
java字符串排列和组合查找

我正在编写一个 Android
word应用程序。我的代码包含一个方法,该方法将查找字符串和7个字母的字符串的子字符串的所有组合,且其最小长度为3。然后将所有可用组合与字典中的每个单词进行比较,以找到所有有效单词。我正在使用递归方法。这是代码。
// Gets all the permutations of a string.
void permuteString(String beginningString, String endingString) {
if (endingString.length() <= 1){
if((Arrays.binarySearch(mDictionary, beginningString.toLowerCase() + endingString.toLowerCase())) >= 0){
mWordSet.add(beginningString + endingString);
}
}
else
for (int i = 0; i < endingString.length(); i++) {
String newString = endingString.substring(0, i) + endingString.substring(i + 1);
permuteString(beginningString + endingString.charAt(i), newString);
}
}
// Get the combinations of the sub-strings. Minimum 3 letter combinations
void subStrings(String s){
String newString = "";
if(s.length() > 3){
for(int x = 0; x < s.length(); x++){
newString = removeCharAt(x, s);
permuteString("", newString);
subStrings(newString);
}
}
}
上面的代码运行正常,但是当我将其安装在Nexus上时,我意识到它的运行速度太慢了。这需要几秒钟才能完成。大约3或4秒,这是不可接受的。现在,我在手机上玩了一些文字游戏,它们可以立即计算出字符串的所有组合,这使我相信我的算法不是很有效,可以改进。有人可以帮忙吗?
public class TrieNode {
TrieNode a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z;
TrieNode[] children = {a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z};
private ArrayList<String> words = new ArrayList<String>();
public void addWord(String word){
words.add(word);
}
public ArrayList<String> getWords(){
return words;
}
}
public class Trie {
static String myWord;
static String myLetters = "afinnrty";
static char[] myChars;
static Sort sort;
static TrieNode myNode = new TrieNode();
static TrieNode currentNode;
static int y = 0;
static ArrayList<String> availableWords = new ArrayList<String>();
public static void main(String[] args) {
readWords();
getPermutations();
}
public static void getPermutations(){
currentNode = myNode;
for(int x = 0; x < myLetters.length(); x++){
if(currentNode.children[myLetters.charAt(x) - 'a'] != null){
//availableWords.addAll(currentNode.getWords());
currentNode = currentNode.children[myLetters.charAt(x) - 'a'];
System.out.println(currentNode.getWords() + "" + myLetters.charAt(x));
}
}
//System.out.println(availableWords);
}
public static void readWords(){
try {
BufferedReader in = new BufferedReader(new FileReader("c://scrabbledictionary.txt"));
String str;
while ((str = in.readLine()) != null) {
myWord = str;
myChars = str.toCharArray();
sort = new Sort(myChars);
insert(myNode, myChars, 0);
}
in.close();
} catch (IOException e) {
}
}
public static void insert(TrieNode node, char[] myChars, int x){
if(x >= myChars.length){
node.addWord(myWord);
//System.out.println(node.getWords()+""+y);
y++;
return;
}
if(node.children[myChars[x]-'a'] == null){
