
iFLearner是一个强大且轻量的联邦学习框架,提供了一种基于数据隐私安全保护的计算框架, 主要针对深度学习场景下的联邦建模。其安全底层支持同态加密、秘密共享、差分隐私等多种加密技术, 算法层支持各类深度学习网络模型,并且同时支持Tensorflow、Mxnet、Pytorch等主流框架。
架构
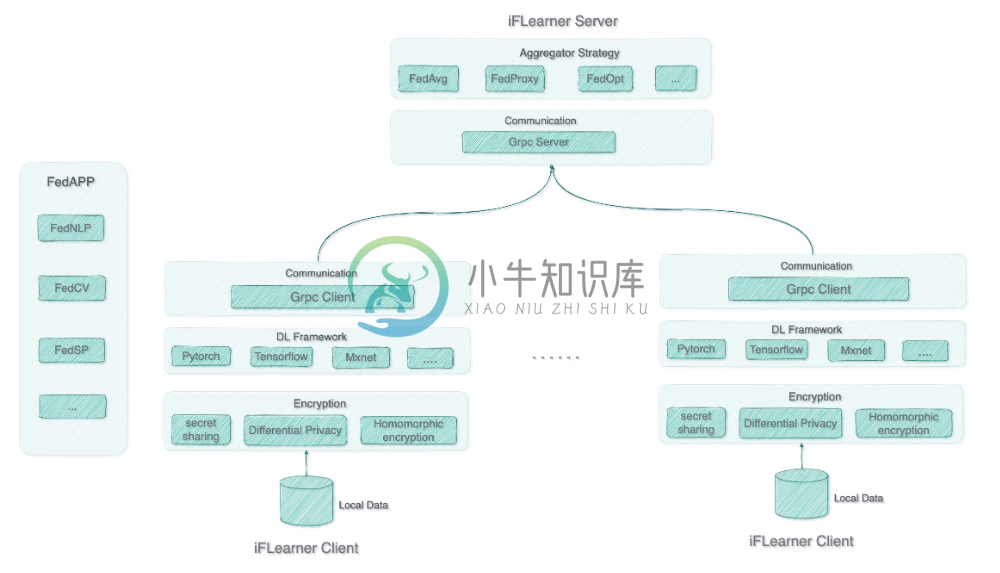
iFLearner主要基于以下原则进行设计:
-
事件驱动机制: 使用事件驱动的编程范式来构建联邦学习,即将联邦学习看成是参与方之间收发消息的过程, 通过定义消息类型以及处理消息的行为来描述联邦学习过程。
-
训练框架抽象: 抽象深度学习后端,兼容支持Tensorflow、Pytorch等多类框架后端。
-
扩展性高:模块式设计,用户可以自定义聚合策略,加密模块,同时支持各类场景下的算法。
-
轻量且简单:该框架Lib级别,足够轻量,同时用户可以简单改造自己的深度学习算法为联邦学习算法。
-
问题内容: 我一直在使用jQuery在基于Web的应用程序中完成整个AJAX魔术。但是,我来到了一个决定,我并不需要所有这些神奇功能jQuery有,除了它的AJAX功能(例如,,,和)。 您能推荐轻量级的跨浏览器AJAX库/框架(最大10 kb)吗? 问题答案: 您可以通过删除不需要的模块来缩小jQuery的大小,只需修改Makefile文件即可。
-
JavaScript 是一个轻量级的,面向对象的解释编程语言,允许我们交互的建成其他静态 HTML 网页。
-
主要内容 课程列表 基础知识 专项课程学习 参考书籍 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 MDP和RL介绍8 9 10 11 Berkeley 暂无 链接 MDP简介 暂无 Shaping and policy search in Reinforcement learning 链接 强化学习 UCL An Introduction to Reinforcement Lea
-
除了agent和环境之外,强化学习的要素还包括策略(Policy)、奖励(reward signal)、值函数(value function)、环境模型(model),下面对这几种要素进行说明: 策略(Policy) ,策略就是一个从当环境状态到行为的映射; 奖励(reward signal) ,奖励是agent执行一次行为获得的反馈,强化学习系统的目标是最大化累积的奖励,在不同状态下执行同一个行
-
强化学习(Reinforcement Learning)的输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。 Deep Q Learning.
-
本文向大家介绍轻松学习C#的String类,包括了轻松学习C#的String类的使用技巧和注意事项,需要的朋友参考一下 字符串是由零个或多个字符组成的有限序列,是几乎所有编程语言中可以实现的非常重要和有用的数据类型。在C#语言中,字符串是System.String类的一个引用类型,但与其他引用类型不同的是,C#将字符串视为一个基本类型,可以声明为一个常量,并可以直接赋值。由于C#中的字符串是由Sy