
Apify SDK: The scalable web crawling and scraping library for JavaScript

Apify SDK simplifies the development of web crawlers, scrapers, data extractors and web automation jobs.It provides tools to manage and automatically scale a pool of headless browsers,to maintain queues of URLs to crawl, store crawling results to a local filesystem or into the cloud,rotate proxies and much more.The SDK is available as the apify NPM package.It can be used either stand-alone in your own applicationsor in actorsrunning on the Apify Cloud.
View full documentation, guides and examples on the Apify SDK project website
Motivation
Thanks to tools like Playwright, Puppeteer orCheerio, it is easy to write Node.js code to extract data from web pages. Buteventually things will get complicated. For example, when you try to:
- Perform a deep crawl of an entire website using a persistent queue of URLs.
- Run your scraping code on a list of 100k URLs in a CSV file, without losing any data when your code crashes.
- Rotate proxies to hide your browser origin and keep user-like sessions.
- Disable browser fingerprinting protections used by websites.
Python has Scrapy for these tasks, but there was no such library for JavaScript, the language ofthe web. The use of JavaScript is natural, since the same language is used to write the scripts as well as the data extraction code running in abrowser.
The goal of the Apify SDK is to fill this gap and provide a toolbox for generic web scraping, crawling and automation tasks in JavaScript. So don'treinvent the wheel every time you need data from the web, and focus on writing code specific to the target website, rather than developingcommonalities.
Overview
The Apify SDK is available as the apify NPM package and it provides the following tools:
CheerioCrawler- Enables the parallel crawling of a largenumber of web pages using the cheerio HTML parser. This is the mostefficient web crawler, but it does not work on websites that require JavaScript.PuppeteerCrawler- Enables the parallel crawling ofa large number of web pages using the headless Chrome browser and Puppeteer.The pool of Chrome browsers is automatically scaled up and down based on available system resources.PlaywrightCrawler- UnlikePuppeteerCrawleryou can use Playwright to manage almost any headless browser.It also provides a cleaner and more mature interface while keeping the ease of use and advanced features.BasicCrawler- Provides a simple framework for the parallelcrawling of web pages whose URLs are fed either from a static list or from a dynamic queue of URLs. This classserves as a base for the more specialized crawlers above.RequestList- Represents a list of URLs to crawl.The URLs can be passed in code or in a text file hosted on the web. The list persists its state so that crawlingcan resume when the Node.js process restarts.RequestQueue- Represents a queue of URLs to crawl,which is stored either on a local filesystem or in the Apify Cloud. The queue is usedfor deep crawling of websites, where you start with several URLs and then recursively follow links to other pages.The data structure supports both breadth-first and depth-first crawling orders.Dataset- Provides a store for structured data and enables their exportto formats like JSON, JSONL, CSV, XML, Excel or HTML. The data is stored on a local filesystem or in the Apify Cloud.Datasets are useful for storing and sharing large tabular crawling results, such as a list of products or real estate offers.KeyValueStore- A simple key-value store for arbitrary datarecords or files, along with their MIME content type. It is ideal for saving screenshots of web pages, PDFsor to persist the state of your crawlers. The data is stored on a local filesystem or in the Apify Cloud.AutoscaledPool- Runs asynchronous background tasks,while automatically adjusting the concurrency based on free system memory and CPU usage. This is useful for runningweb scraping tasks at the maximum capacity of the system.Browser Utils- Provides several helper functions usefulfor web scraping. For example, to inject jQuery into web pages or to hide browser origin.
Additionally, the package provides various helper functions to simplify running your code on the Apify Cloud and thustake advantage of its pool of proxies, job scheduler, data storage, etc.For more information, see the Apify SDK Programmer's Reference.
Quick Start
This short tutorial will set you up to start using Apify SDK in a minute or two.If you want to learn more, proceed to the Getting Startedtutorial that will take you step by step through creating your first scraper.
Local stand-alone usage
Apify SDK requires Node.js 15.10 or later.Add Apify SDK to any Node.js project by running:
npm install apify playwright
Neither
playwrightnorpuppeteerare bundled with the SDK to reduce install size and allow greaterflexibility. That's why we install it with NPM. You can choose one, both, or neither.
Run the following example to perform a recursive crawl of a website using Playwright. For more examples showcasing various features of the Apify SDK,see the Examples section of the documentation.
const Apify = require('apify');
// Apify.main is a helper function, you don't need to use it.
Apify.main(async () => {
const requestQueue = await Apify.openRequestQueue();
// Choose the first URL to open.
await requestQueue.addRequest({ url: 'https://www.iana.org/' });
const crawler = new Apify.PlaywrightCrawler({
requestQueue,
handlePageFunction: async ({ request, page }) => {
// Extract HTML title of the page.
const title = await page.title();
console.log(`Title of ${request.url}: ${title}`);
// Add URLs that match the provided pattern.
await Apify.utils.enqueueLinks({
page,
requestQueue,
pseudoUrls: ['https://www.iana.org/[.*]'],
});
},
});
await crawler.run();
});
When you run the example, you should see Apify SDK automating a Chrome browser.
