
27 Django 的文件上传
Django 的文件上传
在学习完 Django 的 Form 模块后,我们就用最后一个常用的文件上传的场景来结束本部分的内容。
1. Django 的文件上传实验
同样,话不多说,我们先通过两个上传的例子来看看 Django 的上传功能。
实验1:简单文件上传
准备本地文件,upload.txt,上传到服务器的 /root/test/django 目录下;
准备模板文件,显示上传按钮:
<form method="post" action="/hello/file_upload/" enctype="multipart/form-data">
{% csrf_token %}
{{ forms }}<br>
<input type="submit" value="提交">
</form>
完成 Form 表单以及视图函数的编写:
class FileUploadForm(forms.Form):
file = forms.FileField(label="文件上传")
def handle_uploaded_file(f):
save_path = os.path.join('/root/test/django', f.name)
with open(save_path, 'wb+') as fp:
for chunk in f.chunks():
fp.write(chunk)
@csrf_exempt
def file_upload(request, *args, **kwargs):
error_msg = ""
if request.method == 'POST':
forms = FileUploadForm(request.POST,request.FILES)
if forms.is_valid():
handle_uploaded_file(request.FILES['file'])
return HttpResponse('上传成功')
error_msg = "异常"
else:
forms = FileUploadForm()
return render(request,'test_file_upload.html',{'forms':forms, "error_msg": error_msg})
编写 URLConf 配置:
urlpatterns = [
# ...
# 文件上传测试
path('file_upload/', views.file_upload)
]
只需要这样几步,一个简单的文件上传就完成了。接下来启动服务进行测试,参考如下的操作:
实验2:使用模型(model) 处理上传的文件
第一步,先设置 settings.py 中的 MEDIA_ROOT,这个设置上传文件保存的根目录;
# first_django_app/settings.py
# ...
MEDIA_ROOT = '/root/test/'
# ...
第二步,准备文件上传模型类
# hello_app/models.py
# ...
class FileModel(models.Model):
