
第一部分:常用操作 - 4. 监控 PG
CRUSH 算法把 PG 分配到 OSD 时,它会根据存储池的副本数设置,把 PG 分配到不同的 OSD 上。比如,如果存储池设置为 3 副本, CRUSH 可能把它们分别分配到 osd.1 、osd.2 、osd.3 。考虑到 CRUSH Map 中设定的故障域,实际上 CRUSH 找出的是伪随机位置,所以在大型集群中,很少能看到 PG 被分配到了相邻的 OSD 。我们把涉及某个特定 PG 副本的一组 OSD 称为 acting set 。在某些情况下,位于 acting set 中的一个 OSD down 了或者不能为 PG 内的对象提供服务,这些情形发生时无需惊慌,常见原因如下:
- 你增加或移除了某个 OSD 。然后 CRUSH 算法把 PG 重新分配到了其他 OSD ,因此改变了 Acting Set 的构成,并且引发了 “backfill” 过程来进行数据迁移。
- 某个 OSD
down了、重启了,而现在正在恢复(recovering)。 - Acting Set 中的一个 OSD
down了,不能提供服务,另一个 OSD 临时接替其工作。
Ceph 靠 Up Set 处理客户端请求,它们是实际处理读写请求的 OSD 集合。大多数情况下 Up Set 和 Acting Set 是相同的。如果不同,说明可能 Ceph 正在迁移数据、某 OSD 在恢复、或者有别的问题。这种情况下, Ceph 通常表现为 “HEALTH WARN” 状态,还有 “stuck stale” 消息。
用下列命令获取 PG 列表:
ceph pg dump
查看指定 PG 的 Acting Set 或 Up Set 中包含的 OSD,执行:
ceph pg map {pg-num}
命令的输出会告诉你 osdmap 版本( eNNN )、PG 号( {pg-num} )、Up Set 内的 OSD ( up[] )、和 Acting Set 内的 OSD ( acting[] )。
osdmap e1196 pg 0.2d (0.2d) -> up [13,30] acting [13,30]
4.1 节点互联
写入数据前,PG 必须处于 active 、而且应该是 clean 状态。假设某存储池的 PG 有 3 副本,为让 Ceph 确定 PG 的当前状态,PG 的主 OSD (即 acting set 内的第一个 OSD )会与第二和第三 OSD 建立连接、并就 PG 的当前状态达成一致意见。
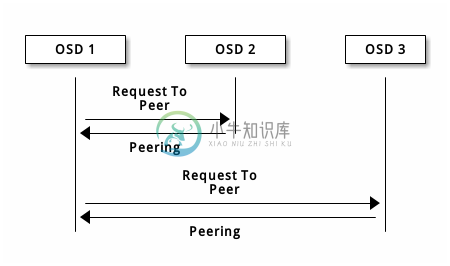
OSD 们也向 Mon 报告自己的状态。要排除节点互联的问题,请参考本手册第二部分 3. 常见 PG 故障处理 中的相关部分进行处理。
4.2 监控 PG 状态
如果你执行了 ceph health 、 ceph -s 、或 ceph -w 命令,你也许注意到了集群并非总返回 HEALTH_OK 。检查完 OSD 是否在运行后,你还应该检查 PG 的状态。你应该明白,在 PG 建立连接时集群不会返回 HEALTH_OK :
- 刚刚创建了一个存储池,PG 还没达成一致。
- PG 正在恢复。
- 刚刚增加或删除了一个 OSD 。
- 刚刚修改了 CRUSH Map,PG 正在迁移。
- 某一 PG 的副本间的数据不一致。
- Ceph 正在洗刷一个 PG 的副本。
- Ceph 没有足够可用容量来完成回填操作。
如果是前述原因之一导致了 Ceph 返回 HEALTH_WARN ,无需紧张。很多情况下,集群会自行恢复;有些时候你得采取些措施。归置 PG 的一件重要事情是保证集群启动并运行着,所有 PG 都处于 active 状态、并且最好是 clean 状态。用下列命令查看所有 PG 状态:
ceph pg stat
其结果会告诉你 PG map 的版本号( vNNNNNN )、PG 总数 x 、有多少 PG 处于某种特定状态,如 active+clean ( y )。
vNNNNNN: x pgs: y active+clean; z MB data, aa MB used, bb MB / cc MB avail
除了 PG 状态之外, Ceph 也会报告数据占据的空间( aa )、剩余可用空间( bb )和 PG 总容量。这些数字在某些情况下是很重要的:
- 集群快达到
near full ratio或full ratio时。 - 由于 CRUSH 配置错误致使数据没能在集群内正确分布。
PG ID
PG IDs 由存储池号(不是存储池名字)、后面跟一个点( . )、再加一个 16 进制数字的 PG ID 。用 ceph osd lspools 可查看存储池号及其名字,例如,默认存储池 rbd 对应的存储池号是 0 。完整的 PG ID 格式如下:
{pool-num}.{pg-id}
典型例子:
0.1f
用下列命令获取 PG 列表:
ceph pg dump
你也可以让它输出到 JSON 格式,并保存到文件:
