
将STUFF与INNER JOIN查询一起使用

我的数据库中有三个表。产品表,类型表和映射表Prod_Type。我的数据库是sql
server,这就是为什么我不能使用group_concat函数而使用Stuff函数的原因。我的表结构如下
产品表
Prod_ID | Name | Brand
------- ---- -----
1 | Name1 | Brand1
2 | Name2 | Brand2
3 | Name3 | Brand3
4 | Name4 | Brand4
5 | Name5 | Brand5
6 | Name6 | Brand6
7 | Name7 | Brand7
类型表
Type_ID | TypeName
------- --------
1 | TypeName1
2 | TypeName2
3 | TypeName3
4 | TypeName4
5 | TypeName5
Prod_TypeTable
Prod_IDM | Type_ID
-------- -------
1 | 1
1 | 3
1 | 4
1 | 5
2 | 2
2 | 3
3 | 4
4 | 5
4 | 1
5 | 4
5 | 3
5 | 2
6 | 2
6 | 3
7 | 5
我能够将产品表加入到Prod_type的映射表中。我使用了东西查询来避免出现多个结果。我的查询是这样的:
Select
top 5 *
from ProductTable
inner Join (SELECT
Prod_IDM,
STUFF((SELECT ', ' + CAST(Type_ID AS VARCHAR(10)) [text()]
FROM Prod_TypeTable
WHERE Prod_IDM = t.Prod_IDM FOR XML PATH(''), TYPE)
.value('.','NVARCHAR(MAX)'),1,2,' ') TypeID
FROM Prod_TypeTable t
GROUP BY Prod_IDM ) As TypeList on TypeList.Prod_IDM = ProductTable.Prod_ID
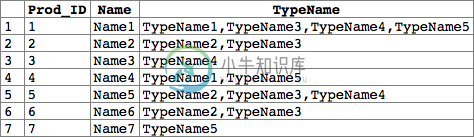
我现在需要做的是将我先前的查询结果连接到类型表中,以便能够分别获取类型的名称。我应该怎么做呢?我的预期输出将是这样的
Prod_ID | Name | TypeName
------- ---- ---------
1 | Name1 | TypeName1, TypeName3, TypeName4, TypeName5
2 | Name2 | TypeName2, TypeName3
3 | Name3 | TypeName4
4 | Name4 | TypeName5, TypeName1
5 | Name5 | TypeName4, TypeName3, TypeName2
6 | Name6 | TypeName2, TypeName3
7 | Name7 | TypeName5
问题答案:
至少对于没有STRING_AGG功能的早期版本,在SQL
Server中很难用组串联查询来表达。诀窍在于,外部查询应该作用于表,这些表的键具有要合并到一个或多个其他表中而要聚合的值。在这种情况下,我们放在ProductTable外面,然后汇总其他所有内容,以生成每种产品的CSV类型列表。
SELECT
p.Prod_ID,
p.Name,
TypeName = STUFF((
SELECT ',' + t.TypeName
FROM Prod_TypeTable pt
INNER JOIN TypeTable t
ON pt.Type_ID = t.Type_ID
WHERE pt.Prod_IDM = p.Prod_ID
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1, '')
FROM ProductTable p
ORDER BY p.Prod_ID;
演示版
-
问题内容: 我已经看到了许多有关在Sql查询中使用参数和“赞”的问题,但是我尝试了各种方法来对其进行编码,但仍然无法使我的查询给出结果。如果我在查询本身中输入一个值,它会很好地运行。当我运行列出的第一个查询时,出现错误“必须声明标量变量“ @Search”,但我认为我使用cmd.Parameters.AddWithValue语句做到了。有人可以看到我可能在做错什么吗?感谢您的任何帮助。 问题答案:
-
问题内容: 当需要有序集的最后一行时,通常会创建派生表并重新排序。例如,要以自动递增的方式返回表的最后3个元素: 由于也可以具有偏移量,因此如果我们事先知道此查询的行数(例如10),则可以实现相同的结果: 是否可以对表运行子查询并使用该数字动态构建一个? 问题答案: 不,不可能指定动态偏移量。 带有子查询的原始查询是执行此操作的最简单方法。
-
问题内容: 我正在尝试使用hibernate条件查询在三个字段上执行基本的“或”操作。 例 我想建立一个条件查询,其中我的搜索字符串可以匹配“名称”或“地址”或“ phoneNumber”。 问题答案: 您要使用。像这样 请在此处查看Hibernate文档。
-
在我的索引中。js文件 在路由器文件中 邮递员: 我的GET URL如下所示:<代码>http://localhost:3000/api/v1/users?id=120622 它给出的错误: 我认为,根据我遵循的文档和教程,查询参数应该是这样给出的,但这个错误不会消失。 如果我删除了查询,那么其他endpoint就可以正常工作。 我搞不清楚这里出了什么问题。 我在过去的两天里一直被这个困扰着。只是
-
问题内容: 我有一个MySQL UPDATE查询,需要很长时间才能完成。我是否错过了一种更简单的方法来获得相同的结果? 包含的所有可能值,每个值仅包含一条记录。 包含的一些值,但是有多个记录有一些值。 我需要更新记录中显示的相应值的出现次数中。上面的查询完成了该工作,但是当table1包含500条记录和30,000条记录时,大约需要3分钟。我有更大的表要处理,所以这太长了:) 提前致谢。 问题答案
-
问题内容: 我有一个查询来获取搜索结果,效果很好。 成功查询的示例: 从现在开始,我每个人都有一个以上的记录,这是我想要获得MAX值(最新ID)的地方。 我尝试了许多不同的查询,但始终收到错误消息 _ ,在非对象上调用成员函数rowCount()。_ 我了解该错误的含义,但我无法弄清楚该错误的出处和总体上的错误。 我未成功尝试的示例: 我在这里想念什么?有什么帮助吗? 问题答案: 这是你的条款: