
xxHash 是一种极快的哈希算法,在 RAM 速度限制下运行。它成功完成了 SMHasher 测试套件,该套件评估了哈希函数的碰撞、分散和随机性质量。代码具有高度的可移植性,所有平台上的哈希值都相同(little / big endian)。
它有四种版本(XXH32、XXH64、XXH3_64bits和XXH3_128bits)。最新的变体,XXH3,提供了全面的性能改进,特别是在小数据上。
参考系统使用英特尔 i7-9700K cpu,并运行 Ubuntu x64 20.04。开源基准测试程序是用 clang v10.0编 译的,使用- O3flag。
| Hash Name | Width | Bandwidth (GB/s) | Small Data Velocity | Quality | Comment |
|---|---|---|---|---|---|
| XXH3 (SSE2) | 64 | 31.5 GB/s | 133.1 | 10 | |
| XXH128 (SSE2) | 128 | 29.6 GB/s | 118.1 | 10 | |
| RAM sequential read | N/A | 28.0 GB/s | N/A | N/A | for reference |
| City64 | 64 | 22.0 GB/s | 76.6 | 10 | |
| T1ha2 | 64 | 22.0 GB/s | 99.0 | 9 | Slightly worse collisions |
| City128 | 128 | 21.7 GB/s | 57.7 | 10 | |
| XXH64 | 64 | 19.4 GB/s | 71.0 | 10 | |
| SpookyHash | 64 | 19.3 GB/s | 53.2 | 10 | |
| Mum | 64 | 18.0 GB/s | 67.0 | 9 | Slightly worse collisions |
| XXH32 | 32 | 9.7 GB/s | 71.9 | 10 | |
| City32 | 32 | 9.1 GB/s | 66.0 | 10 | |
| Murmur3 | 32 | 3.9 GB/s | 56.1 | 10 | |
| SipHash | 64 | 3.0 GB/s | 43.2 | 10 | |
| FNV64 | 64 | 1.2 GB/s | 62.7 | 5 | Poor avalanche properties |
| Blake2 | 256 | 1.1 GB/s | 5.1 | 10 | Cryptographic |
| SHA1 | 160 | 0.8 GB/s | 5.6 | 10 | Cryptographic but broken |
| MD5 | 128 | 0.6 GB/s | 7.8 | 10 | Cryptographic but broken |
XXH3 专为在长输入和小输入上都具有出色的性能而设计,如下图所示:
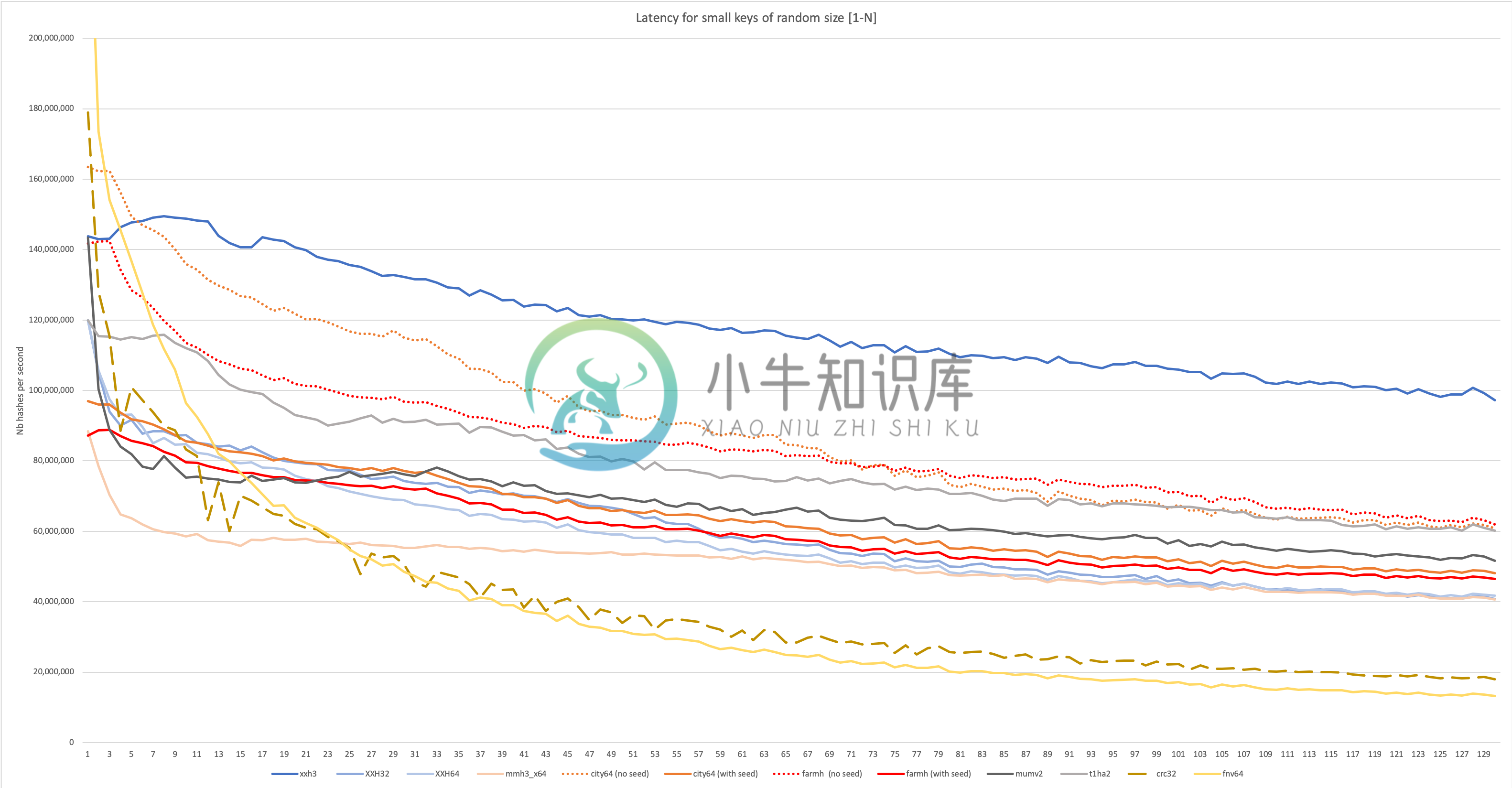
xxHash已经用Austin Appleby的优秀的SMHasher测试套件进行了测试,并通过了所有测试,确保了合理的质量水平。它还通过了SMHasher较新分叉的扩展测试,具有额外的场景和条件。
最后,xxHash提供了自己的大规模碰撞测试器,能够生成并比较数十亿的哈希值,以测试64位哈希算法的极限。在这方面,xxHash也具有良好的结果,与生日悖论一致。更详细的分析记录在 wiki 中。
-
Xxhash采用分流策略,将输入数据细分为四个独立的流。每个流每步处理一个4字节的块并存储一个临时字节state,最后一步将这四个states合并为一个。 xxhash32、xxhash64 update()–使用其他字符串更新当前摘要 digest()–返回当前摘要值 hexdigest()–以十六进制数字字符串形式返回当前摘要 intdigest()–以整数形式返回当前摘要 copy()–返回
-