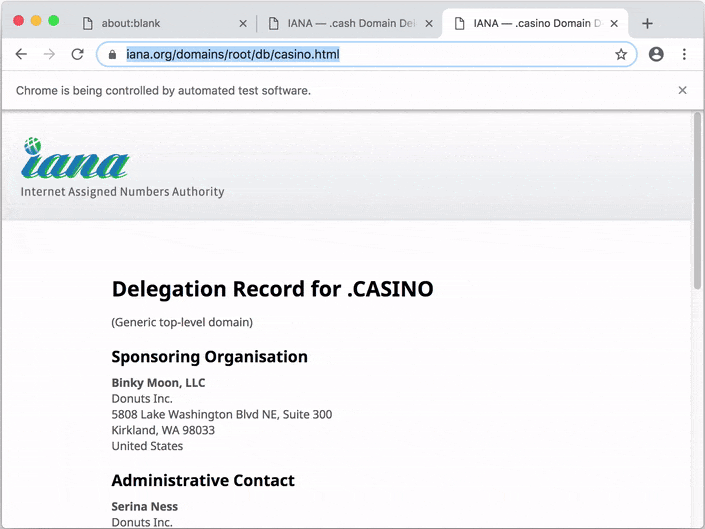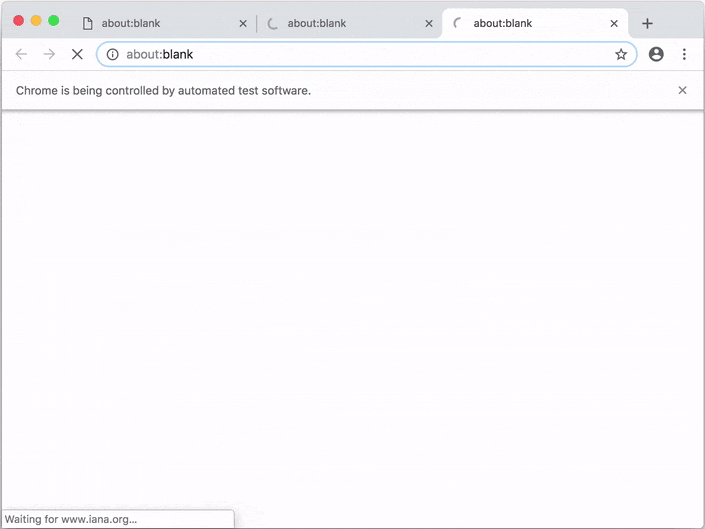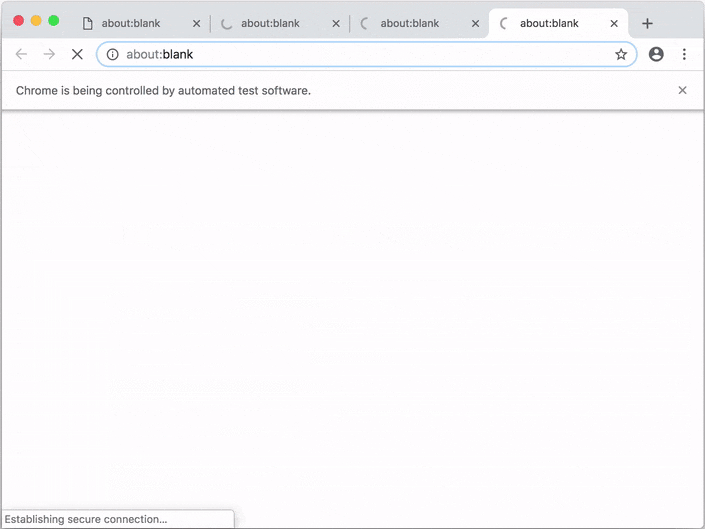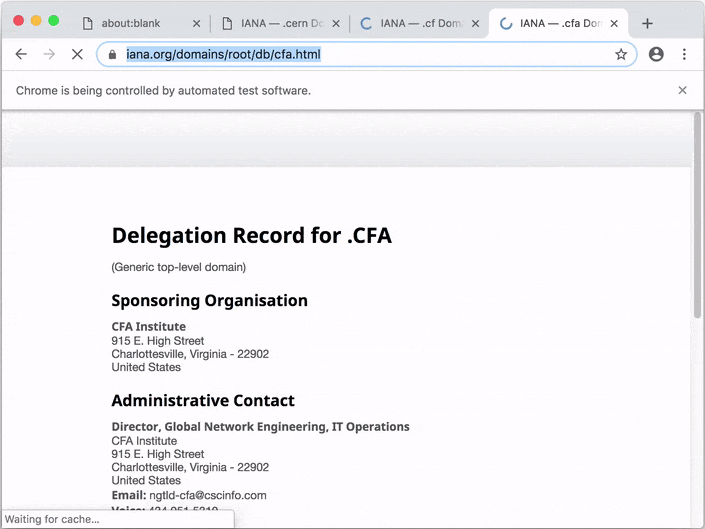
By default, Apify SDK stores data to ./apify_storage in the current working directory. You can override this behavior by setting either theAPIFY_LOCAL_STORAGE_DIR or APIFY_TOKEN environment variable. For details, see Environment variables, Request storage and Result storage.