ceph pg dump -o {filename} --format=json
要查询某个 PG,用下列命令:
ceph pg {poolnum}.{pg-id} query
Ceph 会输出成 JSON 格式。
{"state": "active+clean","snap_trimq": "[]","epoch": 26760,"up": [1,2],"acting": [1,2],"actingbackfill": ["1","2"],"info": {"pgid": "0.2d","last_update": "26708'96","last_complete": "26708'96","log_tail": "0'0","last_user_version": 96,"last_backfill": "MAX","purged_snaps": "[1~1]","history": {"epoch_created": 1,"last_epoch_started": 26760,"last_epoch_clean": 26760,......"recovery_state": [{"name": "Started\/Primary\/Active","enter_time": "2016-11-05 11:01:12.719671","might_have_unfound": [],"recovery_progress": {"backfill_targets": [],"waiting_on_backfill": [],"last_backfill_started": "0\/\/0\/\/-1","backfill_info": {"begin": "0\/\/0\/\/-1","end": "0\/\/0\/\/-1","objects": []},"peer_backfill_info": [],"backfills_in_flight": [],"recovering": [],"pg_backend": {"pull_from_peer": [],"pushing": []}},"scrub": {"scrubber.epoch_start": "26752","scrubber.active": 0,"scrubber.waiting_on": 0,"scrubber.waiting_on_whom": []}},{"name": "Started","enter_time": "2016-11-05 11:01:11.737126"}],"agent_state": {}}
4.3 找出故障 PG
如前所述,一个 PG 状态不是 active+clean 时未必有问题。一般来说,PG 卡住时 Ceph 的自修复功能可能会不起作用,卡住的状态细分为:
- Unclean: PG 里有些对象的副本数未达到期望值,它们应该进行恢复。
- Inactive: PG 不能处理读写请求,因为它们在等着一个持有最新数据的 OSD 回到
up状态。 - Stale: PG 处于一种未知状态,因为存储它们的 OSD 有一阵子没向 Mon 报告了(由参数
mon osd report timeout配置)。
为找出卡住的归置组,执行:
ceph pg dump_stuck [unclean|inactive|stale|undersized|degraded]
关于排除卡住的 PG 见请参考本手册第二部分 3. 常见 PG 故障处理 中的相关部分进行处理。
4.4 定位对象位置
要把对象数据存入 Ceph 对象存储, Ceph 客户端必须:
- 设置对象名
- 指定存储池
Ceph 客户端索取最新集群 map、并用 CRUSH 算法计算对象到 PG 的映射,然后计算如何动态地把 PG 分配到 OSD 。要定位对象位置,只需要知道对象名和存储池名字:
ceph osd map {poolname} {object-name}
练习:定位一个对象
我们先创建一个对象。给 rados put 命令指定一对象名、一个包含数据的测试文件路径、和一个存储池名字,例如:
rados put {object-name} {file-path} --pool=datarados put test-object-1 testfile.txt --pool=data
用下列命令确认 Ceph 对象存储已经包含此对象:
rados -p data ls
现在可以定位对象了:
ceph osd map {pool-name} {object-name}ceph osd map data test-object-1
Ceph 应该输出对象的位置,例如:
osdmap e537 pool 'data' (0) object 'test-object-1' -> pg 0.d1743484 (0.4) -> up [1,0] acting [1,0]
要删除测试对象,用 rados rm 即可,如:
rados rm test-object-1 --pool=data