
第七章 缓存
7.1 程序如何运行
为了理解缓存,你需要理解计算机如何运行程序。你应该学习计算机体系结构来深入理解这个话题。这一章中我的目标是给出一个程序执行的简单模型。
当程序启动时,代码(或者程序文本)通常位于硬盘上。操作系统创建新的进程来运行程序,之后“加载器”将代码从存储器复制到主存中,并且通过调用main来启动程序。
在程序运行之中,它的大部分数据都储存在主存中,但是一些数据在寄存器中,它们是CPU上的小型储存单元。这些寄存器包括:
- 程序计数器(PC),它含有程序下一条指令(在内存中)的地址。
- 指令寄存器(IR),它含有当前执行的指令的机器码。
- 栈指针(SP),它含有当前函数栈帧的指针,其中包含函数参数和局部变量。
- 程序当前使用的存放数据的通用寄存器。
- 状态寄存器,或者位寄存器,含有当前计算的信息。例如,位寄存器通常含有一位来存储上个操作是否是零的结果。
在程序运行之中,CPU执行下列步骤,叫做“指令周期”:
- 取指(Fetch):从内存中获取下一条指令,储存在指令寄存器中。
- 译码(Decode):CPU的一部分叫做“控制单元”,将指令译码,并向CPU的其它部分发送信号。
- 执行(Execute):收到来自控制单元的信号后会执行合适的计算。
大多数计算机能够执行几百条不同的指令,叫做“指令集”。但是大多数指令可归为几个普遍的分类:
- 加载:将内存中的值送到寄存器。
- 算术/逻辑:从寄存器加载操作数,执行算术运算,并将结果储存到寄存器。
- 储存:将寄存器中的值送到内存。
- 跳转/分支:修改程序计数器,使控制流跳到程序的另一个位置。分支通常是有条件的,也就是说它会检查位寄存器中的旗标,只在设置时跳转。
一些指令集,包括普遍的x86,提供加载和算术运算的混合指令。
在每个指令周期中,指令从程序文本处读取。另外,普通程序中几乎一半的指令都用于储存或读取数据。计算机体系结构的一个基础问题,“内存瓶颈”就在这里。
在当前的台式机上,CPU通常为2GHz,也就是说每0.5ns就会初始化一条新的语句。但是它用于从内存中传送数据的时间约为10ns。如果CPU需要等10ns来抓取下一条指令,再等10ns来加载数据,它可能需要40个时钟周期来完成一条指令。
7.2 缓存性能
这一问题的解决方案,或者至少是一部分的解决方案,就是缓存。“缓存”是CPU上小型、快速的储存空间。在当前的计算机上,储存通常为1~2MiB,访问速度为1~2ns。
当CPU从内存中读取数据时,它将一份副本存到缓存中。如果再次读取相同的数据,CPU就直接读取缓存,不用再等待内存了。
当最后缓存满了的时候,为了能让新的数据进来,我们需要将一些数据扔掉。所以如果CPU加载数据之后,过了一段时间再来读取,数据就可能不在缓存中了。
许多程序的性能受限于缓存的效率。如果CPU所需的数据通常在缓存中,程序可以以CPU的全速来运行。如果CPU时常需要不在缓存中的数据,程序就会受限于内存的速度。
缓存的“命中率”h,是内存访问时,在缓存中找到数据的比例。“缺失率”m,是内存访问时需要访问内存的比例。如果Th是处理缓存命中的时间,Tm是缓存未命中的时间,每次内存访问的平均时间是:
h * Th + m * Tm
同样,我们可以定义“缺失惩罚”,它是处理缓存未命中所需的额外时间,Tp = Tm - Th,那么平均访问时间就是:
Th + m * Tp
当缺失率很低时平均访问时间趋近于Th,也就是说,程序可以表现为内存具有缓存的速度那样。
7.3 局部性
当程序首次读取某个字节时,缓存通常加载一“块”或一“行”数据,包含所需的字节和一些相邻数据。如果程序继续读取这些相邻数据,它们就已经在缓存中了。
例如,假设块大小是64B,你读取一个长度为64的字符串,字符串的首个字节恰好在块的开头。当你加载首个字节之后,你触发了缺失惩罚,但是之后字符串的剩余部分都在缓存中。在读取整个字符串之后,命中率是63/64。如果字符串被分在两个块中,你应该会触发两次缺失惩罚。但是这个命中率是62/64,约为97%。
另一方面,如果程序不可预测地跳来跳去,从内存中零散的位置读取数据,很少两次访问到相同的位置,缓存的性能就会很低。
程序使用相同数据多于一次的倾向叫做“时间局部性”。使用相邻位置的数据的倾向叫做“空间局部性”。幸运的是,许多程序天生就带有这两种局部性:
- 许多程序含有非跳转或分支的代码块。在这些代码块中指令顺序执行,访问模式具有空间局部性。
- 在循环中,程序执行多次相同指令,所以访问模式具有时间局部性。
- 一条指令的结果通常用于下一指令的操作数,所以数据访问模式具有时间局部性。
- 当程序执行某个函数时,它的参数和局部变量在栈上储存在一起。这些值的访问具有空间局部性。
- 最普遍的处理模型之一就是顺序读写数组元素。这一模式也具有空间局部性。
下一节中我们会探索程序的访问模式和缓存性能的关系。
7.4 缓存性能的度量
当我还是UC伯克利的毕业生时,我是Brian Harvey计算机体系结构课上的助教。我最喜欢的练习之一涉及到一个迭代数组,读写元素并度量平均时间的程序。通过改变数组的大小,就有可能推测出缓存的大小,块的大小,和一些其它属性。
我的这一程序的修改版本在本书仓库的cache目录下。
程序的核心部分是个循环:
iters = 0;
do {
sec0 = get_seconds();
for (index = 0; index < limit; index += stride)
array[index] = array[index] + 1;
iters = iters + 1;
sec = sec + (get_seconds() - sec0);
} while (sec < 0.1);
内部的for循环遍历了数组。limit决定数组遍历的范围。stride决定跳过多少元素。例如,如果limit是16,stride是4,循环就会访问0、4、8、和12。
sec跟踪了CPU用于内循环的的全部时间。外部循环直到sec超过0.1秒才会停止,这对于我们计算出平均时间所需的精确度已经足够长了。
get_seconds使用系统调用clock_gettime,将结果换算成秒,并且以double返回结果。
double get_seconds(){
struct timespec ts;
clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &ts);
return ts.tv_sec + ts.tv_nsec / 1e9;
}
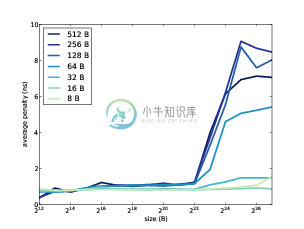
图 7.1:数据大小和步长的平均缺失惩罚函数
为了将访问数据的时间分离出来,程序运行了第二个循环,它除了内循环不访问数据之外完全相同。它总是增加相同的变量:
iters2 = 0;
do {
sec0 = get_seconds();
for (index = 0; index < limit; index += stride)
temp = temp + index;
iters2 = iters2 + 1;
sec = sec - (get_seconds() - sec0);
} while (iters2 < iters);
第二个循环运行和第一个循环相同数量的迭代。在每轮迭代之后,它从sec中减少了消耗的时间。当循环完成时,sec包含了所有数组访问的总时间,减去用于增加temp的时间。其中的差就是所有访问触发的全部缺失惩罚。最后,我们将它除以访问总数来获取每次访问的平均缺失惩罚,以ns为单位:
sec * 1e9 / iters / limit * stride
如果你编译并运行cache.c,你应该看到这样的输出:
Size: 4096 Stride: 8 read+write: 0.8633 ns
Size: 4096 Stride: 16 read+write: 0.7023 ns
Size: 4096 Stride: 32 read+write: 0.7105 ns
Size: 4096 Stride: 64 read+write: 0.7058 ns
如果你安装了Python和Matplotlib,你可以使用graph_data.py来使结果变成图形。图7.1展示了我运行在Dell Optiplex 7010上的结果。要注意数组大小和步长以字节为单位表述,并不是数组元素数量。
花一分钟来考虑这张图片,并且看看你是否能推断出缓存信息。下面是一些需要思考的事情:
- 程序多次遍历并读取数组,所以有大量的时间局部性。如果整个数组能放进缓存,平均缺失惩罚应几乎为0。
- 当步长是4的时候,我们读取了数组的每个元素,所以程序有大量的空间局部性。例如,如果块大小足以包含64个元素,即使数组不能完全放在缓存中,命中率应为63/64。
- 如果步长等于块的大小(或更大),空间局部性应为0,因为每次我们读取一个块的时候,我们只访问一个元素。这种情况下,我们会看到最大的缺失惩罚。
总之,如果数组比缓存大小更小,或步长小于块的大小,我们认为会有良好的缓存性能。如果数组大于缓存大小,并且步长较大时,性能只会下降。
在图7.1中,只要数组小于2 ** 22字节,缓存性能对于所有步长都很好。我们可以推测缓存大小近似4MiB。实际上,根据规范应该是3MiB。
当步长为8、16或32B时,缓存性能良好。在64B时开始下降,对于更大的步长,平均缺失惩罚约为9ns。我们可以推断出块大小为128B。
许多处理器都使用了“多级缓存”,它包含一个小型快速的缓存,和一个大型慢速的缓存。这个例子中,当数组大小大于2 ** 14B时,缺失惩罚似乎增长了一点。所以这个处理器可能也拥有一个访问时间小于1ns的16KB缓存。
7.5 缓存友好的编程
内存的缓存功能由硬件实现,所以多数情况下程序员都不需要知道太多关于它的东西。但是如果你知道缓存如何工作,你就可以编写更有效利用它们的程序。
例如,如果你在处理一个大型数组,只遍历数组一次,在每个元素上执行多个操作,可能比遍历数组多次要快。
如果你处理二维数组,它以行数组的形式储存。如果你需要遍历元素,按行遍历并且步长为元素大小会比按列遍历并且步长为行的大小更快。
链表数据结构并不总具有空间局部性,因为节点在内存中并不一定是连续的。但是如果你同时分配了很多个节点,它们在堆中通常分配到一起。或者,如果你一次分配了一个节点数组,你应该知道它们是连续的,这样会更好。
类似归并排序的递归策略通常具有良好的缓存行为,因为它们将大数组划分为小片段,之后处理这些小片段。有时这些算法可以调优来利用缓存行为。
对于那些性能至关重要的应用,可以设计适配缓存大小、块大小以及其它硬件特征的算法。像这样的算法叫做“缓存感知”。缓存感知算法的明显缺点就是它们硬件特定的。
7.6 存储器层次结构
在这一章的几个位置上,你可能会有一个问题:“如果缓存比主存快得多,那为什么不使用一大块缓存,然后把主存扔掉呢?”
在没有深入计算机体系结构之前,可以给出两个原因:电子和经济学上的。缓存很快是由于它们很小,并且离CPU很近,这可以减少由于电容造成的延迟和信号传播。如果你把缓存做得很大,它就变得很慢。
另外,缓存占据处理器芯片的空间,更大的处理器会更贵。主存通常使用动态随机访问内存(DRAM),每位上只有一个晶体管和一个电容,所以它可以将更多内存打包在同一空间上。但是这种实现内存的方法要比缓存实现的方式更慢。
同时主存通常包装在双列直插式内存模块(DIMM)中,它至少包含16个芯片。几个小型芯片比一个大型芯片更便宜。
速度、大小和成本之间的权衡是缓存的根本原因。如果有既快又大还便宜的内存技术,我们就不需要其它东西了。
与内存相同的原则也适用于存储器。闪存非常快,但是它们比硬盘更贵,所以它们就更小。磁带比硬盘更慢,但是它们可以储存更多东西,相对较便宜。
下面的表格展示了每种技术通常的访问时间、大小和成本。
| 设备 | 访问时间 | 通常大小 | 成本 |
|---|---|---|---|
| 寄存器 | 0.5 ns | 256 B | ? |
| 缓存 | 1 ns | 2 MiB | ? |
| DRAM | 10 ns | 4 GiB | $10 / GiB |
| SSD | 10 µs | 100 GiB | $1 / GiB |
| HDD | 5 ms | 500 GiB | $0.25 / GiB |
| 磁带 | minutes | 1–2 TiB | $0.02 / GiB |
寄存器的数量和大小取决于体系结构的细节。当前的计算机拥有32个通用寄存器,每个都可以储存一个“字”。在32位计算机上,一个字为32位,4个字节。64位计算机上,一个字为64位,8个字节。所以寄存器文件的总容量是100~300字节。
寄存器和缓存的成本很难衡量。它们包含在芯片的成本中。但是顾客并不能直接了解到其成本。
对于表中的其它数据,我观察了计算机在线商店中,通常待售的计算机硬件规格。截至你读到这里为止,这些数据应该已经过时了,但是它们可以带给你在过去的某个时间上,一些关于性能和成本差距的概念。
这些技术构成了“存储器体系结构”。结构中每一级都比它上一级大而缓慢。某种意义上,每一级都作为其下一级的缓存。 你可以认为主存是持久化储存在SSD或HDD上的程序和数据的缓存。并且如果你需要处理磁带上非常大的数据集,你可以用硬盘缓存一部分数据。
7.7 缓存策略
