
kpfs是一款基于FUSE开发的用户空间文件系统,实现了在Linux中对快盘的基本操作。当文件系统挂载到Linux的某个文件夹下,用户只需像普通文件一样操作自己快盘中的目录和文件。
kpfs的特点
- 基于FUSE的文件系统
- 基于kuaipan.cn API
- 使用了这些基础软件:liboauth, fuse, glib, curl, json-c
- 支持gobject 反射,支持javascript和python绑定。
kpfs实现的功能
kpfs挂载到linux文件系统
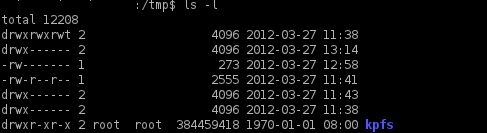
2 快盘指定目录下的文件属性查询
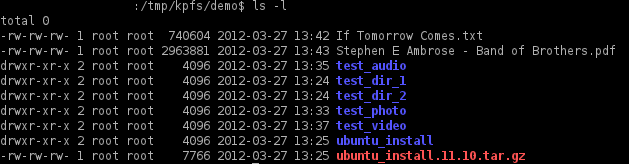
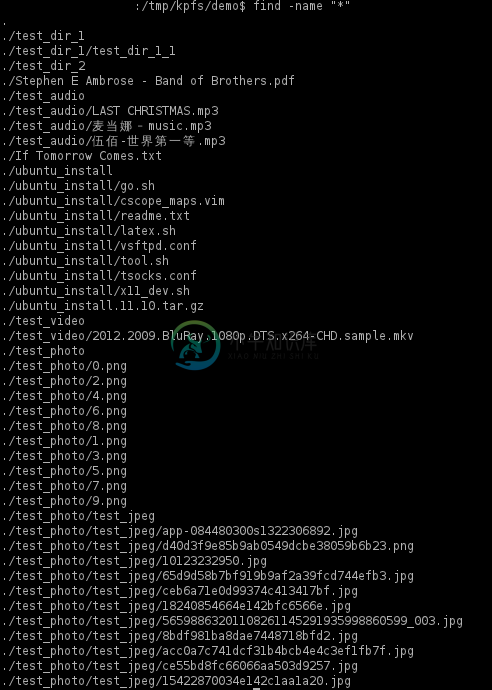
3 快盘中某个文件位置查找
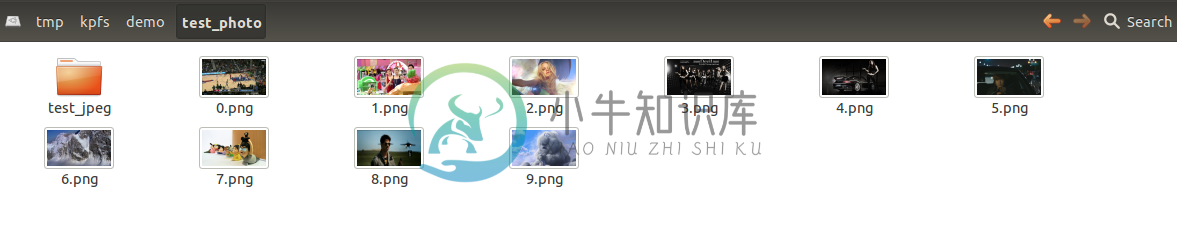
4 各种类型文件thumbnail的显示
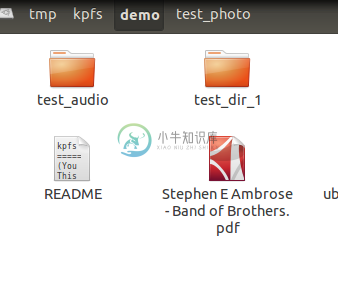
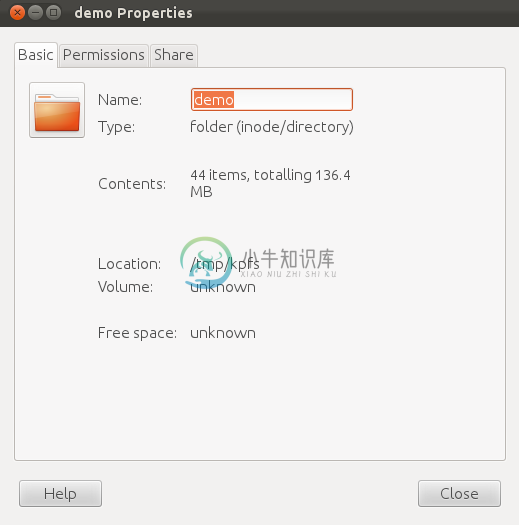
5 文件夹属性的获取
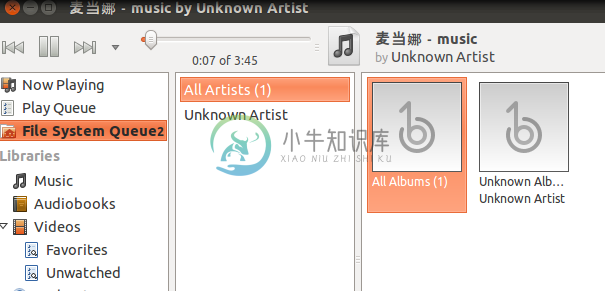
6 快盘里的文件读写
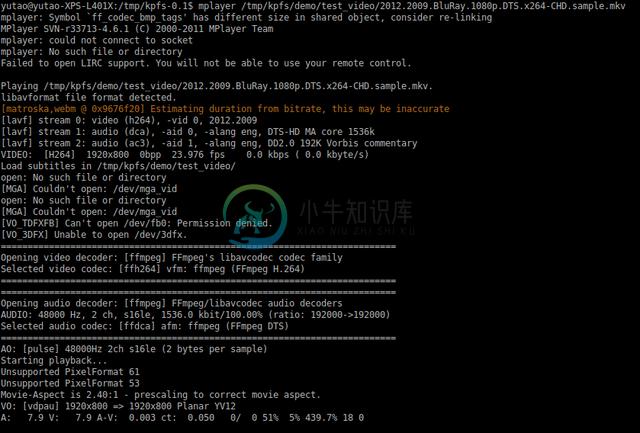
7 中文文件名支持
8 文件系统的统计信息查询
实现原理
KPFS通过FUSE来获取用户文件操作的指令,转而通过KPFS自行分装的文件操作函数,最终调用kuaipan.cn提供的API,实现对快盘文件的操作。 通过libcurl 库,来实现http报文的发送和接收,通过glib库实现KPFS文件系统inode节点的建立,查询,删除,插入。通过json-c库,实现对快盘服务器响应报文的解析。
-
转载时请注明出处和作者联系方式:http://blog.csdn.net/mimepp 作者联系方式:YU TAO <yut616 at sohu dot com> 关键字: 快盘,linux,ubuntu, open API,liboauth,json-c,fuse 近来看到 快盘 开放了 API,所以就基于 linux FUSE 实现了一个 filesystem,并作为 open source
-
