
xDB-Replication 为开源的 PostgreSQL 数据库实现多主节点的数据复制解决方案。
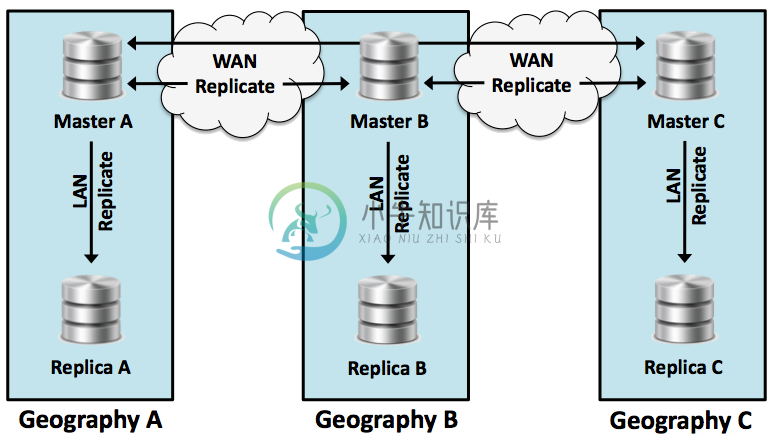
特点:
- Uniqueness, update and delete conflict detection
- Multiple conflict resolution strategies
- Replicate one or more tables
- Automatic Schema replication
- Publication table DDL replication
- Graphical replication console and CLI
- Flexible replication scheduler
- Replication history viewer
- Snapshot and continuous modes
-
set null "NULL VALUE" set feedback off set heading off set linesize 132 set pagesize 9999 set echo off set verify off set trimspool on col table_name for a30 col column_name for a30 col data_type fo
-
This is my Hook Com IFileOperation DLL code: //IFileOPHook.h #ifndef _H_IFILEOP_HOOK #define _H_IFILEOP_HOOK #ifdef __cplusplus extern "C" { #endif #include <windows.h> typedef WCHAR WPATH[MAX_PATH];
-
xDB 可以实现将来自 Oracle 和 SQL Server 的数据复制到 PostgreSQL 数据库上,这样做的目的: 节省在许可证上的费用 提升 OLTP 和报表性能 避免被供应商捆绑 下载前请阅读 EnterpriseDB Limited Use License
-
我在XDB数据库中有3个时间序列指标,类似于: 为了得到一组时间序列值,我有一个grafana图,它映射: ...对于三个值中的每一个。这提供了一个每分钟发生多少次调用、成功和失败的概念。通常,处理的
-
我有一个流入数据库,里面充满了值。这些值由Grafana提供。我需要的是根据选定的时间间隔获取实际值。 目前,我对单个指标有以下查询: 我想要的是从这个区间中减去最小的值,所以它只计算这个区间内的值。因此,图表需要从零开始。要从该间隔中获取最低值,我使用: 所以我认为像这样结合这两个(和子查询)应该可以: 不幸的是,这不起作用。该查询不被接受为子查询。
-
我正在使用XDB存储一些服务度量。这些是简单的指标,例如读取字节或活动连接。然后,我将在grafana的帮助下,在此基础上创作一些可视化作品。 将某些内容显示为“读取字节”非常简单,它基本上是按时间间隔对值进行汇总。 这是在“活动连接”上,我很难弄清楚。这些是连接到服务的tcp套接字,其中测量的是连接的套接字的数量;每当套接字连接或断开连接时,都会更新。 如果我只有一个服务实例,这很容易,我只需要
-
我们已经使用XDB设置了CollectD来收集度量。问题在于整合例如来自cpu1、cpu2和cpu3的指标。在collectd(至少是5.2版)中,可以启用“聚合”插件来完成我需要的任务。但我们使用的是Debian 7,而惊奇-collectd仅在5.1版中可用。 你们知道如何用grafana编写这样的正则表达式,这样我就不需要为每个cpu指定每个指标(下面它不起作用): 从“.cpu-{0-3}
-
我正在录制一系列的memory_used,例如使用的几个客户端的InphxDB数据库的Inphexdb-java客户端。数据看起来像这样: 我可以使用grafana轻松地将内存使用情况按标记分组,但是我找不到一种方法来汇总所有客户端的总内存消耗。当使用avg(使用内存)或sum(使用内存)时,值非常大且波动。我认为这是因为同一客户机的值可能会根据报告的时间间隔(不完全相同)求和多次。 在这种情况下