
Sogou Machine Reading Comprehension (SMRC) 是搜狗开源的机器阅读理解工具包,旨在帮助 NLP 从业人员快速实现已有的机器理解模型,从而更高效地开发新模型。
工具包架构
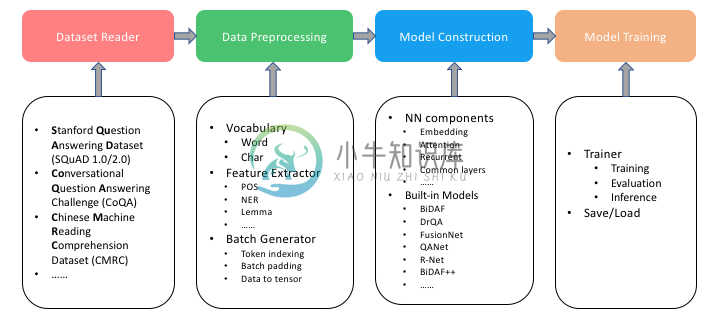
搜狗将机器阅读理解任务的流水线分解为4个步骤:数据集读取、预处理、模型构建、训练和评估,对每步都进行了抽象和模块化,以简洁的接口呈现。
在搜狗开源的 SMRC 工具包中,以上每个步骤都可以单独拿来使用,嵌入开发者自己的流程中,保证了整套工具的易用性和可扩展性。
同时,SMRC 对已发表的多种机器阅读理解数据集、模型进行了整合或复现。
代码主要分为以下几个模块:
1.数据集读取模块(dataset_reader)
该模块集成了对 SQuAD 1.0/2.0、CoQA 以及中文数据集 CMRC 的读取和预处理功能。
2.数据预处理(data、utils)
data 部分包含词表构建模块和负责特征变换和数据流的 batch 生成器。utils 用于提取语言学特征。
3.模型构建(nn、models)
nn(神经网络)由机器阅读理解中的常用组件组成,可以快速构建和训练原型模型,避免部分重复工作。model 中集成了常见的机器理解模型,如 BiDAF、DrQA、FusionNet、QANet 等等。
4.模型训练与评估(examples)
这一部分是运行不同模型的示例。
-
gPhone 手机上的RSS阅读器软件。
-
我有一个关于这个连接器的问题。如果我的Spark集群和Cassandra集群不在同一个集群上,读取如何工作?Spark是否将整个Cassandra表带入自己的集群并将其重新排列到Spark分区中?
-
本 repo 为《深入理解 Java 虚拟机 第2版》的阅读笔记,并对全书内容按照自己的理解进行了一定程度的整理。
-
下面是代码示例: 错误是: 错误:(17,13)value withFilter不是cats的成员。数据ReaderT[测试q.this.FailFast,映射[字符串,字符串],布尔值]b1 如何使用f2组合f1。f2必须仅在f1返回右(true)时应用。我通过以下方式解决了它: 但我希望有一个更优雅的解决方案。
-
当服务器对象的公共方法被调用时,这个名为“服务”的切入点会在程序的执行过程中挑出这些点。它还允许任何使用服务切入点的人访问其方法被调用的服务器对象。(摘自https://eclipse.org/aspectj/doc/released/progguide/language-anatomy.html) 我正在试图理解AspectJ的切入点,现在我有点困惑。我的主要问题是:您如何阅读上述切入点,以及如
-
在问题[1]中,我了解到如果您想在Android下使用NFC标签,则不必采用NDEF格式。我想在Win 8.1 in. Net下执行此操作。我的情况是这样的: 我有一个RFID卡Mifare Classic 1K,其中存储了一个ID。(由制造商记录)该ID由我们的考勤系统通过通常的RFID读取器(例如Gigatek的PROMAG MFR120)读取。我们不在卡上写任何东西,我们只需要读取ID。但是