
Hogwatch 可以监控你的网络连接占用情况,是一个宽带监控器,可以显示每个进程的网络传输情况,当前还是 Alpha 版本。
要求:
-
nethogs (0.8.2 +)
-
python 2.7
安装(开发):
-
git clone https://github.com/akshayKMR/hogwatch.git -
cd hogwatch -
pip install -r requirements.txt -
sudo python setup.py install -
run with
sudo ./hogwatch -
optional
sudo ./hogwatch serverfor only server accessible at localhost:6432
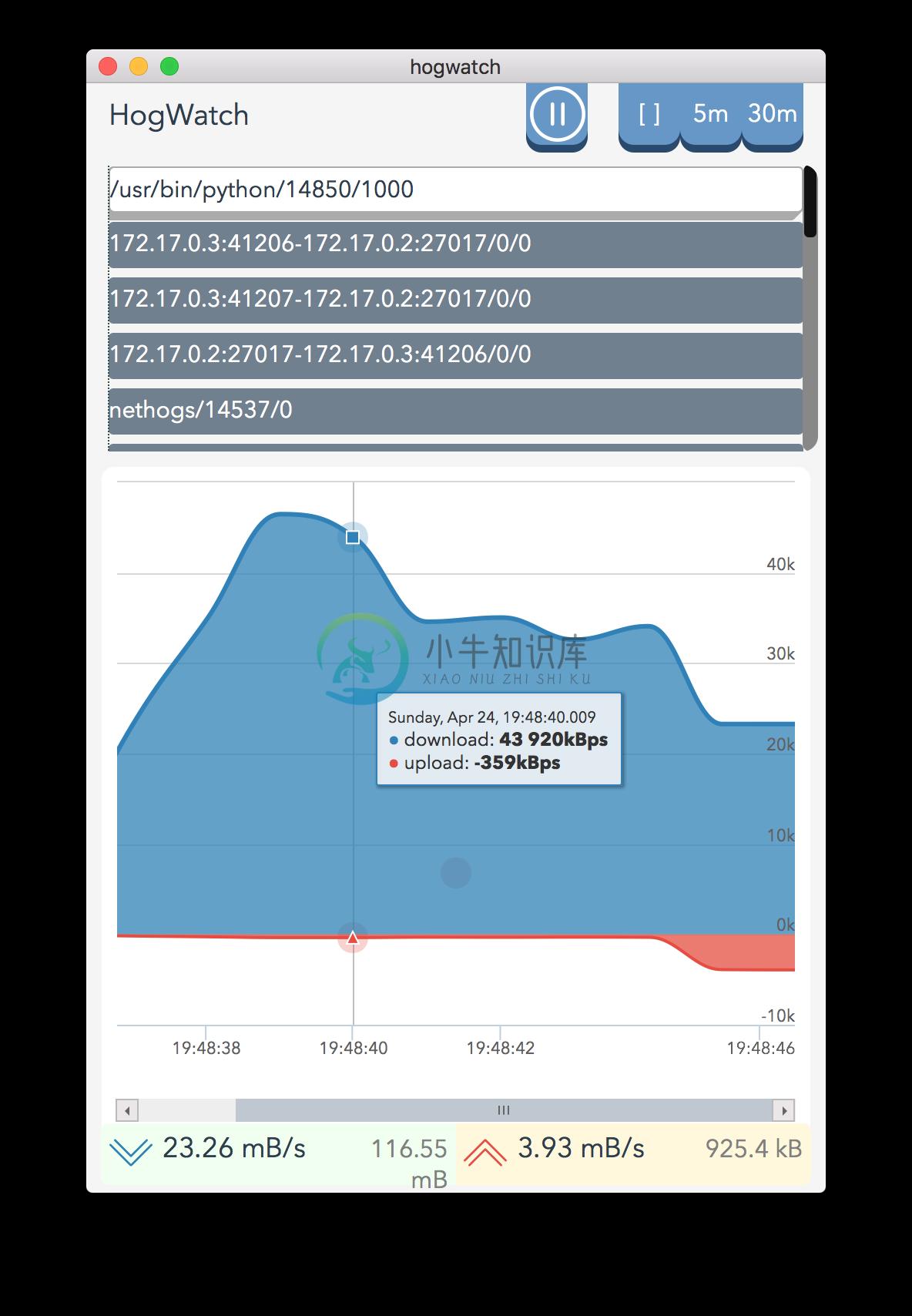

-
tcpdump 命令行语法基本命令 tcpdump -nn 参数 描述 Verbose 定义日志输出级别: -v -vv -vvv v 越多,输出的日志越详细。示例 tcpdump -nn -v Snaplen -s SIZE RHEL 6 之后的 tcpdump 抓取数据包时每个包的默认抓取长度为 65535 字节,而旧版本(RHEL5 之前)的 tcpdump 每个包默认抓取长度为 68 字节
-
问题内容: 我可以在Java监视程序上创建网络流量吗?该程序必须控制从计算机程序(包括OS模块)到网络驱动程序再返回的所有网络流量。如果是,如何? 注意: 我不仅要监视流量,还要对其进行控制。我想在Windows NT上实现这样的系统。仅靠Java无法实现它。如何在JNI的帮助下执行它? 也许是另一个变体。我不熟悉Windows服务,但仍然如此。我将在C 上编写一个程序并将其注册为Windows服
-
本文向大家介绍Shell脚本编写Nagios插件监控程序资源占用,包括了Shell脚本编写Nagios插件监控程序资源占用的使用技巧和注意事项,需要的朋友参考一下 一般情况下,我们只需要监控程序进程在没在就可以了。但是这次遭遇了这样的事,公司开发的程序,程序进程还在,但是死锁了。导致大范围的影响,更要命的是根本不知道问题出在哪里,还是别的测试部同事帮忙发现的,真是丢尽运维的脸了… 为避免下次再遭遇
-
