
详细描述一下Elasticsearch索引文档的过程?

面试官:想了解ES的底层原理,不再只关注业务层面了。
解答:
这里的索引文档应该理解为文档写入ES,创建索引的过程。
文档写入包含:单文档写入和批量bulk写入,这里只解释一下:单文档写入流程。
记住官方文档中的这个图。
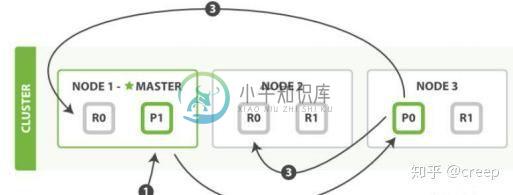
第一步:客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色。)
第二步:节点1接受到请求后,使用文档_id来确定文档属于分片0。请求会被转到另外的节点,假定节点3。因此分片0的主分片分配到节点3上。
第三步:节点3在主分片上执行写操作,如果成功,则将请求并行转发到节点1和节点2的副本分片上,等待结果返回。所有的副本分片都报告成功,节点3将向协调节点(节点1)报告成功,节点1向请求客户端报告写入成功。
如果面试官再问:第二步中的文档获取分片的过程?
回答:借助路由算法获取,路由算法就是根据路由和文档id计算目标的分片id的过程。
shard = hash(_routing) % (num_of_primary_shards)
-
本文向大家介绍详细描述一下 Elasticsearch 索引文档的过程。相关面试题,主要包含被问及详细描述一下 Elasticsearch 索引文档的过程。时的应答技巧和注意事项,需要的朋友参考一下 协调节点默认使用文档 ID 参与计算(也支持通过 routing),以便为路由提供合适的分片。 shard = hash(document_id) % (num_of_primary_shards)
-
本文向大家介绍详细描述一下Elasticsearch搜索的过程?相关面试题,主要包含被问及详细描述一下Elasticsearch搜索的过程?时的应答技巧和注意事项,需要的朋友参考一下 面试官:想了解ES搜索的底层原理,不再只关注业务层面了。 解答: 搜索拆解为“query then fetch” 两个阶段。 query阶段的目的:定位到位置,但不取。 步骤拆解如下: 1)假设一个索引数据有5主+1
-
本文向大家介绍详细描述一下 Elasticsearch 搜索的过程?相关面试题,主要包含被问及详细描述一下 Elasticsearch 搜索的过程?时的应答技巧和注意事项,需要的朋友参考一下 1、搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch; 2、在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为
-
本文向大家介绍详细描述一下 Elasticsearch 更新和删除文档的过程。相关面试题,主要包含被问及详细描述一下 Elasticsearch 更新和删除文档的过程。时的应答技巧和注意事项,需要的朋友参考一下 1、删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更; 2、磁盘上的每个段都有一个相应的.del 文件。当删除请求发送后,文
-
> 下载了。90.6,解压缩,将弹性搜索移动到/usr/share/elasticsearch(在centosx64 6.4上具有chmod 777-r权限),将集群重命名为somethingdupd,并启动服务器。 根据文档,我应该能够做到这一点。但它也什么也不做:
-
本文向大家介绍Bash中文件描述符的详细介绍,包括了Bash中文件描述符的详细介绍的使用技巧和注意事项,需要的朋友参考一下 前言 Linux将所有内核对象当做文件来处理,系统用一个size_t类型来表示一个文件对象,比如对于文件描述符0就表示系统的标准输入设备STDIN,通常情况下STDIN的值为键盘,如read命令就默认从STDIN读取数据,当然STDIN的值是可以改变的,比如将其改成其他文件,