
Mongo-Shake 由阿里云 Nosql 团队开发和维护。Mongo-Shake 是基于 MongoDB 的 oplog 的通用服务平台。它从源 mongo 数据库中获取 oplog,并在目标 mongo 数据库中重放或发送到不同隧道的其他端。如果目标端是mongo数据库,即直接replay oplog,它就像一个同步工具,用于将数据从源MongoDB复制到另一个MongoDB,以构建冗余复制或双活复制。
除了这种直接方式,还有其他隧道类型,如 rpc、file、tcp、kafka。用户编写的接收器必须定义自己的接口来分别连接到这些隧道。用户还可以定义自己的可插拔隧道类型。如果连接到kafka这样的第三方消息中间件,消费者可以灵活地在pub/sub模块中异步获取订阅者数据。
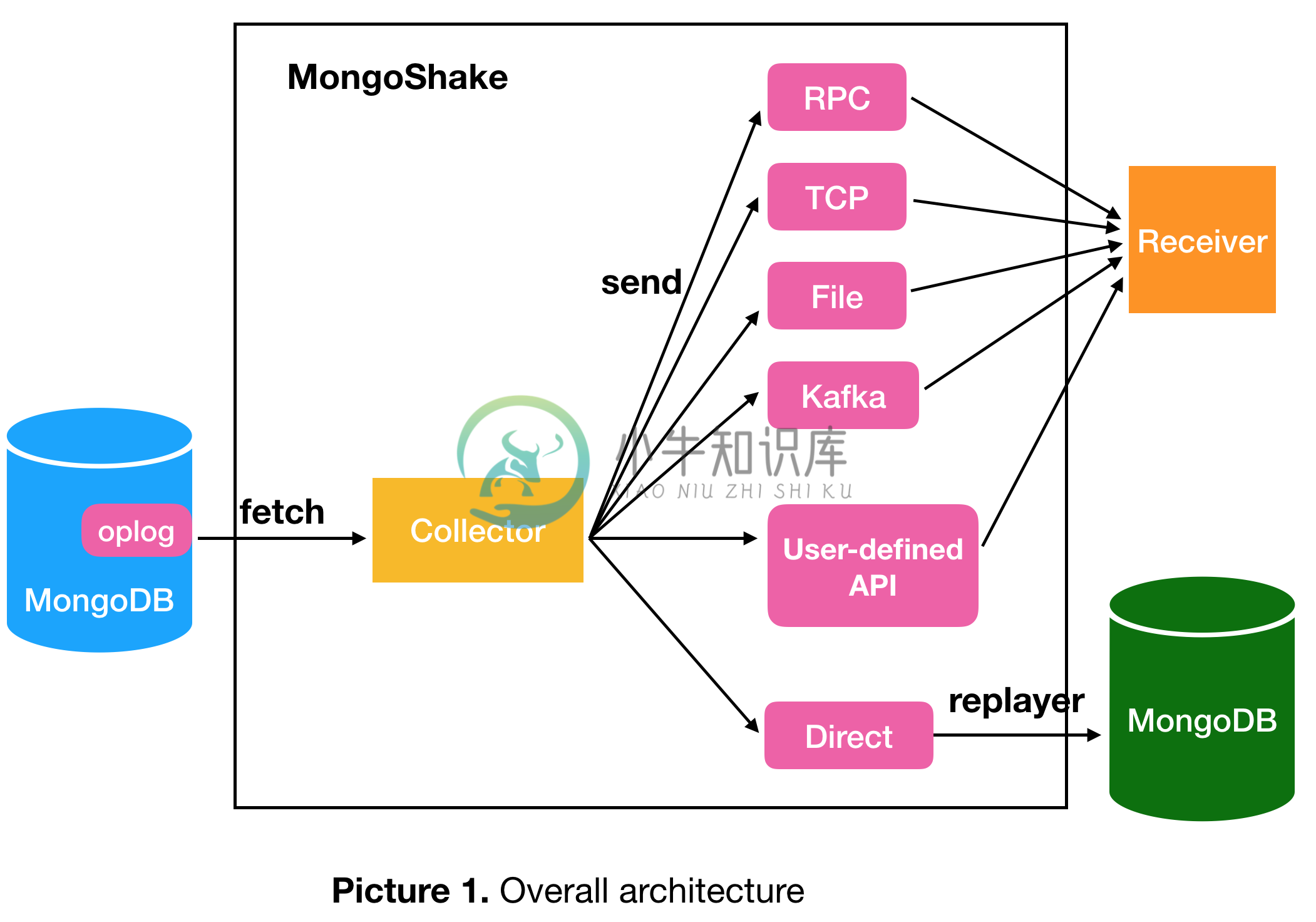
源可以是单个 mongod、副本集或分片,而目标可以是 mongod 或 mongos。如果源是副本集,官方建议从次要/隐藏中获取数据以减轻主要压力。如果源是分片,每个分片都应该连接到 Mongo-Shake。目标端可以有多个 mongos 以保持高可用性,不同的数据将被散列并写入不同的 mongos。
-
摘要: MongoShake是基于MongoDB的通用型平台服务,作为数据连通的桥梁,打通各个闭环节点的通道。通过MongoShake的订阅消费,可以灵活对接以适应不同场景,例如日志订阅、数据中心同步、监控审计等。其中,集群数据同步作为核心应用场景,能够灵活实现灾备和多活的业务场景。 背景 在当前的数据库系统生态中,大部分系统都支持多个节点实例间的数据同步机制,如Mysql Master/Slav
-
MongoShake操作说明 简介 MongoShake是一个以golang语言进行编写的通用的平台型服务,通过读取MongoDB集群的Oplog操作日志,对MongoDB的数据进行复制,后续通过操作日志实现特定需求。集群数据同步是其中核心应用场景,通过抓取oplog后进行回放达到同步目的,实现灾备和多活的业务场景。 MongoShake可以根据oplog进行多种操作,文档内主要介绍MongoSh
-
mongoShake是阿里云自研开源工具,该功能可用于数据分析、灾备和多活等业务场景。 MongoShake介绍 MongoShake是阿里云以Golang语言编写的通用平台型服务工具,它通过读取MongoDB的Oplog操作日志来复制MongoDB的数据以实现特定需求。 MongoShake还提供了日志数据的订阅和消费功能,可通过SDK、Kafka、MetaQ等方式的灵活对接,适用于日志订阅、数
-
使用mongoshake进行oplog同步读取,解决乱码问题 参考文章: (1)使用mongoshake进行oplog同步读取,解决乱码问题 (2)https://www.cnblogs.com/zhaosc-haha/p/12021444.html 备忘一下。
-
我正在尝试在两个MySQL集群之间使用单个复制通道设置复制。我已经看了mysql.com的文档几次了,但似乎不能让它正常工作。 我遇到的问题是,对未配置为主服务器的SQL节点进行的查询不会复制NDBCLUSTER表的任何INSERT、UPDATE或DELETE查询,然而,当我在作为主服务器的SQL节点上插入、更新或删除一行时,它会很好地复制到其他集群。 我知道复制是设置的,因为如果我在主集群中的任
-
本文详细描述了如何对 Kubernetes 上的 TiDB 集群进行数据备份和数据恢复。本文使用的备份恢复方式是基于 Helm Charts 实现的。 TiDB Operator 1.1 及以上版本推荐使用基于 CustomResourceDefinition (CRD) 实现的备份恢复方式实现: 如果 TiDB 集群版本 < v3.1,可以参考以下文档: 使用 Dumpling 备份 TiDB
-
现在k8s在2.3中直接与spark集成了,我的spark submit从控制台在kuberenetes master上正确执行,而没有运行任何spark master pods,spark处理k8s的所有细节: 我正在尝试做的是做一个火花-提交通过AWS lambda到我的k8s集群。以前,我直接通过spark master REST API(不使用kubernetes)使用该命令: 而且奏效了
-
我有Hadoop3.0集群(为了学习目的),1个name-node和3个slave。在每个节点上,hdfs-site.xml如下所示: 在此输入图像说明
-
问题内容: 我正在本地计算机上的Tomcat 7上设置群集/复制,以评估它是否可与我的环境/代码库一起使用。 建立 我在不同端口上运行的同级目录中有两个相同的tomcat服务器。我已经在其他两个端口上监听了httpd,并作为VirtualHosts连接到了两个tomcat实例。我可以在配置的端口上访问两种环境并与之交互。一切都按预期进行。 Tomcat服务器在server.xml中启用了集群功能:
-
本文向大家介绍基于docker搭建redis集群的方法,包括了基于docker搭建redis集群的方法的使用技巧和注意事项,需要的朋友参考一下 下载redis镜像 取别名 删除原先的镜像标签 启动6个节点的redis容器 注意网络用的是net1 创建的容器默认是没有启动,所以需要一个一个启动 进入任意一个容器例如r1 然后利用ruby脚本启动集群 输入yes即可创建成功,执行脚本时终端输出