
BIO (Blocking I/O)?

同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。
1.1 传统 BIO
BIO通信(一请求一应答)模型图如下(图源网络,原出处不明):
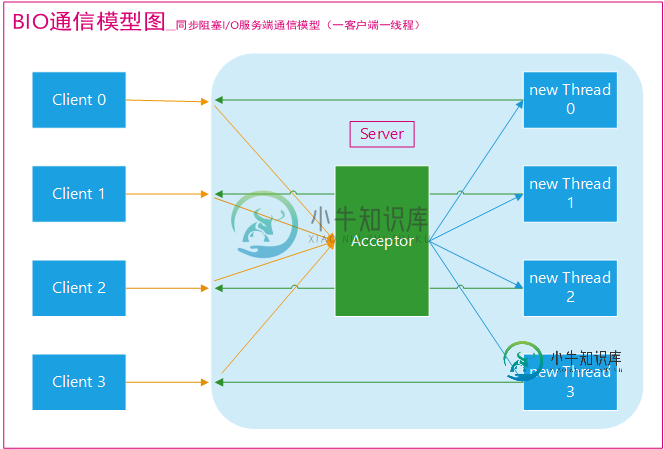
采用 BIO 通信模型 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。我们一般通过在while(true) 循环中服务端会调用 accept() 方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接,如上图所示。
如果要让 BIO 通信模型 能够同时处理多个客户端请求,就必须使用多线程(主要原因是socket.accept()、socket.read()、socket.write() 涉及的三个主要函数都是同步阻塞的),也就是说它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的 一请求一应答通信模型 。我们可以设想一下如果这个连接不做任何事情的话就会造成不必要的线程开销,不过可以通过 线程池机制 改善,线程池还可以让线程的创建和回收成本相对较低。使用FixedThreadPool 可以有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型(N 可以远远大于 M),下面一节"伪异步 BIO"中会详细介绍到。
我们再设想一下当客户端并发访问量增加后这种模型会出现什么问题?
在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
1.2 伪异步 IO
为了解决同步阻塞I/O面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化一一一后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N.通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。
伪异步IO模型图(图源网络,原出处不明):
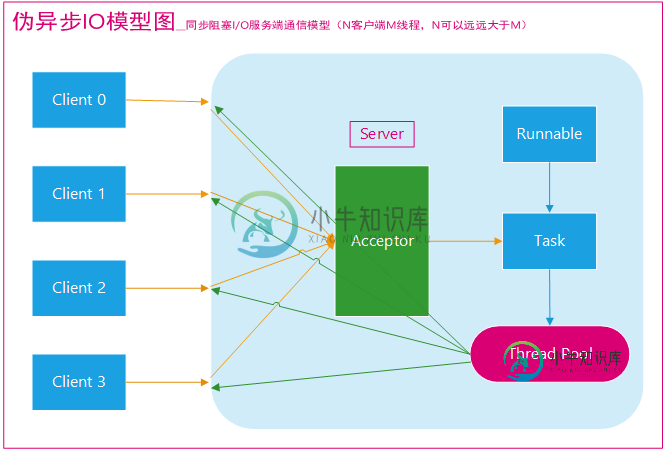
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示。当有新的客户端接入时,将客户端的 Socket 封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层仍然是同步阻塞的BIO模型,因此无法从根本上解决问题。
1.3 代码示例
下面代码中演示了BIO通信(一请求一应答)模型。我们会在客户端创建多个线程依次连接服务端并向其发送"当前时间+:hello world",服务端会为每个客户端线程创建一个线程来处理。代码示例出自闪电侠的博客,原地址如下:
https://www.jianshu.com/p/a4e03835921a
客户端
`java
/**
@author 闪电侠
@date 2018年10月14日
@Description:客户端
*/
public class IOClient {
public static void main(String[] args) {
// TODO 创建多个线程,模拟多个客户端连接服务端
new Thread(() -> {
try {
Socket socket = new Socket("127.0.0.1", 3333);
while (true) {
try {
socket.getOutputStream().write((new Date() + ": hello world").getBytes());
Thread.sleep(2000);
} catch (Exception e) {
}
}
} catch (IOException e) {
}
}).start();
}
}
`
服务端
`java
/**
@author 闪电侠
@date 2018年10月14日
@Description: 服务端
/
public class IOServer {
public static void main(String[] args) throws IOException {
// TODO 服务端处理客户端连接请求
ServerSocket serverSocket = new ServerSocket(3333);
new Thread(() -> {
while (true) {
try {
// 阻塞方法获取新的连接
Socket socket = serverSocket.accept();
// 每一个新的连接都创建一个线程,负责读取数据
new Thread(() -> {
try {
int len;
byte[] data = new byte[1024];
InputStream inputStream = socket.getInputStream();
// 按字节流方式读取数据
while ((len = inputStream.read(data)) != -1) {
System.out.println(new String(data, 0, len));
}
} catch (IOException e) {
}
}).start();
} catch (IOException e) {
}
}
}).start();
}
}// 接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理
1.4 总结
在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
-
Rust-Bio 是一个使用 Rust 实现的生物信息学工具库。Rust-Bio 包括大量的算法和数据结构,对生物信息学非常有帮助。Rust-Bio 通过持续集成进行测试,值得信赖。 当前 Rust-Bio 提供: 大部分主要模式匹配算法 一个方便的字母表实现 两两配对 后缀数组 BWT 和 FM-Index q-gram 索引 rank/select 数据结构 示例: // Import
-
Bio-Linux是功能齐全的、强大的、可定制的、易于维护的生物分析工作站。Bio-Linux基于Ubuntu提供500多个生物分析程序,由一个 图形化的菜单进行管理,能方便地访问到其生物分析文档系统及对测试程序有用的样本数据。用于处理新型序列数据类型的Bio-Linux软件包可额外安装。
-
本文向大家介绍BIO,NIO,AIO 有什么区别?相关面试题,主要包含被问及BIO,NIO,AIO 有什么区别?时的应答技巧和注意事项,需要的朋友参考一下 BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。 NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复
-
接收器的方法似乎没有办法使异步io?例如返回? 例如,redis连接器使用jedis lib同步执行redis命令: https://github.com/apache/bahir-flink/blob/master/flink-connector-redis/src/main/java/org/apache/flink/streaming/connectors/redis/RedisSink.j
-
我目前正在完成一个客户网站的工作,我希望作者的简历出现在单篇文章的底部。唯一的问题是,我只想在填写用户简历的前端显示此部分。我很快就能让它工作了,但是由于某种原因,当bio部分包含副本时,下面代码中的内容没有显示在前端。 任何帮助都将不胜感激。谢谢