
Client API
1. 首先需要先启动canal server,可参见:Canal Server的QuickStart
2. 运行canal client,可参见:canal client的ClientExample
如何下载
1. 如果是maven用户,可配置mvn dependency
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>x.y.z</version>
</dependency>对应的version版本,可见https://github.com/alibaba/canal/releases
2. 其他用户,可通过mvn仓库直接下载jar包
mvn仓库下载url : http://central.maven.org/maven2/com/alibaba/otter/canal.client/
选择对应的version,下载jar/source/javadoc文件即可.
类设计
在了解具体API之前,需要提前了解下canal client的类设计,这样才可以正确的使用好canal.
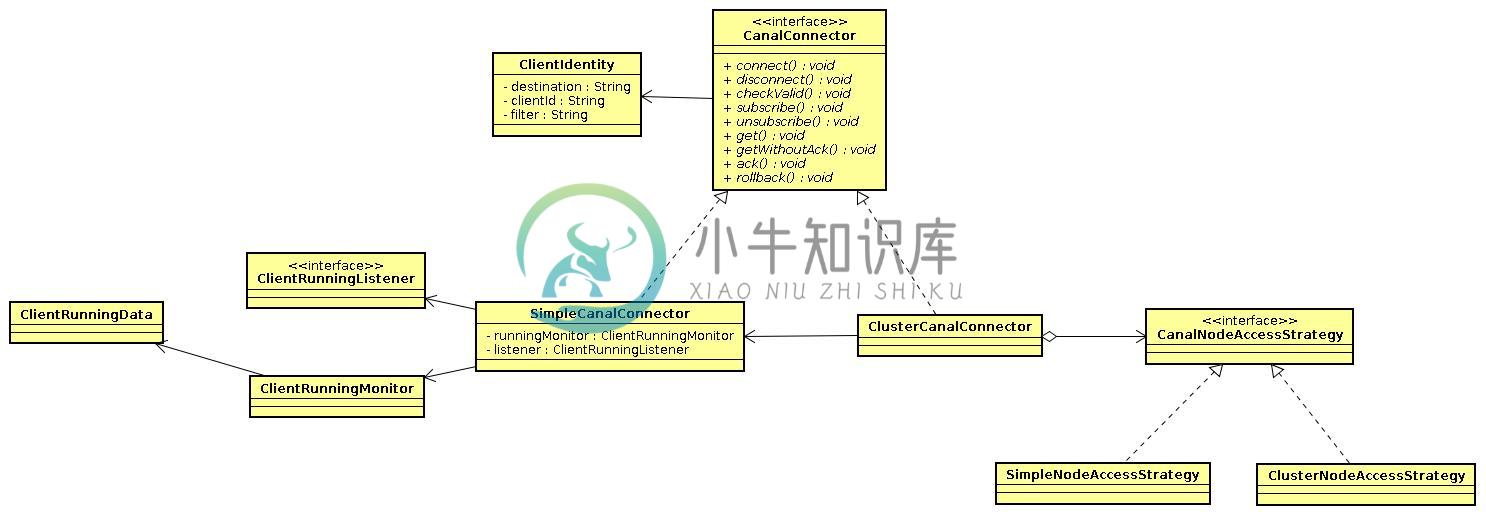
大致分为几部分:
- ClientIdentity
canal client和server交互之间的身份标识,目前clientId写死为1001. (目前canal server上的一个instance只能有一个client消费,clientId的设计是为1个instance多client消费模式而预留的,暂时不需要理会) - CanalConnector
SimpleCanalConnector/ClusterCanalConnector : 两种connector的实现,simple针对的是简单的ip直连模式,cluster针对多ip的模式,可依赖CanalNodeAccessStrategy进行failover控制 - CanalNodeAccessStrategy
SimpleNodeAccessStrategy/ClusterNodeAccessStrategy:两种failover的实现,simple针对给定的初始ip列表进行failover选择,cluster基于zookeeper上的cluster节点动态选择正在运行的canal server. - ClientRunningMonitor/ClientRunningListener/ClientRunningData
client running相关控制,主要为解决client自身的failover机制。canal client允许同时启动多个canal client,通过running机制,可保证只有一个client在工作,其他client做为冷备. 当运行中的client挂了,running会控制让冷备中的client转为工作模式,这样就可以确保canal client也不会是单点. 保证整个系统的高可用性.
