
PF_RING
可快速捕捉数据包,并进行分析和过滤。
PF_RING 是一种新型网络套接字,可显著提高数据包的捕获速度,并具有以下属性:
适用于 Linux Kernel 2.6.32 及更新版本
无需给内核打补丁:只需加载内核模块即可
独立的设备驱动
支持 Accolade, Exablaze, Endace, Fiberblaze, Inveatech, Mellanox, Myricom/CSPI, Napatech, Netcope and Intel (ZC) 网络适配器
基于内核的数据包捕获和采样
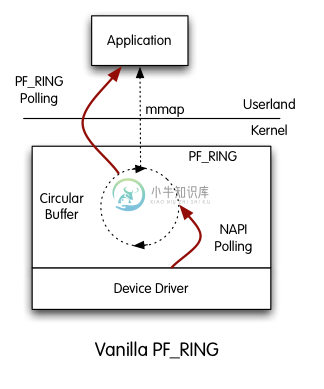
PF_RING 模块

-
一、初始环境,为最小化安装 [root@clusternode0xa3 /]# uname -r 3.10.0-862.el7.x86_64 二、保留安装包 [root@clusternode0xa3 etc]# cp yum.conf yum.conf.old [root@clusternode0xa3 etc]# vi yum.conf [root@clusternode0xa3 etc]#
-
官方网址:http://www.ntop.org/products/pf_ring/ 下载网址:http://sourceforge.net/projects/ntop/files/PF_RING/ Linux环境: Linux version 3.10.0-229.el7.x86_64 (builder@kbuilder.dev.centos.org) (gcc version 4.8.2 20
-
一 PF_RING简介 1.与libpcap不同,pf_ring核心思想是通过DMA将网卡流量直接MMAP到用户空间(绕过内核网络协议栈),避免libpcap的网卡->内核,内核→用户空间的方式,压缩拷贝次数,节省了CPU处理时间; 2.pf_ring每创建一个socket便分配一个环形缓冲区(ring_buffer),用户可以通过mmap直接访问ring_buffer,新数据从网卡抓取时可以直接
-
1. 简介 F_RING ™是一种新型的网络套接字,可显着提高数据包捕获速度, 并且具有以下特性: 1. 适用于 Linux 内核 2.6.32 及更高版本。 2. 无需修补内核:只需加载内核模块。 3. 使用商用网络适配器的 10 Gbit 硬件数据包过滤 4. 用户空间 ZC (新一代 DNA , Direct NIC Access ,直接 NIC 访问)驱动程序可实现极高的数据包捕 获 /
-
本文采用 PF_RING(8.0) 发行版本为例: libpcap 1.9.1(PF_RING修改支持PF_RING的发行版本,PF_RING(8.0)编译源码包内已经自带,自行编译即可) 以下是C++语言不引入 pfring.h 头文件,建议使用到的一些关键函数,“pcap_get_pfring” 宏可以从 pcap_t 类型之中获取到 pf_ring 的句柄(实为一个内存结构地址标识符) #i
-
1、下载pf_ring https://gitee.com/mirrors/PF-RING mirrors-PF-RING-7.6.0.zip 2、编译内核 [root@localhost ~]# cd /root/build_pfring [root@localhost build_pfring]# ls mirrors-PF-RING-7.6.0.zip [root@localhost bui
-
我正在开发一个windows应用程序,它以600Hz的频率从传感器接收数据。在五分之二的情况下,我的IO线程成功地从传感器读取4字节的数据,并将其传递给GUI线程。 问题是五次中有三次,QSerialPort有无法解释的超时,其中QSerialPort的waitForReadyRead()返回false和serial。errorString()有超时错误。在这种情况下,它将永远不会读取数据。如果我
-
是一个通用数据库处理框架(可以包含MSSQL POSTGRESQL,SQLITE EXCEL MYSQL DB2 ORACLE...只要你愿意实现接口就可以).很便捷地进行常用数据库操作(增删改查).其性能是几近纯ADO.NET.对于实体的查询采用emit实 现,如果您还不满意可用此框架的代码生成器直接生成纯ADO.NET SQL形式.其主要特色就是性能和便捷的操作.
-
我正在用c写一个抖动缓冲程序来处理rtp包。这里rtp使用UDP传输,所以连接不可靠,包会不整齐,也会有一些包丢失。如果包的顺序发生变化,我会通过序号(在rtp报头信息中)来排列,但是我怎么处理或者补偿包丢失呢?(因为包丢失不在我手上) 注意:我正在处理h264作为有效负载,他们要求我只使用RTP报头
-
我正在使用python来接收来自FPGA的UDP数据包流,试图尽可能少地丢失数据包。数据包速率从大约5kHz到某些MHz,我们希望在特定的时间窗口(代码中的acq_time)内获取数据。我们现在有了这个代码:
-
我有一个连续发送数据的UDP服务器。我要接收服务器发送的所有数据包。 在服务器端,我有两个线程。一个线程从文件中连续读取数据并放入Deque。另一个线程从deque读取数据并不断发送到UDP客户端。客户端代码不断地从服务器接收数据。
-
好吧,我对使用Scala/Spark还比较陌生,我想知道是否有一种设计模式可以在流媒体应用程序中使用大量数据帧(几个100k)? 在我的示例中,我有一个SparkStreaming应用程序,其消息负载类似于: 因此,当用户id为123的消息传入时,我需要使用特定于相关用户的SparkSQL拉入一些外部数据,并将其本地缓存,然后执行一些额外的计算,然后将新数据持久保存到数据库中。然后对流外传入的每条