Local usage with Apify command-line interface (CLI)
To avoid the need to set the environment variables manually, to create a boilerplate of your project, and to enable pushing and running your code onthe Apify platform, you can use the Apify command-line interface (CLI) tool.
Install the CLI by running:
npm -g install apify-cli
Now create a boilerplate of your new web crawling project by running:
apify create my-hello-world
The CLI will prompt you to select a project boilerplate template - just pick "Hello world". The tool will create a directory called my-hello-worldwith a Node.js project files. You can run the project as follows:
cd my-hello-world
apify run
By default, the crawling data will be stored in a local directory at ./apify_storage. For example, the input JSON file for the actor is expected tobe in the default key-value store in ./apify_storage/key_value_stores/default/INPUT.json.
Now you can easily deploy your code to the Apify platform by running:
apify login
apify push
Your script will be uploaded to the Apify platform and built there so that it can be run. For more information, view theApify Actor documentation.
Usage on the Apify platform
You can also develop your web scraping project in an online code editor directly on the Apify platform.You'll need to have an Apify Account. Go to Actors, page in the app, click Create newand then go to the Source tab and start writing your code or paste one of the examples from the Examples section.
For more information, view the Apify actors quick start guide.
Support
If you find any bug or issue with the Apify SDK, please submit an issue on GitHub.For questions, you can ask on Stack Overflow or contact support@apify.com
Contributing
Your code contributions are welcome and you'll be praised to eternity!If you have any ideas for improvements, either submit an issue or create a pull request.For contribution guidelines and the code of conduct,see CONTRIBUTING.md.
License
This project is licensed under the Apache License 2.0 -see the LICENSE.md file for details.
Acknowledgments
Many thanks to Chema Balsas for giving up the apify package nameon NPM and renaming his project to jsdocify.
-
问题内容: 我正在尝试使用GET方法发送一个json对象。我的代码: 但是,收到的标头将“ Content-Length”设置为零,因此服务器上的json解析器无法读取内容。 我已经尝试设置内容长度标头,但是它仍然以零的形式出现在服务器上: 任何想法如何使它工作?它必须是GET请求。 问题答案: GET请求至少通常是没有消息正文。如文档中所述,jQuery将GET请求追加到url参数。您应该能够使
-
问题内容: 在JSF2中,是否可以使用Ajax请求动态更改ui:include的src值(例如PrimeFacesp:commandButton)?谢谢。 那就是我现在所拥有的。是否有可能使它成为Ajax(使用p:commandButton)? 问题答案: 另一个答案中提出的JSTL标签不是必需的,并且不能很好地重用。 这是一个使用纯JSF的基本示例(假设您运行Servlet 3.0 / EL 2
-
问题内容: 我有一个基于jquery的单页webapp。它通过AJAX调用与RESTful Web服务进行通信。 我正在尝试完成以下任务: 将包含JSON数据的POST提交到REST URL。 如果请求指定JSON响应,则返回JSON。 如果请求指定PDF / XLS / etc响应,则返回可下载的二进制文件。 我现在有1&2,并且客户端jquery应用通过基于JSON数据创建DOM元素在网页上显
-
本文向大家介绍jQuery中如何将数组转化为json字符串,然后再转化回来?相关面试题,主要包含被问及jQuery中如何将数组转化为json字符串,然后再转化回来?时的应答技巧和注意事项,需要的朋友参考一下
-
问题内容: 我希望能够从Java操作方法中的JSON字符串访问属性。只需说一下即可使用该字符串。下面是该字符串的示例: 在此字符串中,每个JSON对象都包含其他JSON对象的数组。目的是提取ID列表,其中任何给定对象都具有包含其他JSON对象的group属性。我将Google的Gson视为潜在的JSON插件。谁能提供某种形式的指导,说明如何从此JSON字符串生成Java? 问题答案: 我将Goog
-
问题内容: 我在文件中有此: 我编写了以下脚本来打印所有数据: 但是,该程序会引发异常: 如何解析并提取其值? 问题答案: 你的数据不是有效的格式。你有什么时候应该拥有: 用于JSON数组,在Python中称为 用于JSON对象,在Python中称为 JSON文件的外观如下: 然后,你可以使用你的代码: 有了数据,你现在还可以找到类似的值: 试试看,看看是否有意义。