
db设计评论家/建议

我正在重新设计一个药房数据库系统,需要输入以查看新设计是否最佳或需要调整。
这是旧系统的快照。
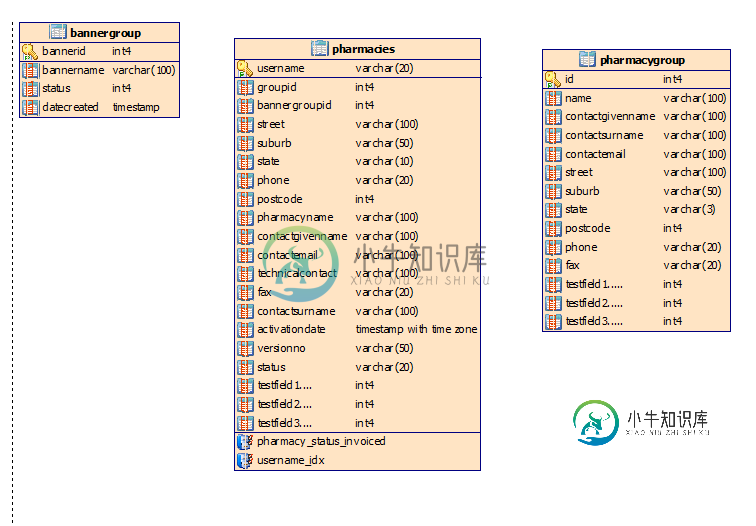
可以看到,药房表存储药房信息以及其地址和联系信息。出于开票目的,药店被分组在一起(药房组),或者出于销售目的,将广告用于其他目的(横幅组)。发票组可以具有不同的物理地址,不同的联系信息。
这是我的新设计。我已将地址从pharmacy和pharmacygroup表中拆分成一个自己的表,并为联系人创建了一个新表。他们可以是技术联系人,客户联系人,所有者联系人等,因此可以是contacttypes表。药房和药房集团可以有单独的联系信息,我想到要制作一个单独的联系表,并有一个“
linktype”和“
linkid”列以指示其是药房联系人还是药房组联系人,但是我不确定这是否是正确的方法。这是一个好的设计,还是由于连接的数量而导致的数据检索成本高昂?我注意到的另一件事是,在旧的设计中,它们没有创建任何外键约束,尽管药房表中有针对pharmacygroup和bannergroup的groupid和bannergroupid引用,可能会节省数据检索的时间。这是一个好方法吗?
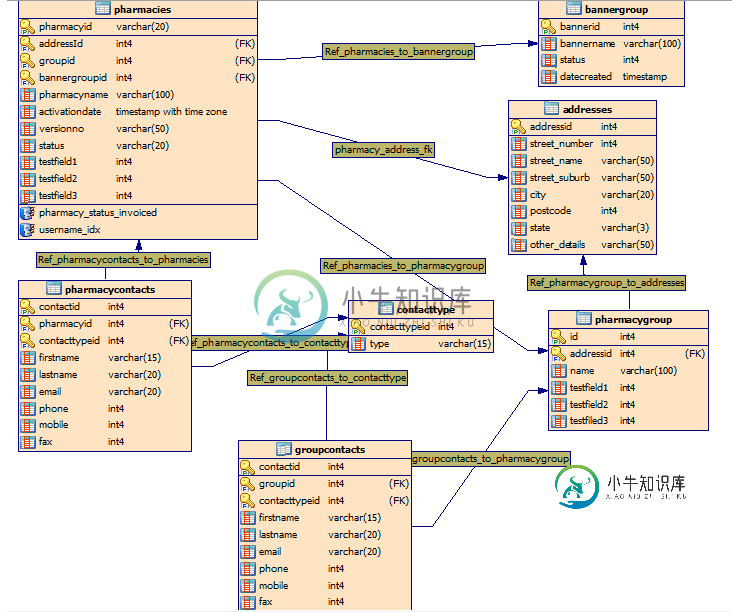
问题答案:
您的设计对我来说很好。我总是更喜欢在设计步骤中加入一些额外的连接,而不是花时间在系统投入生产后重新组织数据。您永远不会事先知道管理层/销售人员/财务人员会要求什么样的报告,而适当的关系设计将为您提供更多的自由。
同样,您不能仅将几个额外的JOINs归咎于您的性能问题。您应该始终注意:
- 数据量(和物理数据布局),
- 交易金额和密度,
- I / O,CPU,内存使用率,
- 您的RDBMS配置,
- SQL查询质量。
我认为JOINs将在此列表的底部。
关于RI约束(参照完整性),我已经看到了几个没有任何主键/外键来运行以提高性能的项目。主要借口是:我们将所有检查都嵌入到
应用程序中, 而 应用程序 是系统中任何更改的唯一来源。另一方面,他们同意,尚不清楚系统是否处于一致状态(实际上,分析表明它们不是)。
我始终坚持在设计状态上创建所有可能的键/约束,因为周围总是会有一些流氓'',他们会挖掘您的数据库并调整’‘看起来更合适的数据。不过,您可能想暂时禁用甚至放弃一些用于批量数据操作的约束/索引,这也是官方建议。
如果不确定,则创建2个测试数据库,一个有约束,另一个无约束。加载一些数据并比较查询性能。我认为这将是相似的。
在这里,我对您的草图的评论,决定全由您决定。
- 您可能希望创建一个普通的
contacts表你做了同样的方式addresses,即加contact_id,owner_contact_id等列到目标的关系,而不是引用来自关系contacts表; - 由于
contacttype表中只有一列(以防万一contacts),因此最好将唯一的字段移开并避免使用此表。 - 您的表似乎混合使用单/复数名称,最好在此处坚持使用通用模式。我个人更喜欢单数。
- 在
pharmacygroup您的PK中命名为id,而所有其他PK都遵循tableid模式,如果以后在此处使用通用模式,则以后编写脚本会更容易。 - 在
addresses表中,您有带下划线的字段,例如street_name,而在其他地方则避免_使用…考虑使其通用; -
引用的名称不同。尽管不是很重要,但我确实有几个系统必须依靠约束的名称,因此最好在这里使用一些模式。我使用以下之一:
- 前缀
p_,f_,c_,t_,u_或i_小学,外键,检查约束,触发器,独特等指标; - 表名;
