
FlowJob任务调度框架,支持延时、定时、corn任务;任务分发支持随机、轮询、一致性哈希、广播、故障转移、MapReduce等模式;支持任务编排,DAG工作流,支持在工作流程中进行规则判断。
flowjob主要用于搭建统一的任务调度平台,方便各个业务方进行接入使用。 项目在设计的时候,考虑了扩展性、稳定性、伸缩性等相关问题,可以作为公司的任务调度中间件被使用。
功能介绍
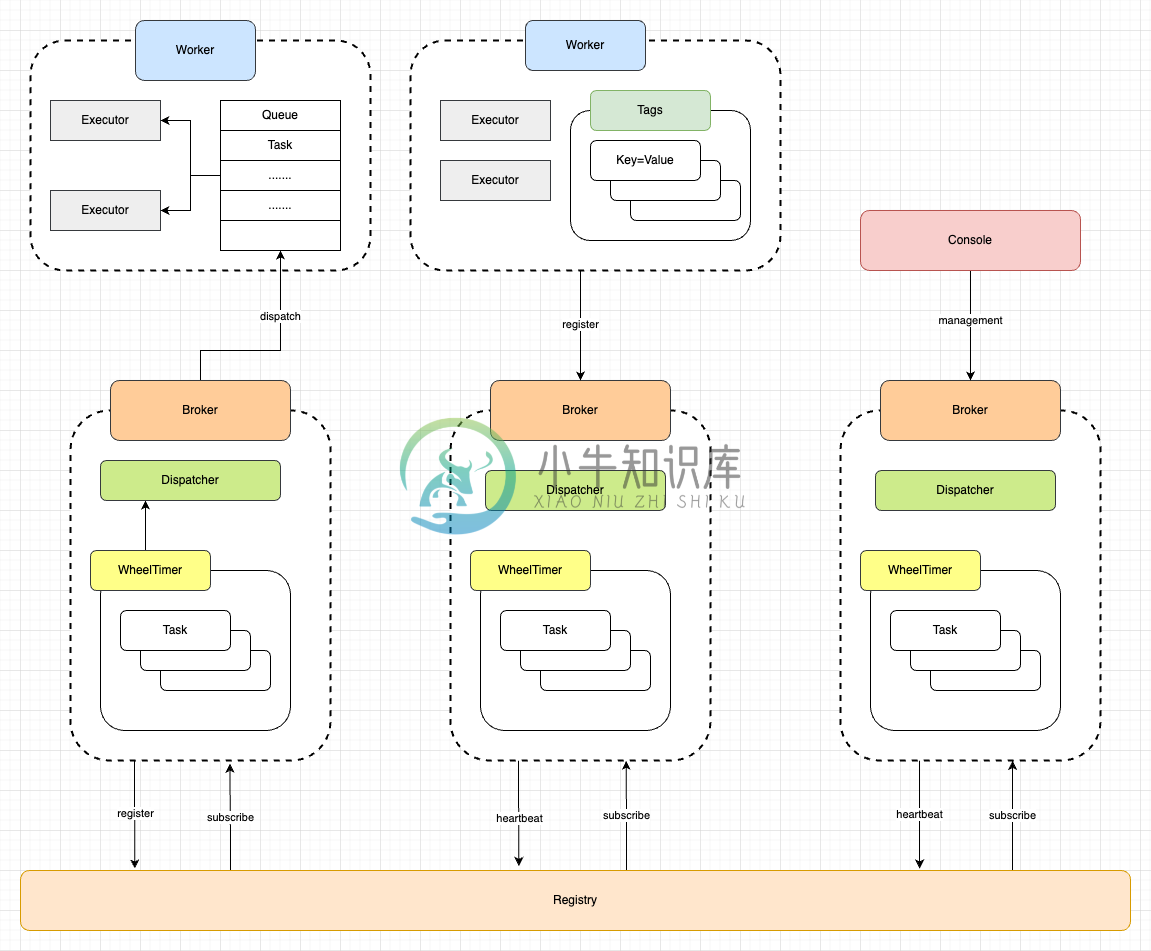
flowjob主要分为以下几个部分:
- Broker:中心节点,负责任务的调度。
- Worker:工作节点,主要负责任务的具体执行。
- Console:通过Broker提供的Api,进行任务创建/更新等一些管控操作。
- Registry:注册中心,目前使用DB做为注册中心。提供了对应接口,可以基于其它组件如zk、nacos等进行灵活的封装。
- Datasource:数据库用于持久化运行数据
调度类型
- 固定速度:作业创建后,每次调度下发后,间隔固定时间长度后,再次触发作业调度。
- 固定延迟:作业创建后,每次作业下发执行完成(成功或失败)后,间隔固定时间长度后,再次触发作业调度。
- CRON:通过CRON表达式指定作业触发调度的时间点。
负载策略
- 随机:将作业随机下发给某一个worker执行。
- 轮询:将任务逐个分配给worker。
- 最不经常使用:将作业下发给一个时间窗口内,接收作业最少的worker。
- 最近最少使用:将作业下发给一个时间窗口内,最长时间没有接受worker的worker。
- 一致性hash:同样参数的作业将始终下发给同一台机器。
- 指定节点:让作业指定下发到某个worker执行。
节点过滤方式
- 执行器:任务只会下发给包含任务对应执行器的worker。
- 标签:任务只会下发给包含指定标签的worker。
- 容量:基于worker的任务队列/CPU/内存使用情况过滤(TODO)
任务触发方式
- API:通过指定api触发任务执行。
- 调度:Broker自动组装数据,调度对应的任务。
任务类型
任务可以为单任务/工作流。单任务可以理解为只有一个节点的工作流任务。
- 普通:对应某个执行器,执行结束任务结束。
- 广播:在下发的时间点,对每个可下发的节点下发任务,所以子任务执行完成当前任务才执行完成。
- Map:分为split和map两个步骤。split的时候进行任务拆分,map则对每个拆分任务进行执行。
- MapReduce:相比于Map多了Reduce过程,可以对所有Map任务的执行结果进行一个汇总。
使用帮助
Server部署
环境要求
- JDK8
- Mysql
Step1: 数据库配置
目前使用flywaydb动态地进行数据初始化操作
| 配置项 | 说明 |
|---|---|
| spring.datasource.url | 连接地址 |
| spring.datasource.username | 账号 |
| spring.datasource.password | 密码 |
Step2: 服务打包
根据需要修改配置
| 配置项 | 说明 |
|---|---|
| flowjob.broker.name | 节点名称,保持全局唯一。默认不配置自动生成即可 |
| flowjob.broker.host | 提供给worker的服务的 host。可以是域名或 IP 地址,如不填写则自动发现本机非 127.0.0.1 的地址。多网卡场景下,建议显式配置 host。 |
| flowjob.broker.port | 提供给worker的服务 port 如果未指定此配置,则尝试使用 配置;如server.port配置;如{server.port} 配置也不存在,则使用 8080, |
| flowjob.broker.scheme | RPC 通信协议类型。默认为 http。于worker保持一致 |
| flowjob.broker.heartbeat-interval | broker心跳时间间隔,毫秒。默认2000 |
| flowjob.broker.heartbeat-timeout | broker心跳超时时间,毫秒。默认5000 |
| flowjob.broker.worker.heartbeat-timeout | worker心跳超时时间,毫秒。默认5000 |