javadoc查看:
- CanalConnector :http://alibaba.github.io/canal/apidocs/1.0.13/com/alibaba/otter/canal/client/CanalConnector.html
server/client交互协议
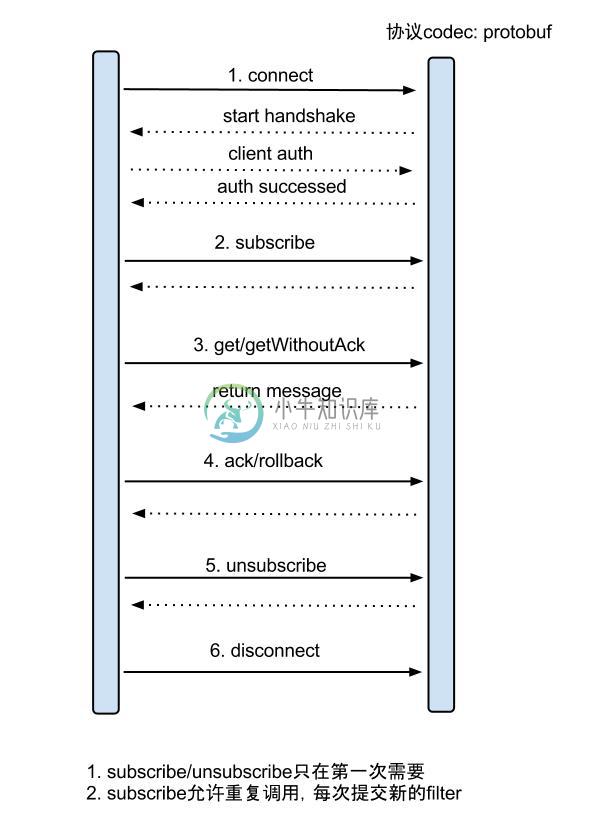
get/ack/rollback协议介绍:
- Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,可参见下面的数据介绍 - getWithoutAck(int batchSize, Long timeout, TimeUnit unit),相比于getWithoutAck(int batchSize),允许设定获取数据的timeout超时时间
a. 拿够batchSize条记录或者超过timeout时间
b. timeout=0,阻塞等到足够的batchSize - void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
- void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
流式api设计的好处:
- get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
- get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化. (作者在实际业务中的一个case:业务数据消费需要跨中美网络,所以一次操作基本在200ms以上,为了减少延迟,所以需要实施并行化)
流式api设计:
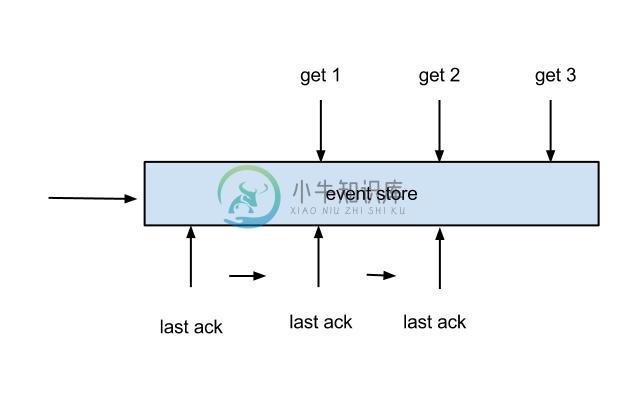
- 每次get操作都会在meta中产生一个mark,mark标记会递增,保证运行过程中mark的唯一性
- 每次的get操作,都会在上一次的mark操作记录的cursor继续往后取,如果mark不存在,则在last ack cursor继续往后取
- 进行ack时,需要按照mark的顺序进行数序ack,不能跳跃ack. ack会删除当前的mark标记,并将对应的mark位置更新为last ack cursor
- 一旦出现异常情况,客户端可发起rollback情况,重新置位:删除所有的mark, 清理get请求位置,下次请求会从last ack cursor继续往后取
流式api带来的异步响应模型: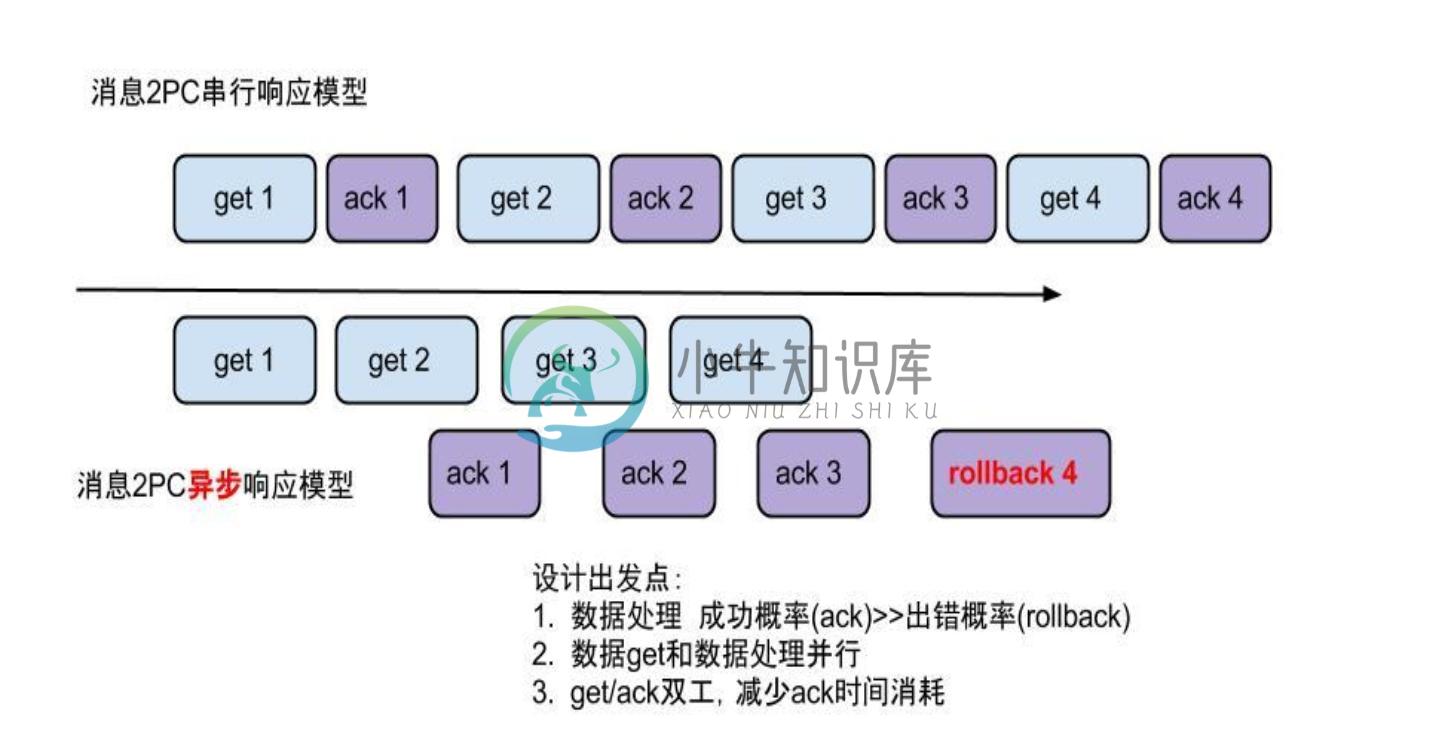
数据对象格式简单介绍:EntryProtocol.proto