- 列约束/索引/触发器所引用的名称。
- 前缀
为什么我更喜欢用单数形式命名表?因为我总是使用table_id模式命名PK
,所以IMHOpharmacy_id看起来更好pharmacies_id。我使用这种方法是因为我有一堆通用脚本,这些脚本在将数据加载到主表之前执行数据一致性检查时都依赖于此模式。
编辑: 更多关于联系人。您可以contact_id在所有表中使用它,使其成为 主要联系人
,无论这对您的应用程序可能意味着什么。如果您需要更多的接触是有一些关系,那么你可以用不同的前缀,比如去owner_contact_id,sales_contact_id等等。
如果您希望为某种关系而存在大量联系人,例如pharmacygroup,则可以添加一个额外的表,如下所示:
CREATE TABLE pharmacygroupcontact (
contactid int4,
groupid int4,
contact_desc text
);
它部分复制了您groupcontacts的姓名缩写,但由两个FK和一个说明组成。我不知道哪种方法更好,因为我不知道应用程序是如何设计的。
-
PATCH /feeds/:feed/comment-paid Input 名称 类型 描述 amount Integer 收费金额 Response Status: 201 Created { "message": [ "设置成功" ], "paid_node": 11 }
-
请求header POST /v1/activity/{频道id}/comments/{评论id}/top Authorization:Bearer {ACCESS TOKEN} Content-Type:application/json 注: 请将上方的{ACCESS TOKEN}替换为您的ACCESS TOKEN 请将"{频道id}"替换为您的频道id 请将"{评论id}"替换您需要置顶/取
-
我正在尝试在DynamoDB中实现像Instagram和Facebook这样的点赞和评论系统 我有3个表,user,photo和photo_likes 用户表和照片表具有user_id和photo_id键。
-
获取所有评论 GET /comments 请求查询参数: 名字 类型 描述 limit integer 可选,本次请求需要返回的数据条数。 index integer 可选,查询开始的评论位置,来源响应 id 字段。 direction string 可选,数据排序方向,以 id 进行排序,支持 asc 或 desc,默认 desc。 author integer 可选,需要筛选的评论作者,传递
-
评论一条资讯 获取一条资讯的评论列表 删除一条资讯评论 评论一条资讯 POST /news/{news}/comments 参数 名称 描述 body 评论内容 reply_user 被回复用户id 默认为0 Response Headers Status: 201 Created { "message": [ "操作成功" ], "comment": { "use
-
获取问题评论列表 获取回答评论列表 评论问题 评论答案 删除问题评论 删除回答评论 获取问题评论列表 GET /questions/:question/comments 参数 名称 类型 描述 limit Integer 默认 20 ,获取列表条数,修正值 1 - 30。 after integer 默认 0 ,筛选偏移, 上一次获取的评论列表中最后一条的id 响应 Status: 200 OK