我对普罗米修斯很陌生。我目前是一名在职学生,我的任务是为运行在客户端的服务器构建一个监控系统(我们无法访问)。我已经在客户端安装了节点导出器和从Prometheus服务(Ubuntu VM、Kubernetes节点)。我们有一个集中的主Prometheus服务器和托管在AWS上的Grafana,但它无法连接到客户端Prometheus服务器。 有没有什么方法可以让从Prometheus将指标推送到
-
上节课我们学习了怎样用 Prometheus 来自动发现 Kubernetes 集群的节点,用到了 Prometheus 针对 Kubernetes 的服务发现机制kubernetes_sd_configs的使用,这节课我们来和大家一起了解下怎样在 Prometheus 中来自动监控 Kubernetes 中的一些常用资源对象。 前面我们和大家介绍过了在 Prometheus 中用静态的方式来监控
-
mbedtls 软件包采用了模块化的设计,可以使用 config.h 文件来进行功能模块的配置选择。 mbedtls 默认提供的 config.h 文件是一个通用的、全功能的配置,占用了非常大的 RAM 和 ROM 空间,但是保证了 SSL 握手和通讯的建立速度、稳定性、协议兼容性以及数据传输效率。但嵌入式设备受限于其有限的 RAM 和 ROM 空间,我们不得不牺牲速度来节省 RAM 空间,裁剪不
-
HTTP GET # urllib_request_urlopen.py from urllib import request response = request.urlopen('http://localhost:8080/') print('RESPONSE:', response) print('URL :', response.geturl()) headers = resp
-
本文向大家介绍docker cgroup 资源监控的详解,包括了docker cgroup 资源监控的详解的使用技巧和注意事项,需要的朋友参考一下 docker cgroup 资源监控的详解 1.cgroup术语解析: 2.资源监控的关键目录:cat读出 已使用内存: 分配的总内存: 已使用的cpu:单位纳秒 系统当前cpu: 例子 cpu使用率: (已使用2-已使用1)/(系统当前2-系统当前1