xxHash是一个非常快的哈希算法,能在限制速度的RAM上运行。 它成功完成了SMHasher测试套件,它可以评估散列函数的冲突,色散和随机性。 代码非常便于携带,所有平台上的散列都相同(小/大)。测试对比参考:https://blog.csdn.net/tianshan2010/article/details/115775292 public class XXHash { private
-
Extremely fast non-cryptographic hash algorithm http://www.xxhash.com/ Extremely fast,超快,working at speeds close to RAM limits。看了代码,作者对 memcpy 这样的 CRT 函数都要去追究性能,嫌弃它在一些平台/编译器组合下,只是次优解;而且处处可见对内存对齐的优化。总之
-
问题内容: 我想知道什么是Java哈希算法的最佳和最快实现,尤其是MD5和SHA-2 512(SHA512)或256。我想要一个函数来获取字符串作为参数并返回哈希作为结果。谢谢你 编辑:这是用于将每个URL映射到唯一的哈希。由于MD5在这方面的可靠性不高,因此我对寻找SHA-2算法的最佳和最快实现更感兴趣。请注意,我知道即使SHA-2可能也会为某些URL产生相同的哈希,但是我可以接受。 问题答案:
-
我想向用户展示他们的客户端工具也可能生成的散列,因此我一直在比较在线散列工具。我的问题是关于它们的散列形式,因为奇怪的是,它们是不同的。 在快速搜索之后,我用5进行了测试: http://www.convertstring.com/hash/sha256 http://www.freeformatter.com/sha256-generator.html#ad-output http://onli
-
我刚刚讨论了散列码的概念,遇到了一行:
-
主要内容:哈希表是什么,哈希查找算法哈希查找算法又称 散列查找算法,是一种借助哈希表(散列表)查找目标元素的方法,查找效率最高时对应的时间复杂度为 O(1)。 哈希查找算法适用于大多数场景,既支持在有序序列中查找目标元素,也支持在无序序列中查找目标元素。讲解哈希查找算法之前,我们首先要搞清楚什么是哈希表。 哈希表是什么 哈希表(Hash table)又称 散列表,是一种存储结构,通常用来存储多个元素。 和其它存储结构(线性表、树等)
-
本文向大家介绍一致性哈希算法?相关面试题,主要包含被问及一致性哈希算法?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 一致性哈希算法在1997年由麻省理工学院提出,设计目标是为了解决因特网中的热点(Hot pot)问题,初衷和CARP(缓冲阵列路由协议,Cache Array Routing Protocol)十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT(D
-
你需要在这个练习中实现下面这三个哈希函数: FNV-1a 以创造者Glenn Fowler、Phong Vo 和 Landon Curt Noll的名字命名。这个算法产生合理的数值并且相当快。 Adler-32 以Mark Adler命名。一个比较糟糕的算法,但是由来已久并且适于学习。 DJB Hash 由Dan J. Bernstein (DJB)发明的哈希算法,但是难以找到这个算法的讨论。它非
-
一致性哈希算法 tencent2012笔试题附加题 问题描述: 例如手机朋友网有n个服务器,为了方便用户的访问会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器。 已有的做法是根据ServerIPIndex[QQNUM%n]得到请求的服务器,这种方法很方便将用户分到不同的服务器上去。但是如果一台服务器死掉了,那么n就变为了n-1,那么ServerIPIndex[QQNUM%n]与S
-
问题内容: 我目前正在尝试了解为Python的内置数据类型定义的哈希函数背后的机制。该实现显示在底部,以供参考。我特别感兴趣的是选择此分散操作的原理: 每个元素的哈希值在哪里。有人知道这些来自哪里吗?(也就是说,是否有任何特定的原因来选择这些数字?)还是只是简单地任意选择了它们? 这是来自官方CPython实现的代码片段, 以及Python中的等效实现: 问题答案: 除非Raymond Hetti