
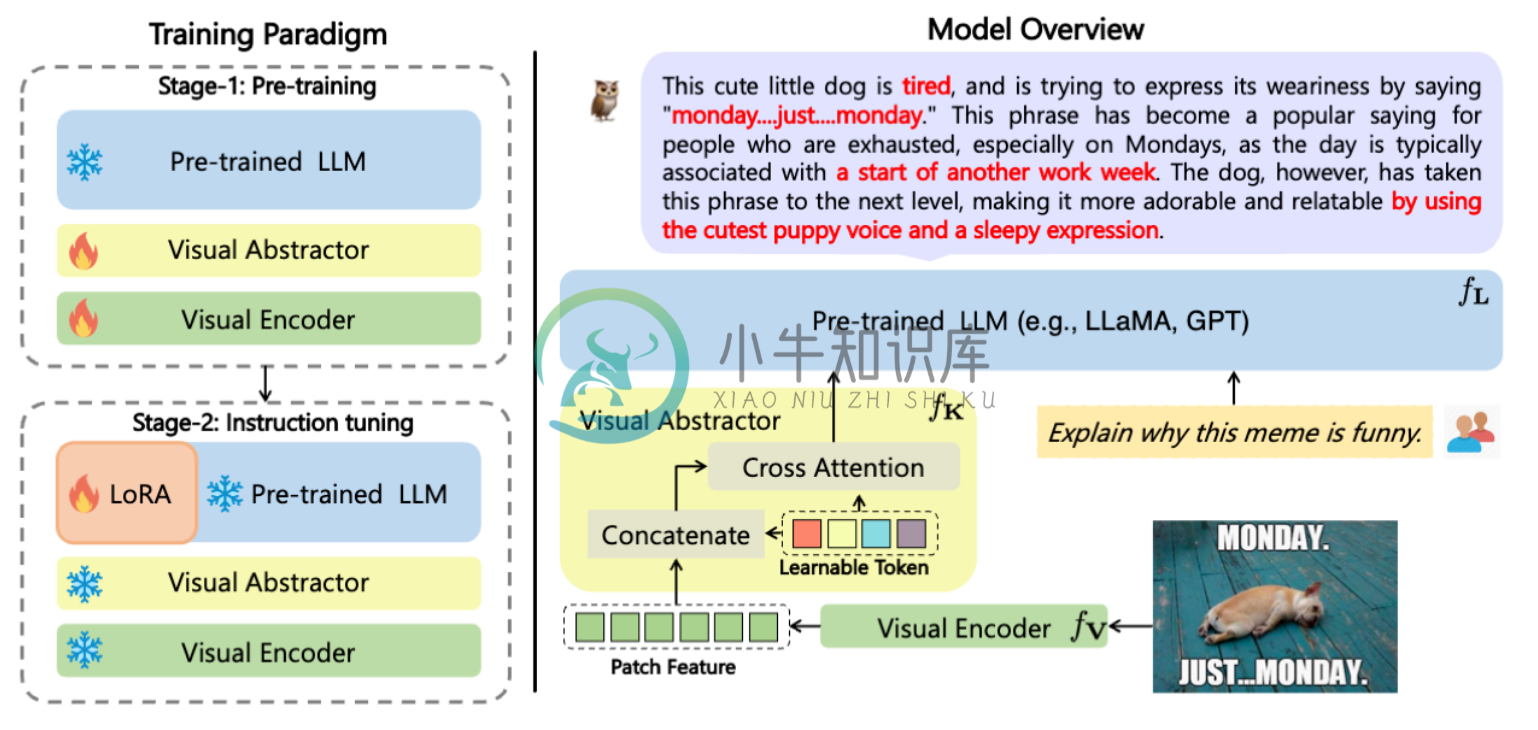
阿里达摩院提出的多模态GPT的模型:mPLUG-Owl,基于 mPLUG 模块化的多模态大语言模型。它不仅能理解推理文本的内容,还可以理解视觉信息,并且具备优秀的跨模态对齐能力。

示例

亮点特色
- 一种面向多模态语言模型的模块化的训练范式。
- 能学习与语言空间相适应的视觉知识,并支持在多模态场景下进行多轮对话。
- 涌现多图关系理解,场景文本理解和基于视觉的文档理解等能力。
- 提出了针对视觉相关指令的测评集OwlEval,用以评估多模态语言模型的对带有视觉信息上下文的理解能力。
- 我们在模块化上的一些探索:
- 即将发布
- 在HuggingFace Hub上发布。
- 多语言支持(中文、日文等)。
- 在多图片/视频数据上训练的模型
- Huggingface 在线 Demo (done)
- 指令微调代码(done)
- 视觉相关指令的测评集OwlEval(done)
预训练参数
| Model | Phase | Download link |
|---|---|---|
| mPLUG-Owl 7B | Pre-training | 下载链接 |
| mPLUG-Owl 7B | Instruction tuning | 下载链接 |
| Tokenizer model | N/A | 下载链接 |
-
本体(Ontology) 用来获取某个领域的知识。 OWL Ontology 是一种描述领域概念和概念间关系的方式,不同方式有不同好处。OWL更容易描述和定义概念,可以用简单概念表示复杂概念,可以用推理机检查本体中的陈述和否定是否正确。 OWL Ontology由个体(Individuals)、属性(Properties)、类(Classes)组成。 个体(Individuals)代表领域中的一个
-
在链接的当前文档示例中: https://github.com/owlcs/owlapi/blob/version5/contract/src/test/java/org/semanticweb/owlapi/examples/Examples.java 没有如何从本地文件加载本体的示例.只有一种方法可以从字符串加载它. 在过去我使用owl-api版本3 以下代码完美运行: OWLOntology
-
jena是一个java 的API,用来支持语义网的有关应用,学习jena需要了解XML 、RDF、 Ontology、OWL等方面的知识。具体来讲,需要知道什么是本体以及如何利用工具(如protege等)建立本体,要能读懂和手动编写RDF、XML,对OWL也要熟悉。 jena是用java实现的,其应用也通常是采用java的,所以初学者还需要一定的java技术基础,否则学起来会很麻烦。如果不具
-
OWL http://www.runoob.com/rdf/rdf-owl.html OWL 是一门供处理 web 信息的语言。 什么是 OWL? OWL 指的是 web 本体语言 OWL 构建在 RDF 的顶端之上 OWL 用于处理 web 上的信息 OWL 被设计为供计算机进行解释 OWL 不是被设计为供人类进行阅读的 OWL 由 XML 来编写 OWL 拥有三种子语言 OWL 是一项 we
-
