子进程。每次启动时都进行记录是不可行的-需要在事实之后找到它们。这必须是纯C语言,而我想不读取/ proc就这样做。有谁知道如何做到这一点? 问题答案: 我发现您的评论认为,将进程的创建记录为奇数是不可行的,但是如果您真的做不到(可能是因为您不知道将创建多少个进程,并且不想保留内存) ),那么我可能会打开所有与该glob匹配的
-
问题内容: 我想知道一个固定时间段内一个进程和所有子进程的CPU使用率。 更具体地说,这是我的用例: 有一个过程在等待用户执行程序的请求。为了执行程序,该进程调用子进程(一次最多5个),并且每个子进程执行这些已提交程序中的1个(假设用户一次提交了15个程序)。因此,如果用户提交15个程序,则将运行3批,每批5个子进程。子进程在完成程序执行后立即被杀死。 我想知道在执行这15个程序期间,父进程及其所
-
如果我在Java8中有一个并行流,并且我以anyMatch终止,并且我的集合有一个与谓词匹配的元素,那么我将试图弄清楚当一个线程处理这个元素时会发生什么。 我知道anyMatch是短路的,这样我就不会期望一旦匹配元素被处理,就会有更多的元素被处理。我的困惑是其他线程会发生什么,这些线程大概处于处理元素的中间。我可以想到3种可能的场景:a)它们是否被中断?b)它们是否继续处理它们正在处理的元素,然后
-
问题内容: 如何在Linux和Windows中正常停止Java进程? 什么时候被调用,什么时候不被调用? 终结器又如何呢? 我可以从外壳向Java进程发送某种信号吗? 我正在寻找最好的便携式解决方案。 问题答案: 在所有未强制终止VM的情况下,都会执行关机挂钩。因此,如果要发出“标准” kill(通过kill命令),则它们将执行。同样,它们将在调用后执行。 但是,如果将其强行杀死(),它们将不会执
-
问题内容: 只会给出列表中第一个出现的项目。有没有整齐的技巧可以返回列表中的所有索引? 问题答案: 你可以使用列表理解: