
KiokuDB 是一个 Perl 语言的持久化对象映射框架,基于 Moose 框架。
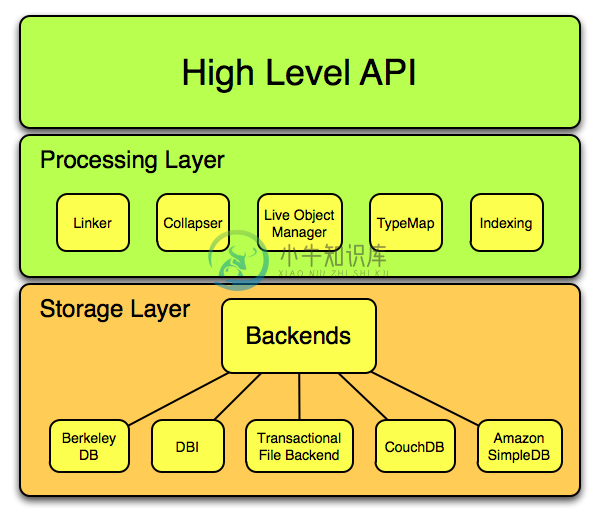
-
名称 方法 实现 Hibernate 优势 劣势 Mybaties Jpa get 1. Hibernate 1.1 单独使用 1.1.1 For Idea 新建项目:【File】——>【New】——>【Project】——>【Java】——>【Hibernate、JavaEE Persistence】 添加数据连接驱动 配置数据源 根据数据库表生成实体类:【Persistence】——>【名称】
-
Akka持久化使有状态的actor能留存其内部状态,以便在因JVM崩溃、监管者引起,或在集群中迁移导致的actor启动、重启时恢复它。Akka持久化背后的关键概念是持久化的只是一个actor的内部状态的的变化,而不是直接持久化其当前状态 (除了可选的快照)。这些更改永远只能被附加到存储,没什么是可变的,这使得高事务处理率和高效复制成为可能。有状态actor通过重放保存的变化来恢复,从而使它们可以重
-
Spark通过在操作中将其持久保存在内存中,提供了一种处理数据集的便捷方式。在持久化RDD的同时,每个节点都存储它在内存中计算的任何分区。也可以在该数据集的其他任务中重用它们。 我们可以使用或方法来标记要保留的RDD。Spark的缓存是容错的。在任何情况下,如果RDD的分区丢失,它将使用最初创建它的转换自动重新计算。 存在可用于存储持久RDD的不同存储级别。通过将对象(Scala,Java,Pyt
-
Redis 支持持久化,即把数据存储到硬盘中。 Redis 提供了两种持久化方式: RDB 快照(snapshot) - 将存在于某一时刻的所有数据都写入到硬盘中。 只追加文件(append-only file,AOF) - 它会在执行写命令时,将被执行的写命令复制到硬盘中。 这两种持久化方式既可以同时使用,也可以单独使用。 将内存中的数据存储到硬盘的一个主要原因是为了在之后重用数据,或者是为了防
-
不要害怕文件系统! Kafka 对消息的存储和缓存严重依赖于文件系统。人们对于“磁盘速度慢”的普遍印象,使得人们对于持久化的架构能够提供强有力的性能产生怀疑。事实上,磁盘的速度比人们预期的要慢的多,也快得多,这取决于人们使用磁盘的方式。而且设计合理的磁盘结构通常可以和网络一样快。 关于磁盘性能的关键事实是,磁盘的吞吐量和过去十年里磁盘的寻址延迟不同。因此,使用6个7200rpm、SATA接口、RA
-
Spark 有一个最重要的功能是在内存中_持久化_ (或 缓存)一个数据集。
-
Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中。当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些 数据可以被这个集合(以及这个集合衍生的其他集合)的动作(action)重复利用。这个能力使后续的动作速度更快(通常快10倍以上)。对应迭代算法和快速的交互使用来说,缓存是一个关键的工具。 你能通过persi
-
我正在研究Axon框架,我很难理解命令状态的自动持久性。 我已经查看了有关命令模型存储库的文档,根据我的理解,只要有正确的依赖关系,标准存储库的命令模型的状态应该是自动持久化的。这种观点也出现在我看过的另一篇博客/教程中(您可能需要向下滚动到存储库部分)。 更新 根据Steven的注释(以及随后的注释),我决定尝试并实现一个状态存储的聚合,但是我发现聚合的(de)序列化存在一个问题。我已经将聚合发