转载自本文,以供个人查阅,感谢作者,查看原文请点击 OWL属性 1.属性概述 RDF/OWL里都是用二元关系来描述东西的,比如描述:比尔盖茨是一个人,在RDF/OWL里就是这样描述的:比尔盖茨 ——是——> 人。其中,比尔盖茨 和 人 之间的那个关系“——是——>”就是RDF/OWL里的属性。 属性:就是一个二元关系。OWL里包括两种属性: 1. 类型属性(datatype
-
------------------------------------------------------- rdfs:subClassOf 描述 <owl:Class rdf:ID="Wine"> <rdfs:subClassOf rdf:resource="&food;PotableLiquid"/> <rdfs:label xml:lang="en">wine</rdfs:l
-
1. 上来自我介绍 2. 问怎么搞那么多东西的,风格迁移怎么做的 3. 贡献在哪里,扮演着什么样的角色 4. 怎么双开两种方式 5. 在优图的工作做完了吗 他们好像很关注语音这个模态 6. 对代码考察,多头注意力伪代码 7. 升级成稀疏注意力 8. 一个赌博题,3个骰子,猜点数之和什么赢得概率大(3+18)//2=10 11 9. 反问:1. 是文心一言吗 2.做什么(数据侧的策略) 3. 还有技
-
ThinkCMF前台模板多语言是使用多模板的方式来实现的,如:当前模板是simplebootx,如果想开启英文前台模板的话,就只要加一个模板名为 simplebootx_en-us模板就可以了; 前台模板多语言实现原理: ThinkCMF在前台控制器加载模板文件时,会根据当前用户的浏览器语言或者用户指定的语言来加载模板文件,如果是中文用户就加载 simplebootx 里的模板文件,如果是英文用户
-
本文向大家介绍语言模型相关面试题,主要包含被问及语言模型时的应答技巧和注意事项,需要的朋友参考一下 语言模型的作用之一为消解多音字的问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。 目前使用kenlm(https://github.com/kpu/kenlm)训练bi-gram语言模型。bi-gram表示当前时刻的输出概率只与前一个时刻有关。即 P(X{n} | X{
-
语言模型(language model)是自然语言处理的重要技术。自然语言处理中最常见的数据是文本数据。我们可以把一段自然语言文本看作一段离散的时间序列。假设一段长度为$T$的文本中的词依次为$w_1, w_2, \ldots, w_T$,那么在离散的时间序列中,$w_t$($1 \leq t \leq T$)可看作在时间步(time step)$t$的输出或标签。给定一个长度为$T$的词的序列$
-
Hyperledger Composer包含一个面向对象的建模语言,用于定义业务网络定义的领域模型。 Hyperledger Composer CTO文件由以下元素组成: 一个单一的命名空间。文件中的所有资源声明都隐含在这个命名空间中。 一组资源定义,包括资产、交易、参与者和事件。 从其他命名空间导入资源的可选导入声明。 组织和Hyperledger Composer系统命名空间 你的组织命名
-
Sentinel 目前的多语言生态: Sentinel Go: https://github.com/alibaba/sentinel-golang Sentinel C++: https://github.com/alibaba/sentinel-cpp 更多的多语言版本欢迎社区贡献: Sentinel Node.js Sentinel Rust Sentinel PHP