name = models.CharField('上传文件名', max_length=20)
upload_file = models.FileField(upload_to='django')
注意:这个 upload_to 参数和 settings.py 中的 MEDIA_ROOT 属性值一起确定文件上传的目录。它可以有很多种形式,比如写成upload_to='django/%Y/%m/%d' 这样的。此外,该参数可以接收方法名,该方法返回的是上传文件的目录。
第三步,我们必须要生成这个对应的表,使用如下命令:
(django-manual) [root@server first_django_app]# python manage.py makemigrations hello_app
(django-manual) [root@server first_django_app]# python manage.py migrate hello_app
执行完成这两步之后,在数据库里面,我们就生成了相应的表。默认的表面是[应用名_模型类名小写],即hello_app__filemodel。
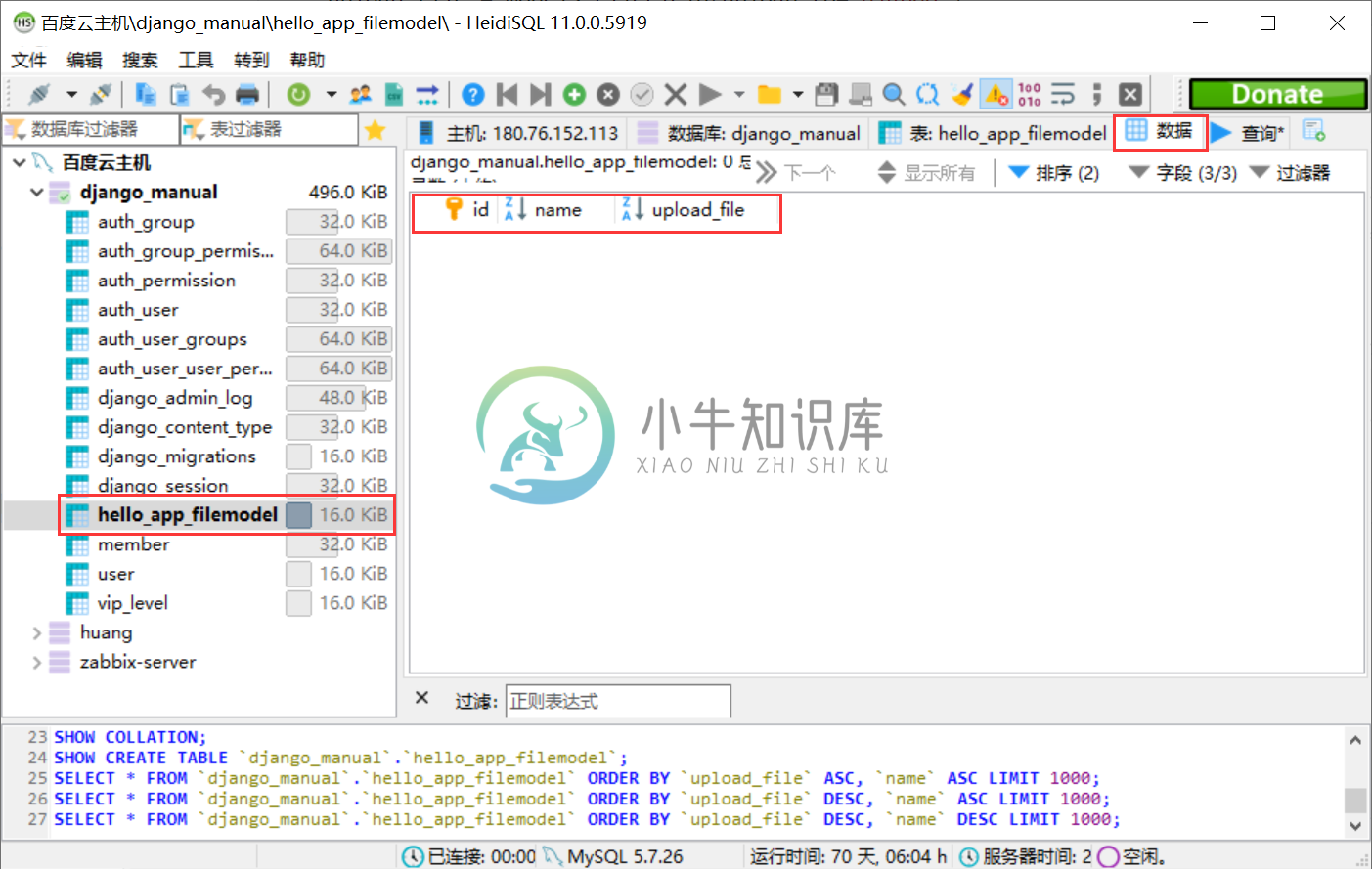
第三步, 准备相应的视图函数;
# hello_app/views.py
# ...
def file_upload2(request, *args, **kwargs):
if request.method == 'POST':
upload_file = request.FILES['upload_file']
FileModel.objects.create(name=upload_file.name, upload_file=upload_file)
return HttpResponse('上传成功')
return render(request,'test_file_upload2.html',{})
# ...
(django-manual) [root@server first_django_app]# cat templates/test_file_upload2.html
{% load staticfiles %}
<form method="post" action="/hello/file_upload2/" enctype="multipart/form-data">
{% csrf_token %}
<label>选择上传文件:</label><input type="file" name="file">
<div><input type="submit" value="提交" style="margin-top:10px"></div>
</form>
注意:这里和之前保存文件方式略有不同,直接使用对应模型实例的保存数据方法即可,文件将会自动上传到指定目录下且会在数据库中添加一条记录。
编写对应的 URLconf 配置,如下:
# hello_app/urls.py
# ...
urlpatterns = [
# ...
# 文件上传测试
path('file_upload2/', views.file_upload2)
]
接下来,就是常规的启动服务,然后页面上测试。参考如下:
实验3:多文件上传实验
实现一次上传多个文件也比较简单,我们只需要改动前端的一行代码,就可以支持一次性上传多个文件。改动前端代码如下:
<!--原来的语句 <label>选择上传文件:</label><input type="file" name="file"> -->
<label>选择上传文件:</label><input type="file" name="files" multiple="">
接下来,简单调整下视图函数:
def file_upload2(request, *args, **kwargs):
if request.method == 'POST':
# 获取文件列表
upload_files = request.FILES.getlist('files')
# 遍历文件并保存
for f in upload_files:
FileModel.objects.create(name=f.name, upload_file=f)
return HttpResponse('上传成功')
return render(request,'test_file_upload2.html',{})
最后看我们的启动服务和测试接口过程如下:
2. Django 的文件上传代码分析
2.1 Django 中和上传文件相关的基础类
这一节主要是来分析下 Django 中和上传文件相关的代码。首先介绍下几个基础类:
FileProxyMixin 类:用于辅助文件上传的 mixin 类。来看看其源码长相:
# 源码路径: django/core/files/utils.py
class FileProxyMixin:
"""
A mixin class used to forward file methods to an underlaying file
object. The internal file object has to be called "file"::
class FileProxy(FileProxyMixin):
def __init__(self, file):
self.file = file
"""
encoding = property(lambda self: self.file.encoding)
fileno = property(lambda self: self.file.fileno)
flush = property(lambda self: self.file.flush)
isatty = property(lambda self: self.file.isatty)
newlines = property(lambda self: self.file.newlines)
read = property(lambda self: self.file.read)
readinto = property(lambda self: self.file.readinto)
readline = property(lambda self: self.file.readline)
readlines = property(lambda self: self.file.readlines)
seek = property(lambda self: self.file.seek)
tell = property(lambda self: self.file.tell)
truncate = property(lambda self: self.file.truncate)
write = property(lambda self: self.file.write)
writelines = property(lambda self: self.file.writelines)
@property
def closed(self):
return not self.file or self.file.closed
def readable(self):
if self.closed:
return False
if hasattr(self.file, 'readable'):
return self.file.readable()
return True
def writable(self):
if self.closed:
return False
if hasattr(self.file, 'writable'):
return self.file.writable()
return 'w' in getattr(self.file, 'mode', '')
def seekable(self):
if self.closed:
return False
if hasattr(self.file, 'seekable'):
return self.file.seekable()
return True
def __iter__(self):
return iter(self.file)
注意:可以看到,想要继承这个 Mixin 并正常使用,继承的类应该有实例属性 file。这里 Mixin 中的属性和我们在 Python 中用 open()方法得到的文件对象的属性几乎一致,后面实验中可以得到佐证。
File 类:专门为上传文件的定义的基类,直接看源代码。
class File(FileProxyMixin):
DEFAULT_CHUNK_SIZE = 64 * 2 ** 10
def __init__(self, file, name=None):
self.file = file
if name is None:
name = getattr(file, 'name', None)
self.name = name
if hasattr(file, 'mode'):
self.mode = file.mode
def __str__(self):
return self.name or ''
def __repr__(self):
return "<%s: %s>" % (self.__class__.__name__, self or "None")
def __bool__(self):
return bool(self.name)
def __len__(self):
return self.size
@cached_property
def size(self):
if hasattr(self.file, 'size'):
return self.file.size
if hasattr(self.file, 'name'):
try:
return os.path.getsize(self.file.name)
except (OSError, TypeError):
pass
if hasattr(self.file, 'tell') and hasattr(self.file, 'seek'):
pos = self.file.tell()
self.file.seek(0, os.SEEK_END)
size = self.file.tell()
self.file.seek(pos)
return size
raise AttributeError("Unable to determine the file's size.")
def chunks(self, chunk_size=None):
"""
Read the file and yield chunks of ``chunk_size`` bytes (defaults to
``File.DEFAULT_CHUNK_SIZE``).
"""
chunk_size = chunk_size or self.DEFAULT_CHUNK_SIZE
try:
self.seek(0)
except (AttributeError, UnsupportedOperation):
pass
while True:
data = self.read(chunk_size)
if not data:
break
yield data
def multiple_chunks(self, chunk_size=None):
"""
Return ``True`` if you can expect multiple chunks.
NB: If a particular file representation is in memory, subclasses should
always return ``False`` -- there's no good reason to read from memory in
chunks.
"""
return self.size > (chunk_size or self.DEFAULT_CHUNK_SIZE)
# ...
def open(self, mode=None):
if not self.closed:
self.seek(0)
elif self.name and os.path.exists(self.name):
self.file = open(self.name, mode or self.mode)
else:
raise ValueError("The file cannot be reopened.")
return self
def close(self):
self.file.close()
这里就能看到我们之前在实验1中用来保存上传文件时用到的 chunks() 方法,我们现在通过 Django 的命令行模式来使用下这个 File 类,看它有哪些功能。
(django-manual) [root@server first_django_app]# python manage.py shell
Python 3.8.1 (default, Dec 24 2019, 17:04:00)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>> from django.core.files import File
接下来,我们看到 File 类实例化时要关联一个文件对象,我们使用之前实验1上传的文件 upload.txt 作为实例化参数:
>>> fp = open('/root/test/django/upload.txt', 'r+')
>>> f = File(fp)
接下来我们就可以测试 File 对象中的各种属性和方法了。具体操作如下:
>>> f.name
'/root/test/django/upload.txt'
>>> f.size
47
# 按照20字节大小,判断文件需不需要分块读入
>>> f.multiple_chunks(20)
True
# 默认块大小64k,47字节太小了,所以不用分块读入
>>> f.multiple_chunks()
False
我们可以使用 chunks() 方法分块读取文件内容,然后做我们想做的事情,如下:
>>> for c in f.chunks():
... print('本次读入:{}'.format(c))
...
本次读入:测试上传文件
xxxxx
spyinx test upload
>>> for c in f.chunks(20):
... print('本次读入:{}'.format(c))
...
本次读入:测试上传文件
xxxxx
spyinx
本次读入: test upload
上面测试了2种形式,一种不需要分块读如数据,一口气读完所有内容(因为默认的分块大小大于文件内容)。另一种则设置小一些分块大小,这样会每次读取最多20字节内容,依次打印读取到的内容。
接下来我们看下和上传相关的两个文件类:TemporaryUploadedFile 和 InMemoryUploadedFile。这两个类都是继承自 UploadedFile,而 UploadedFile 又是继承至 File 类的。
# 源码路径: django/core/files/uploadedfile.py
class UploadedFile(File):
"""
An abstract uploaded file (``TemporaryUploadedFile`` and
``InMemoryUploadedFile`` are the built-in concrete subclasses).
An ``UploadedFile`` object behaves somewhat like a file object and
represents some file data that the user submitted with a form.
"""
def __init__(self, file=None, name=None, content_type=None, size=None, charset=None, content_type_extra=None):
super().__init__(file, name)
self.size = size
self.content_type = content_type
self.charset = charset
self.content_type_extra = content_type_extra
def __repr__(self):
return "<%s: %s (%s)>" % (self.__class__.__name__, self.name, self.content_type)
def _get_name(self):
return self._name
def _set_name(self, name):
# Sanitize the file name so that it can't be dangerous.
if name is not None:
# Just use the basename of the file -- anything else is dangerous.
name = os.path.basename(name)
# File names longer than 255 characters can cause problems on older OSes.
if len(name) > 255:
name, ext = os.path.splitext(name)
ext = ext[:255]
name = name[:255 - len(ext)] + ext
self._name = name
name = property(_get_name, _set_name)
这个类相比于 File 基类主要是增加了多个实例属性,其他方法到没啥变化。接下里来看继承这个类的两个 File 类:
class TemporaryUploadedFile(UploadedFile):
"""
A file uploaded to a temporary location (i.e. stream-to-disk).
"""
def __init__(self, name, content_type, size, charset, content_type_extra=None):
_, ext = os.path.splitext(name)
file = tempfile.NamedTemporaryFile(suffix='.upload' + ext, dir=settings.FILE_UPLOAD_TEMP_DIR)
super().__init__(file, name, content_type, size, charset, content_type_extra)
def temporary_file_path(self):
"""Return the full path of this file."""
return self.file.name
def close(self):
try:
return self.file.close()
except FileNotFoundError:
# The file was moved or deleted before the tempfile could unlink
# it. Still sets self.file.close_called and calls
# self.file.file.close() before the exception.
pass
class InMemoryUploadedFile(UploadedFile):
"""
A file uploaded into memory (i.e. stream-to-memory).
"""
def __init__(self, file, field_name, name, content_type, size, charset, content_type_extra=None):
super().__init__(file, name, content_type, size, charset, content_type_extra)
self.field_name = field_name
def open(self, mode=None):
self.file.seek(0)
return self
def chunks(self, chunk_size=None):
self.file.seek(0)
yield self.read()
def multiple_chunks(self, chunk_size=None):
# Since it's in memory, we'll never have multiple chunks.
return False
这两段代码非常简单,代码展现的逻辑也非常清晰。TemporaryUploadedFile 打开的文件是临时生成的文件,而 InMemoryUploadedFile 类对于上传的文件会保存到内存中。我们熟悉了这两个类之后来对应的处理上传文件的 Handler,一个会使用 TemporaryUploadedFile 类使用临时文件保存上传的文件,另一个会使用 InMemoryUploadedFile 将上传文件的内容写到内存中:
class TemporaryFileUploadHandler(FileUploadHandler):
"""
Upload handler that streams data into a temporary file.
"""
def new_file(self, *args, **kwargs):
"""
Create the file object to append to as data is coming in.
"""
super().new_file(*args, **kwargs)
# 这个文件是打开临时文件的句柄
self.file = TemporaryUploadedFile(self.file_name, self.content_type, 0, self.charset, self.content_type_extra)
# 将受到的数据写入到对应的临时文件中
def receive_data_chunk(self, raw_data, start):
self.file.write(raw_data)
# 处理文件完毕
def file_complete(self, file_size):
# 文件指针,指向初始位置
self.file.seek(0)
# 设置文件大小
self.file.size = file_size
return self.file
class MemoryFileUploadHandler(FileUploadHandler):
"""
File upload handler to stream uploads into memory (used for small files).
"""
def handle_raw_input(self, input_data, META, content_length, boundary, encoding=None):
"""
Use the content_length to signal whether or not this handler should be
used.
"""
# Check the content-length header to see if we should
# If the post is too large, we cannot use the Memory handler.
self.activated = content_length <= settings.FILE_UPLOAD_MAX_MEMORY_SIZE
def new_file(self, *args, **kwargs):
super().new_file(*args, **kwargs)
if self.activated:
self.file = BytesIO()
raise StopFutureHandlers()
def receive_data_chunk(self, raw_data, start):
"""Add the data to the BytesIO file."""
if self.activated:
self.file.write(raw_data)
else:
return raw_data
def file_complete(self, file_size):
"""Return a file object if this handler is activated."""
if not self.activated:
return
self.file.seek(0)
return InMemoryUploadedFile(
file=self.file,
field_name=self.field_name,
name=self.file_name,
content_type=self.content_type,
size=file_size,
charset=self.charset,
content_type_extra=self.content_type_extra
)
2.2 Django 中上传文件流程追踪
这部分内容会有点复杂和枯燥,我会尽量简化代码,并使用前面的上传实验帮助我们在源码中打印一些 print语句,辅助我们更好的理解整个上传过程。
思考问题:为什么上传文件时,我们能通过 request.FILES['file'] 拿到文件?Django 帮我们把文件信息存到这里面,那么它是如何处理上传的文件的呢?
我们现在的目的就是要搞清楚上面的问题,可能里面的代码会比较复杂,目前我们不深入研究代码细节,只是搞清楚整个过程以及 Django 帮我们做了哪些工作。
首先,我们打印下视图函数的 request 参数,发现它是 django.core.handlers.wsgi.WSGIRequest 的一个实例,这在很早之前也是介绍过的。我们重点看看 WSGIRequest 类中的 FILES 属性:
# 源码位置:django/core/handlers/wsgi.py
# ...
class WSGIRequest(HttpRequest):
# ...
@property
def FILES(self):
if not hasattr(self, '_files'):
self._load_post_and_files()
return self._files
# ...
看到这里,我们就大概知道 FILES 属性值的来源了,就是通过 self._load_post_and_files() 这个方法设置self._files 值,而这个就是 FILES 的值。接下来就是继续深入 self._load_post_and_files() 这个方法,但是我们不追究代码细节。
# 源码位置:django/http/request.py
class HttpRequest:
"""A basic HTTP request."""
# ...
def _load_post_and_files(self):
"""Populate self._post and self._files if the content-type is a form type"""
if self.method != 'POST':
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
return
if self._read_started and not hasattr(self, '_body'):
self._mark_post_parse_error()
return
if self.content_type == 'multipart/form-data':
if hasattr(self, '_body'):
# Use already read data
data = BytesIO(self._body)
else:
data = self
try:
self._post, self._files = self.parse_file_upload(self.META, data)
except MultiPartParserError:
# An error occurred while parsing POST data. Since when
# formatting the error the request handler might access
# self.POST, set self._post and self._file to prevent
# attempts to parse POST data again.
self._mark_post_parse_error()
raise
elif self.content_type == 'application/x-www-form-urlencoded':
self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict()
else:
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
# ...
一般而言,我们使用的是 form 表单提交的上传,对应的 content-type 大部分时候是 multipart/form-data。所以,获取 _files 属性的最重要的代码就是:
self._post, self._files = self.parse_file_upload(self.META, data)
咋继续追踪 self.parse_file_upload() 这个方法。
class HttpRequest:
"""A basic HTTP request."""
# ...
def _initialize_handlers(self):
self._upload_handlers = [uploadhandler.load_handler(handler, self)
for handler in settings.FILE_UPLOAD_HANDLERS]
@property
def upload_handlers(self):
if not self._upload_handlers:
# If there are no upload handlers defined, initialize them from settings.
self._initialize_handlers()
return self._upload_handlers
@upload_handlers.setter
def upload_handlers(self, upload_handlers):
if hasattr(self, '_files'):
raise AttributeError("You cannot set the upload handlers after the upload has been processed.")
self._upload_handlers = upload_handlers
def parse_file_upload(self, META, post_data):
"""Return a tuple of (POST QueryDict, FILES MultiValueDict)."""
self.upload_handlers = ImmutableList(
self.upload_handlers,
warning="You cannot alter upload handlers after the upload has been processed."
)
parser = MultiPartParser(META, post_data, self.upload_handlers, self.encoding)
return parser.parse()
# ...
这三个涉及的函数都比较简单,主要是获取处理上传文件的 handlers。settings.FILE_UPLOAD_HANDLERS 这个值是取得 global_settings.py 中设置的,而非项目的 settings.py 文件(该文件默认没有设置该参数值)。但是我们可以在 settings.py 文件中设置 FILE_UPLOAD_HANDLERS 的值以覆盖默认的 handlers。
# 源码位置:django\conf\global_settings.py
# ...
# List of upload handler classes to be applied in order.
FILE_UPLOAD_HANDLERS = [
'django.core.files.uploadhandler.MemoryFileUploadHandler',
'django.core.files.uploadhandler.TemporaryFileUploadHandler',
]
# ...
最后可以看到 parse_file_upload() 方法的核心语句也只有一句:
parser = MultiPartParser(META, post_data, self.upload_handlers, self.encoding)
最后调用 parser.parse() 方法获得结果。最后要说明的是 parser.parse() 比较复杂,我们简单看下函数的大致内容即可,课后在继续深究函数的细节:
# 源码位置:django/http/multipartparser.py
class MultiPartParser:
# ...
def parse(self):
"""
Parse the POST data and break it into a FILES MultiValueDict and a POST
MultiValueDict.
Return a tuple containing the POST and FILES dictionary, respectively.
"""
from django.http import QueryDict
encoding = self._encoding
handlers = self._upload_handlers
# HTTP spec says that Content-Length >= 0 is valid
# handling content-length == 0 before continuing
if self._content_length == 0:
return QueryDict(encoding=self._encoding), MultiValueDict()
# See if any of the handlers take care of the parsing.
# This allows overriding everything if need be.
for handler in handlers:
result = handler.handle_raw_input(
self._input_data,
self._meta,
self._content_length,
self._boundary,
encoding,
)
# Check to see if it was handled
if result is not None:
return result[0], result[1]
# Create the data structures to be used later.
self._post = QueryDict(mutable=True)
self._files = MultiValueDict()
# Instantiate the parser and stream:
stream = LazyStream(ChunkIter(self._input_data, self._chunk_size))
# Whether or not to signal a file-completion at the beginning of the loop.
old_field_name = None
counters = [0] * len(handlers)
# Number of bytes that have been read.
num_bytes_read = 0
# To count the number of keys in the request.
num_post_keys = 0
# To limit the amount of data read from the request.
read_size = None
# ...
# Signal that the upload has completed.
# any() shortcircuits if a handler's upload_complete() returns a value.
any(handler.upload_complete() for handler in handlers)
self._post._mutable = False
return self._post, self._files
可以看到,这个函数最后得到 self._post, self._files, 然后返回该结果。有兴趣的话可以自行在这几个重要的地方加上 print() 方法看看对应的 self._post, self._files 的输出结果,有助于加深印象。
3. 小结
本小节首先以三个文件上传实验演示了 Django 中的文件上传功能。接下来我们分析了 Django 中涉及文件上传相关的类以及对应的配置参数。在经过这一节的讲解后,我们第三部分内容算是彻底结束了,这部分涉及了许多源码的讲解,会有些枯燥,但是非常有意思。但是如果你能认真追下来,并课后继续阅读和调试代码,相信你会在日后成为 Django 高手,遇到任何问题都能够自己独立解决。