insert(node.children[myChars[x]-'a'] = new TrieNode(), myChars, x=x+1);
}else{
insert(node.children[myChars[x]-'a'], myChars, x=x+1);
}
}
}
问题答案:
在当前方法中,您正在查找每个子字符串的每个排列。因此,对"abc",你需要仰视"abc","acb","bac","bca","cab"和"cba"。如果要查找“排列”的所有排列,则查询数量接近
500,000,000 ,而这甚至还没有查看其子字符串。但是我们可以通过预处理字典将 其 减少为 一次
查询,而不论其长度如何。
想法是将字典中的每个单词放入某种数据结构中,其中每个元素包含一组字符,以及包含(仅)那些字符的所有单词的列表。因此,例如,您可以构建一个二叉树,该树将具有一个包含(排序的)字符集"abd"和单词list
的节点["bad", "dab"]。现在,如果要查找的所有排列"dba",我们将其排序以给出"abd"并在树中查找以检索列表。
正如鲍曼指出的那样,尝试非常适合存储此类数据。特里树的优点是查找时间
仅取决于搜索字符串的长度, 它 与字典的大小无关
。由于您将存储很多单词,并且您的大多数搜索字符串都很小(大多数将是递归最低级别的3个字符的子字符串),因此这种结构是理想的。
在这种情况下,指向特里的路径将反映字符集而不是单词本身。因此,如果您的整个字典是["bad", "dab", "cab", "cable"],那么您的查找结构将最终看起来像这样:
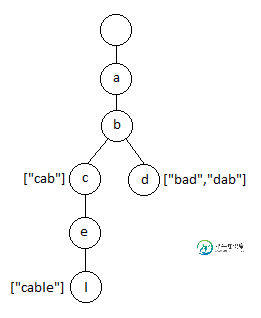
实施此方法时,需要进行一些时间/空间的权衡。在最简单(也是最快)的方法中,每个Node仅包含单词列表和一系列Node[26]子代。这样一来,您只需查看即可即可找到您要寻找的孩子children[s.charAt(i)-'a'](在哪里s,您的搜索字符串,以及i您当前在Trie中的深度)。
不利的一面是您的大多数children阵列将大部分为空。如果空间不足,可以使用更紧凑的表示形式,例如链表,动态数组,哈希表等。但是,这些代价是可能需要在每个节点上进行多次内存访问和比较,而不是简单的数组访问上方。但是,如果浪费的空间超过整个字典的几兆字节,我会感到惊讶,因此基于数组的方法可能是最好的选择。
放置特里树后,您的整个排列函数将被一次查找替换,从而使复杂度从 O(N!log D) (其中 D 是字典的大小, N
是字符串的大小)降低到 O(N log N) (因为您需要对字符进行排序;查找本身是 O(N) )。
编辑: 我把这个结构的(未测试的)实现放在一起:http :
//pastebin.com/Qfu93E80
-
问题内容: 我认为我有一个复杂的要求。 它是使用Oracle 10.2的组合排列,我能够使用笛卡尔联接来解决它,但是我认为它需要一些改进以使其更简单,更灵活。 主要行为。 输入字符串 :“一二” 输出 :’一’‘二’‘一二’‘二一’ 对于我的解决方案,我将字符串数限制为5(请注意,输出是阶乘附近的数字) SQL: 问题答案: 编辑:得到了通用的。最终真的很简单(但是花了我一段时间才到达那里) Ed
-
本文向大家介绍Java排列组合字符串的方法,包括了Java排列组合字符串的方法的使用技巧和注意事项,需要的朋友参考一下 例如 输入“abc”,打印所有可能出现的组合情况,并且消除重复值。 所谓排列组合如下: 排列组合,字符串:abc bca acb abc cba bac cab 排列组合个数:6 实现代码(结合Java8 lambda表达式实现) 如有更简洁的代码实现,请不要吝啬,贴出来分享下。
-
本文向大家介绍java实现字符串排列组合问题,包括了java实现字符串排列组合问题的使用技巧和注意事项,需要的朋友参考一下 本文为大家介绍了java实现字符串排列组合问题,供大家参考,具体内容如下 组合: 要么选择长度为n的字符串中的第一个字符,那么要在其余的长度n-1的字符串中选择m-1个字符 要么不选择长度为n的字符串中的第一个字符,那么要在其余的长度n-1的字符串中选择m个字符 以上就是本文
-
本文向大家介绍C#查找字符串所有排列组合的方法,包括了C#查找字符串所有排列组合的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#查找字符串所有排列组合的方法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的C#程序设计有所帮助。
-
问题内容: String database[] = {‘a’, ‘b’, ‘c’}; 我想基于给定生成以下字符串序列。 我只能想到一个漂亮的“虚拟”解决方案。 解决方案非常愚蠢。从某种意义上说,它是不可扩展的 如果我增加的大小怎么办? 如果我最终的目标打印字符串长度必须为N怎么办? 是否有任何智能代码可以以一种非常智能的方式生成可缩放的排列和组合字符串? 问题答案: 您应该检查以下答案:在Java
-
问题内容: 在java中查找字符串的所有排列 问题答案: 在这篇文章中,我们将看到如何在 java 中找到 String 的所有排列。 我们将使用一种非常简单的方法来做到这一点。 取出String的第一个字符,递归地插入剩余String的排列的不同位置。 假设您将 String 作为ABC。 所以我们从 ABC 中取出 A 第一个字符 =A 和 RemainingString = BC 因为我们在
-
我正在玩排序数组,我弄清楚了如何对int数组进行合并排序。但是我不知道合并字符串数组。在正常排序时,对字符串数组进行排序很容易,但合并排序不同。我到目前为止所做的代码如下,正在处理int数组。
-
本节要介绍的是Python里面常用的几种数据结构。通常情况下,声明一个变量只保存一个值是远远不够的,我们需要将一组或多组数据进行存储、查询、排序等操作,本节介绍的Python内置的数据结构可以满足大多数情况下的需求。这一部分的知识点比较多,而且较为零散,需要认真学习。 2.3.1 字符串 字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。 创建字符串很简单,只要为