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳,精确到秒]
schemaName
tableName
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组,变更前的数据字段]
afterColumns [Column类型的数组,变更后的数据字段]
Column
index
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为string文本] 说明:
- 可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name,isKey等信息进行补全
- 可以提供ddl的变更语句
- insert只有after columns, delete只有before columns,而update则会有before / after columns数据.
Client使用例子
1. 创建Connector
a. 创建SimpleCanalConnector (直连ip,不支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),11111), destination, "", "");b. 创建ClusterCanalConnector (基于zookeeper获取canal server ip,支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newClusterConnector("10.20.144.51:2181", destination, "", "");c. 创建ClusterCanalConnector (基于固定canal server的地址,支持固定的server ip的failover机制,不支持client的failover机制CanalConnector connector = CanalConnectors.newClusterConnector(Arrays.asList(new InetSocketAddress(AddressUtils.getHostIp(),11111)), destination,"", "");
2. get/ack/rollback使用
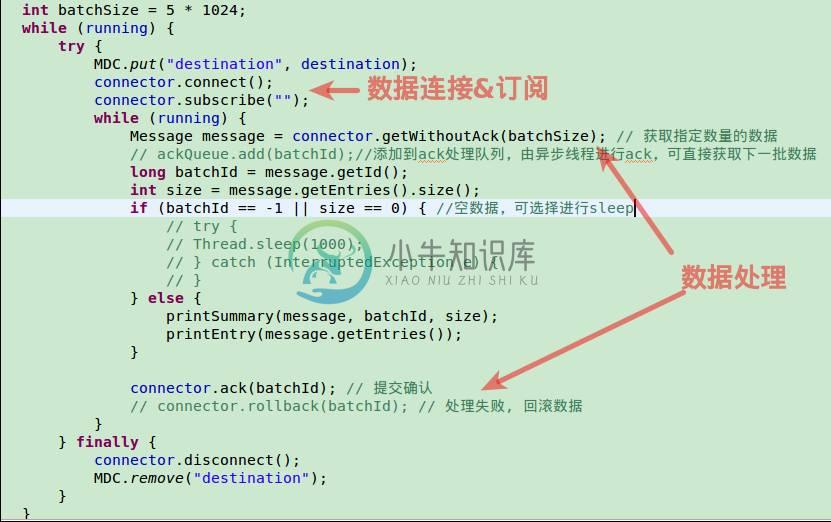
3. RowData数据处理

如果需要更详细的exmpale例子,请下载canal当前最新源码包,里面有个example工程,谢谢.
- Simple客户端例子:SimpleCanalClientTest
- Cluster客户端例子:ClusterCanalClientTest