项目根目录下,执行如下命令打包编译,通过-P参数指定环境,如开发环境为-P dev
mvn clean package -Dmaven.test.skip=true -P dev
Worker部署
对于需要使用worker的Web应用(宿主应用),可以参考Demo。
Step1: 添加依赖
对于Maven项目
<dependency>
<groupId>io.github.limbo-world</groupId>
<artifactId>flowjob-worker-spring-boot-starter</artifactId>
<version>1.0.1</version>
</dependency>
Step2: 修改配置
| 配置项 | 说明 |
|---|---|
| flowjob.worker.name | 节点名称,保持全局唯一。默认不配置自动生成即可 |
| flowjob.worker.scheme | RPC 通信协议类型。默认为 http。于broker保持一致 |
| flowjob.worker.host | RPC host。可以是域名或 IP 地址,如不填写则自动发现本机非 127.0.0.1 的地址。多网卡场景下,建议显式配置 host。 |
| flowjob.worker.port | RPC port 如果未指定此配置,则尝试使用 配置;如������.����配置;如{server.port} 配置也不存在,则使用 8080, |
| flowjob.worker.brokers | Broker节点地址,可配置多个,参考DEMO中的配置 |
| flowjob.worker.heartbeat | Worker 向 Broker 发送心跳请求的间隔,默认 2 秒。 |
| flowjob.worker.tags | 标签,k=v形式 |
参与贡献
如果你对本项目有任何建议或想加入我们的,可以通过下面方式:,欢迎提交 issues 进行指正。
- 报告 issue: github issues
- 提交PR:github PR
- 加入我们:ysodevilo@gmail.com
-
• Backorders are not generated for flow schedules because all the components have to be available for flow schedules otherwise no move orders are generated. • For the flow job, we need to pick all t
-
jenkins Build Flow job 输入参数获取和传递 如果设置Build Flow的job,怎样获取手工输入的参数。 1. 指定构建参数 job配置中,勾选“参数化构建” --> 添加2个string类型的参数 "bdate" ,"edate"。 2. 在 Flow DSL中获取参数 在工作流定义框中(Define build flow using flow DSL:)填写如下脚本 用
-
DataFlowJob:Dataflow类型用于处理数据流,必须实现 fetchData()和processData()的方法,一个用来获取数据,一个用来处理获取到的数据。 public class MyDataFlowJob implements DataflowJob<String> { public List<String> fetchData(ShardingContext sh
-
附:可以参考:Elastic-Job (一)实现Simple作业 对于Dataflow类型作业,官方文档给的解释是: 可通过DataflowJobConfiguration配置是否流式处理。 流式处理数据只有fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则作业将一直运行下去; 非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processDat
-
