
Developing Inference Algorithms
Developing Inference Algorithms
Edward uses class inheritance to provide a hierarchy of inference methods. This enables fast experimentation on top of existing algorithms, whether it be developing new black box algorithms or new model-specific algorithms. For examples of algorithms developed in Edward, see the inference tutorials.
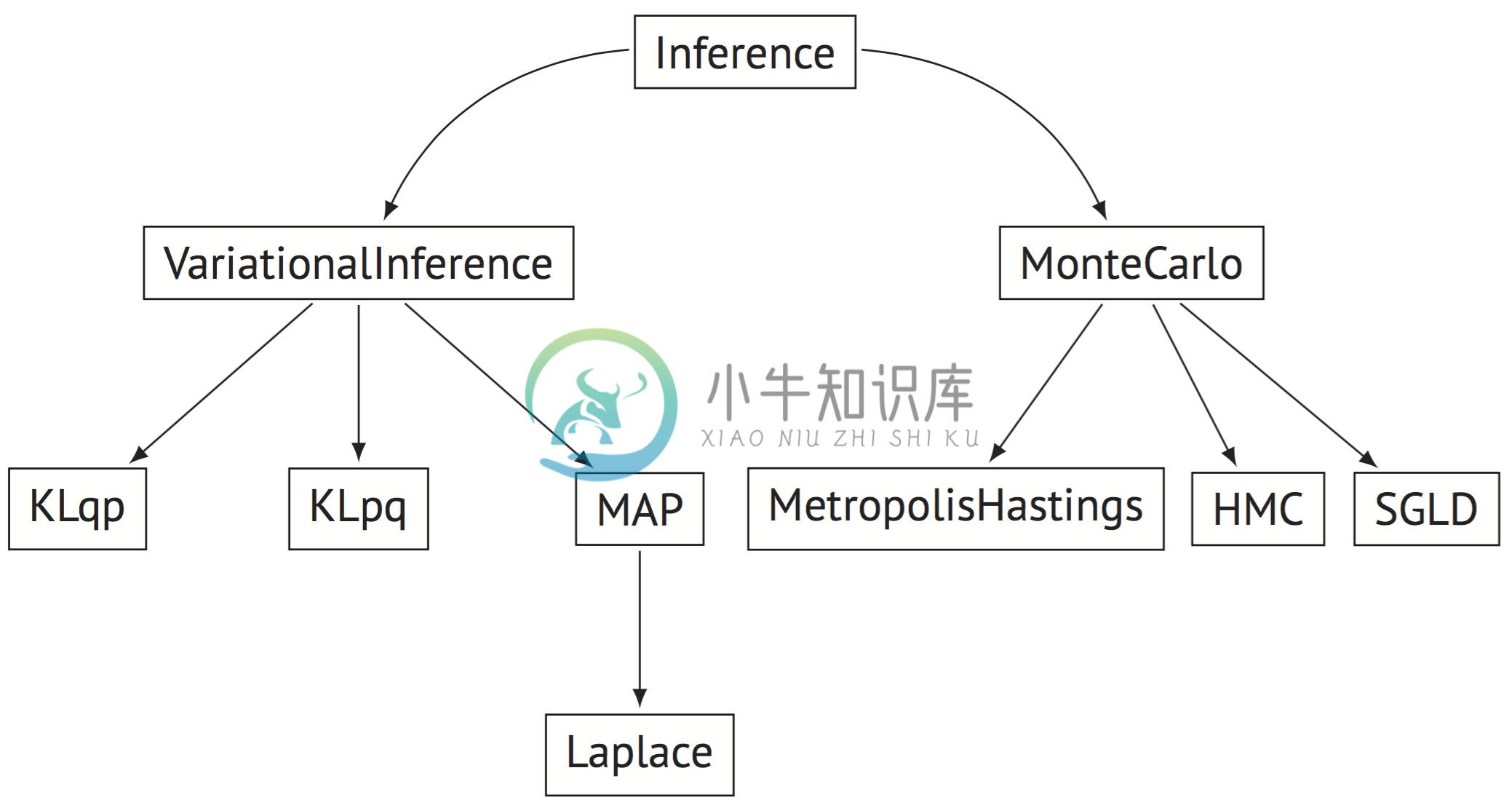 Dependency graph of several inference methods. Nodes are classes in Edward and arrows represent class inheritance.
Dependency graph of several inference methods. Nodes are classes in Edward and arrows represent class inheritance.
There is a base class Inference, from which all inference methods are derived from. Note that Inference says nothing about the class of models that an algorithm must work with. One can build inference algorithms which are tailored to a restricted class of models available in Edward (such as differentiable models or conditionally conjugate models), or even tailor it to a single model. The algorithm can raise an error if the model is outside this class.
We organize inference under two paradigms: VariationalInference and MonteCarlo (or more plainly, optimization and sampling). These inherit from Inference and each have their own default methods.
For example, developing a new variational inference algorithm is as simple as inheriting from VariationalInference and writing a build_loss_and_gradients() method. VariationalInference implements many default methods such as initialize() with options for an optimizer. For example, see the importance weighted variational inference script.