存储器层次结构展示了一个考虑到缓存的框架。在结构的每一级中,我们都需要强调四个缓存的基本问题:
- 谁在层次结构中上移或下移数据?在结构的顶端,寄存器通常由编译器完成分配。CPU上的硬件管理内存的缓存。在执行程序或打开文件的过程中,用户可以将存储器上的文件隐式移动到内存中。但是操作系统也会将数据从内存移动回存储器。在层次结构的底端,管理员在磁带和磁盘之间显式移动数据。
- 移动了什么东西?通常,在结构顶端的块大小比底端要小。在内存的缓存中,通常块大小为128B。内存中的页面可能为4KiB,但是当操作系统从磁盘读取文件时,它可能会一次读10或100个块。
- 数据什么时候会移动?在多数的基本的缓存中,数据在首次使用时会移到缓存。但是许多缓存使用一些“预取”机制,也就是说数据会在显式请求之前加载。我们已经见过预取的一些形式了:在请求其一部分时加载整个块。
- 缓存中数据在什么地方?当缓存填满之后,我们不把一些东西扔掉就不可能放进一些东西。理想化来说,我们打算保留将要用到的数据,并替换掉不会用到的数据。
这些问题的答案构成了“缓存策略”。在靠近顶端的位置,缓存策略倾向于更简单,因为它们非常快,并由硬件实现。在靠近底端的位置,会有更多做决定的次数,并且设计良好的策略会有很大不同。
多数缓存策略基于历史重演的原则,如果我们有最近时期的信息,我们可以用它来预测不久的将来。例如,如果一块数据在最近使用了,我们认为它不久之后会再次使用。这个原则展示了一种叫做“最近最少使用”的策略,即LRU。它从缓存中移除最久未使用的数据块。更多话题请见缓存算法的维基百科。
7.8 页面调度
在带有虚拟内存的系统中,操作系统可以将页面在存储器和内存之间移动。像我在6.2中提到的那样,这种机制叫做“页面调度”,或者简单来说叫“换页”。
下面是工作流程:
- 进程A调用
malloc来分配页面。如果堆中没有所请求大小的空闲空间,malloc会调用sbrk向操作系统请求更多内存。 - 如果物理内存中有空闲页,操作系统会将其加载到进程A的页表,创建新的虚拟内存有效范围。
- 如果没有空闲页面,调度系统会选择一个属于进程B的“牺牲页面”。它将页面内容从内存复制到磁盘,之后修改进程B的页表来表示这个页面“被换出”了。
- 一旦进程B的数据被写入,页面会重新分配给进程A。为了防止进程A读取进程B的数据,页面应被清空。
- 此时
sbrk的调用可以返回了,向malloc提供堆区额外的空间。之后malloc分配所请求的内存并返回。进程A可以继续执行。 - 当进程A执行完毕,或中断后,调度器可能会让进程B继续执行。当它访问到被换出的页面时,内存管理器单元注意到这个页面是“无效”的,并且会触发中断。
- 当操作系统处理中断时,它会看到页面被换出了,于是它将页面从磁盘传送到内存。
- 一旦页面被换入之后,进程B可以继续执行。
当页面调度工作良好时,它可以极大提升物理内存的利用水平,允许更多进程在更少的空间内执行。下面是它的原因:
- 大多数进程不会用完所分配的内存。
text段的许多部分都永远不会执行,或者执行一次就再也不用了。这些页面可以被换出而不会引发任何问题。 - 如果程序泄露了内存,它可能会丢掉所分配的空间,并且永远不会使用它了。通过将这些页面换出,操作系统可以有效填补泄露。
- 在多数系统中,有些进程像守护进程那样,多数时间下都是闲置的,只在特定场合被“唤醒”来响应事件。当它们闲置时,这些进程可以被换出。
- 另外,可能有许多进程运行同一个程序。这些进程可以共享相同的
text段,避免在物理内存中保留多个副本。
如果你增加分配给所有进程的总内存,它可以超出物理内存的大小,并且系统仍旧运行良好。
在某种程度上是这样。
当进程访问被换出的页面时,就需要从磁盘获取数据,这会花费几个毫秒。这一延迟通常很明显。如果你将一个窗口闲置一段时间,之后切换回它,它可能会执行得比较慢,并且你可能在页面换入时会听到磁盘工作的声音。
像这样偶尔的延迟可能还可以接受,但是如果你拥有很多占据大量空间的进程,它们就会相互影响。当进程A运行时,它会收回进程B所需的页面,之后进程B运行时,它又会收回进程A所需的页面。当这种情况发生时,两个进程都会执行缓慢,系统会变得无法响应。这种我们不想看到的场景叫做“颠簸”。
理论上,操作系统应该通过检测调度和块上的增长来避免颠簸,或者杀掉进程直到系统能够再次响应。但是在我看来,多数系统都没有这样做,或者做得不好。它们通常让用户去限制物理内存的使用,或者尝试在颠簸发生时恢复。