一般而言,常见的生产方式有单机(Single machine),平行机器(Parallel machines),流程工厂(Flow shop),零工工厂(Job shop)及开放工厂(Open shop)等数种. flow shop: 如果每个作业需要在每个处理机上加工,而且每个作业的工序也相同,即在处理机上加工的顺序相同,则这种多类机的环境称为同顺序作业或流水作业。 flow shop问题,n个
-
一、前序 如果你对elastic-job还不了解的话,建议你去看看我的《elastic-job分布式作业调度框架简介》,以下涉及到的参数配置请查看我的《elastic-job之Simple类型作业实现》 二、Dataflow是什么? Dataflow类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数
-
应用场景 电商公司在天猫,京东等多个平台运营,需要统计各平台的交易数据,所以定时将各平台订单汇总至运营系统,以便运营 模拟第三方订单 在前文基础上添加 模拟第三方订单,这里仅作为demo测试与实际业务无关 /** * 获取多少分订单 * * @param type 0 天猫 1 京东 * @param total * @return *
-
flow shop: n个工件在m台机器上加工,每个工件都要在m台机器上加工一次,并且每台机器上的工序,即加工顺序都是一样的。如四个工件在第一台机器加工顺序为2134,那么在剩余m-1台机器上的工序必须严格保持2134的顺序。因此flow shop也被称为流水作业或顺序作业。 job shop 每台机器的工序是可变的。因此job shop也被称为异序作业。同时,如果不限制工件j只能在机器m上加工一
-
简介 在过去,开发者必须在服务器上为每个任务生成单独的 Cron 项目。而令人头疼的是任务调度不受源代码控制,而且必须通过 SSH 连接到服务器上来增加 Cron 项目。 Laravel 的命令调度程序允许你在 Laravel 中对命令调度进行清晰流畅的定义。并且在使用调度程序时,只需要在服务器上增加一条 Cron 项目即可。调度是在 app/Console/Kernel.php 文件的 sche
-
基本任务调度 方案1: 通过 @Cron 注解,这个需要依赖 cron4j 框架: //1分钟执行一次 @Cron("*/1 * * * *") public class MyTask implements Runnable { @Override public void run() { System.out.println("task running...");
-
我刚刚更新了 Play!框架到版本 2.1 和 scala 到版本 2.10... 现在我的游戏!应用程序已损坏。似乎Akka API已经发生了变化。我找不到现在使用的阿卡版本,但我认为这是最后一个版本...... 我刚刚阅读了迁移指南:http://doc.akka.io/docs/akka/2.1.0/project/migration-guide-2.0.x-2.1.x.html。 我相应地
-
每隔一段时间需要调度任务执行,也许你想注册一个任务在客户端完成连接5分钟后执行,一个常见的用例是发送一个消息“你还活着?”到远端通,如果远端没有反应,则可以关闭通道(连接)和释放资源。 本节介绍使用强大的 EventLoop 实现任务调度,还会简单介绍 Java API的任务调度,以方便和 Netty 比较加深理解。 使用普通的 Java API 调度任务 在 Java 中使用 JDK 提供的 S
-
我使用spring调度器任务在固定间隔后调用类中的方法,如下所示 一旦调度程序触发init方法。init方法将使用线程池执行器来执行队列中的所有作业。 问题:执行init方法的初始线程是否会等待init方法中的所有处理(由executor service通过生成新线程来完成)完成? 调度器任务的池大小属性仅用于触发任务,而不是用于执行或处理被触发任务内部的逻辑。
-
项目中有一个要求,该要求将具有将完成某些工作的计划任务。 该项目是基于Spring的,计划的作业将是应用程序大战的一部分。我以前从未实现过这种功能。 我听说过Quartz。此外,我在某处读到Spring提供了一些功能来安排任务。所以,我在想如果我已经在使用Spring,那么为什么要使用其他API(Quartz)。 我不确定使用哪一个?一个比另一个的优缺点是什么? 请提出满足我要求的最佳方式。