
HarvestText 是一个专注无(弱)监督方法,能够整合领域知识(如类型,别名)对特定领域文本进行简单高效地处理和分析的库。适用于许多文本预处理和初步探索性分析任务,在小说分析,网络文本,专业文献等领域都有潜在应用价值。
使用案例:
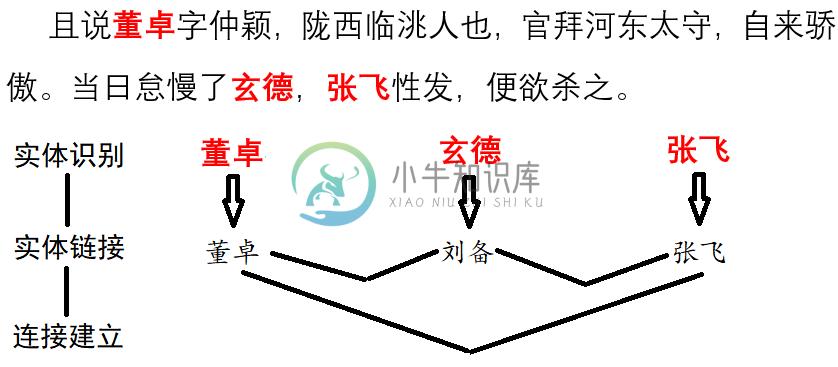
- 分析《三国演义》中的社交网络(实体分词,文本摘要,关系网络等)
- 2018中超舆情展示系统(实体分词,情感分析,新词发现[辅助绰号识别]等) 相关文章:一文看评论里的中超风云

【注:本库仅完成实体分词和情感分析,可视化使用 matplotlib】
具体功能如下:
- 基本处理
- 精细分词分句
- 可包含指定词和类别的分词。充分考虑省略号,双引号等特殊标点的分句。
- 文本清洗
- 处理URL, email, 微博等文本中的特殊符号和格式,去除所有标点等
- 实体链接
- 把别名,缩写与他们的标准名联系起来。
- 命名实体识别
- 找到一句句子中的人名,地名,机构名等命名实体。
- 实体别名自动识别(更新!)
- 依存句法分析
- 分析语句中各个词语(包括链接到的实体)的主谓宾语修饰等语法关系,
- 内置资源
- 通用停用词,通用情感词,IT、财经、饮食、法律等领域词典。可直接用于以上任务。
- 信息检索
- 统计特定实体出现的位置,次数等。
- 新词发现
- 利用统计规律(或规则)发现语料中可能会被传统分词遗漏的特殊词汇。也便于从文本中快速筛选出关键词。
- 字符拼音纠错(调整)
- 把语句中有可能是已知实体的错误拼写(误差一个字符或拼音)的词语链接到对应实体。
- 自动分段
- 使用TextTiling算法,对没有分段的文本自动分段,或者基于已有段落进一步组织/重新分段
- 存取消除
- 可以本地保存模型再读取复用,也可以消除当前模型的记录。
- 英语支持
- 本库主要旨在支持对中文的数据挖掘,但是加入了包括情感分析在内的少量英语支持
- 精细分词分句
- 高层应用
用法
首先安装, 使用pip
pip install --upgrade harvesttext
或进入setup.py所在目录,然后命令行:
python setup.py install
随后在代码中:
from harvesttext import HarvestText ht = HarvestText()
即可调用本库的功能接口。
-
安装harvesttext心得 之前采用的是python3.9安装harvesttext,导致过程中一直会出现jpype1构建失败。 Building wheels for collected packages: jpype1 Building wheel for jpype1 (setup.py) ... error ERROR: Command errored out with exi
-
HarvestText 文本挖掘和预处理工具 Github项目地址:https://github.com/blmoistawinde/HarvestText 文档地址:https://harvesttext.readthedocs.io/en/latest/ 569星标 (2020.05.24) 包含文本清洗、新词发现、情感分析、关系网络、简易问答系统等功能,Demo和文档都写得比较清楚,方便学习
-
1. 英文文本挖掘预处理特点 英文文本的预处理方法和中文的有部分区别。首先,英文文本挖掘预处理一般可以不做分词(特殊需求除外),而中文预处理分词是必不可少的一步。第二点,大部分英文文本都是uft-8的编码,这样在大多数时候处理的时候不用考虑编码转换的问题,而中文文本处理必须要处理unicode的编码问题。这两部分我们在中文文本挖掘预处理里已经讲了。 而英文文本的预处理也有自己特殊的地方,第三点就是
-
1. 中文文本挖掘预处理特点 首先我们看看中文文本挖掘预处理和英文文本挖掘预处理相比的一些特殊点。 首先,中文文本是没有像英文的单词空格那样隔开的,因此不能直接像英文一样可以直接用最简单的空格和标点符号完成分词。所以一般我们需要用分词算法来完成分词,在文本挖掘的分词原理中,我们已经讲到了中文的分词原理,这里就不多说。 第二,中文的编码不是utf8,而是unicode。这样会导致在分词的时候,和英文
-
现代分词都是基于统计的分词,而统计的样本内容来自于一些标准的语料库。假如有一个句子:“小明来到荔湾区”,我们期望语料库统计后分词的结果是:"小明/来到/荔湾/区",而不是“小明/来到/荔/湾区”。那么如何做到这一点呢? 从统计的角度,我们期望"小明/来到/荔湾/区"这个分词后句子出现的概率要比“小明/来到/荔/湾区”大。如果用数学的语言来说说,如果有一个句子S,它有m种分词选项如下:$$A_{11
-
你是如何记住一款车的 问你这样一个问题:如果你大脑有很多记忆单元,让你记住一款白色奥迪Q7运动型轿车,你会用几个记忆单元?你也许会用一个记忆单元,因为这样最节省你的大脑。那么我们再让你记住一款小型灰色雷克萨斯,你会怎么办?显然你会用另外一个记忆单元来记住它。那么如果让你记住所有的车,你要耗费的记忆单元就不再是那么少了,这种表示方法叫做localist representation。这时你可能会换另
-
句子分割text_to_word_sequence keras.preprocessing.text.text_to_word_sequence(text, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n',
-
句子分割text_to_word_sequence keras.preprocessing.text.text_to_word_sequence(text, filters=base_filter(), lower=True, split=" ") 本函数将一个句子拆分成单词构成的列表 参数 text:字符串,待处理的文本 filters:需要滤除的字符的列表或连接形成的字符串,例如标
-
Text Preprocessing [source] Tokenizer keras.preprocessing.text.Tokenizer(num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
-
预处理工具 不同的 CSS 预处理工具有着不同的特性、功能以及语法。编码习惯应当根据使用的预处理工具进行扩展, 以适应其特有的功能。推荐在使用 SCSS 时遵守以下指导。 将嵌套深度限制在1级。对于超过2级的嵌套,给予重新评估。这可以避免出现过于详实的 CSS 选择器。 避免大量的嵌套规则。当可读性受到影响时,将之打断。推荐避免出现多于20行的嵌套规则出现。 始终将@extend语句放在声明块的第