
python获取cookie的方法_【爬虫】一个简单方便的获取cookie的python库

【爬虫】一个简单方便的获取cookie的python库
雁陎 • 2021 年 01 月 07 日
Loading...
## 前言
很久之前学过一点点爬虫,前几天需要爬一点资料所以又捡起来了。算是小需求所以也没用太复杂的框架,就 `Requests`+`正则` 就 ok 了。遗憾的是,需要爬的目标站是那种登录才可以见全文的那种网站,所以我得想办法获取 cookie。网上搜了一下,比较简单的方法有两种,一种是直接查看登录后网站存储的 cookie,然后解析使用。另一种是构造一个登录函数,登录后再获取 cookie。前者最为方便,但由于 cookie 会失效,所以需要及时获取新的 cookie,不适合自动化工作。后者不用担心时效性,但是构造一个合适的请求并成功登录还是有点难度的(至少我从来没有成功过),而且面对手机号 + 验证码登录的网站就抓瞎了。本文在将会介绍一个 python 库 `browser_cookie3`,只要在 `Chrome` 或者 `Firefox` 上成功登录,这个库就会自动抓取已经存储到本地的 cookie,尝试了一下还是挺好用的。
当然,我们之前还介绍过 [webscraper](https://www.sitstars.com/archives/54/) 这个 Chrome 插件,同样不用考虑 cookie 的问题,但是因为不太灵活,所以我也很少再用了。
在文章开始前,我要提醒一下读者,本人对爬虫相关知识并不是非常了解,可能对 cookie 的解释有错误之处,仅供参考,如有不同意见可以在评论区交流。
## 方法一:直接解析 cookie
首先登录目标网站,然后按下 `F12` 打开开发者工具,点开 `Network`,找到目标网站的链接,点开之后往下拉,就可以看到 cookie 了。
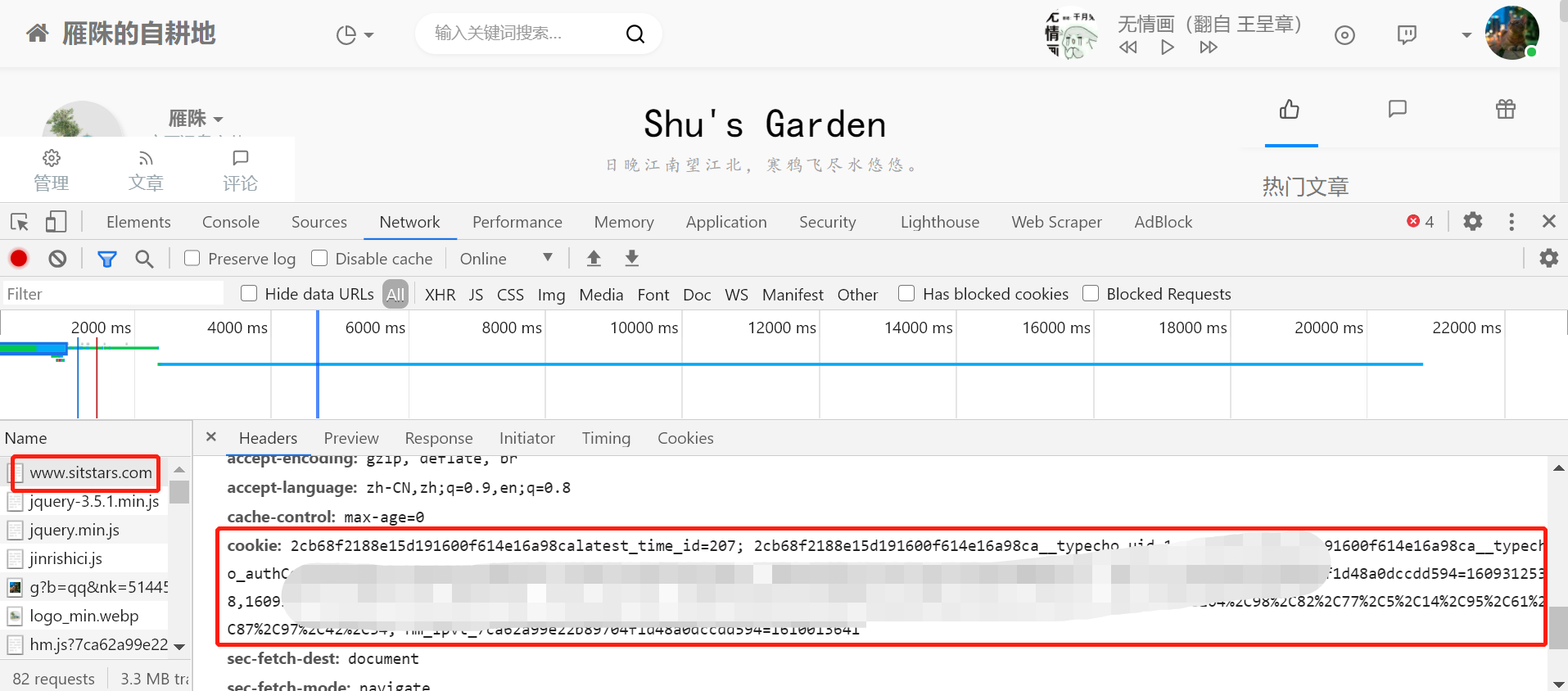
然后进行解析,格式化为字典形式,代码如下。
```python
cookies = '复制过来的cookie'
cookie = {i.split("=")[0]:i.split("=")[1] for i in cookies.split(";")}
```
然后就可以愉快 Requests 了
```python
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
requests.get(url,headers=headers, cookies=cookie)
```
## 方法二:模拟登录获取 cookie
参考文章:https://blog.csdn.net/qlzy_5418/article/details/101056488
https://zhuanlan.zhihu.com/p/27867925
最简单的方案如下:
```python
def get_cookie():
url = 'https://www.xxx.com/signin' #登录网址
data = {'username': 'xxx',
'password': 'xxx'}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36', }
session = requests.session()
cookie_jar = session.get(url=url, data=data, headers=headers).cookies
cookie_t = requests.utils.dict_from_cookiejar(cookie_jar)
return cookie_t
```
但是一般而言是成功不了的,你还要考虑 data 的字段,post 还是 get 请求,以及动态变换的参数。
可能使用 `selenium` 进行模拟登录还更简单一些。
## 方法三:browser_cookie3
GitHub 网站:[https://github.com/borisbabic/browser_cookie3](https://github.com/borisbabic/browser_cookie3)
> 有 python2 版本,库名为 browser_cookie
使用方法很简单,首先安装:
```bash
pip install browser-cookie3
```
然后登录目标网站
最后获取 cookie:
```python
import browser_cookie3
import requests
cj = browser_cookie3.chrome() # firefox可以替换为browser_cookie3.firefox()
r = requests.get(url, cookies=cj)
```
上面的代码是获取特定浏览器的 cookie,也可以获取所有浏览器的 cookie:
```python
cj = browser_cookie3.load()
```
或者是获取指定网站的 cookie:
```python
browser_cookie3.chrome(domain_name='www.bitbucket.com')
```
版权属于:雁陎
本文链接:https://www.sitstars.com/archives/106/
转载时须注明出处及本声明