kpfs is a filesystem for accessing kuaipan.cn based on FUSE. ===================================================== (You can use it in commercial software, but please let me know.) This application
-
Ceph v0.55 及后续版本默认开启了 cephx 认证。从用户空间( FUSE )挂载一 Ceph 文件系统前,确保客户端主机有一份 Ceph 配置副本、和具备 Ceph 元数据服务器能力的密钥环。 在客户端主机上,把监视器主机上的 Ceph 配置文件拷贝到 /etc/ceph/ 目录下。 sudo mkdir -p /etc/ceph sudo scp {user}@{server-mac
-
在HDFS的上下文中,我们有Namenode和Datanode,说Namenode存储了文件系统名称空间是什么意思? 还有,我们为datanode指定的目录(在hdfs-core.xml中)是唯一可以存储数据的地方,还是我们可以指定任何其他目录来保存数据?
-
所有的用户空间事件都以process开头。你可以通过进程ID指定要检测的进程,也可以通过可执行文件名的路径名指定。SystemTap会查看系统的PATH环境变量,所以你既可以使用绝对路径,也可以使用在命令行中运行可执行文件时所用的名字。 由于SystemTap静态分析放置探针的位置时离不开调试信息,一些用户空间事件需要给定PID或可执行文件的路径(以下将两者统称为PATH)。不过大多数proces
-
问题内容: 我阅读了LKD 1中的一些段落,但 我无法理解以下内容: 从用户空间访问系统调用 通常,C库提供对系统调用的支持。用户应用程序可以从标准标头中提取函数原型,并与C库链接以使用您的系统调用(或库例程,后者又使用syscall调用)。但是,如果您只是编写了系统调用,则怀疑glibc是否已支持它! 幸运的是,Linux提供了一组宏,用于包装对系统调用的访问。它设置寄存器内容并发出陷阱指令。这
-
问题内容: 一般情况是,我们有一个服务器集群,并且我们想使用Docker在服务器集群之上建立虚拟集群。 为此,我们为不同的服务(Hadoop,Spark等)创建了Dockerfile。 但是,关于Hadoop HDFS服务,我们面临这样一种情况,即Docker容器可用的磁盘空间等于服务器可用的磁盘空间。我们希望限制每个容器的可用磁盘空间,以便我们可以动态生成具有一定存储大小的附加数据节点,以构成H
-
问题内容: 我在Linux上使用Python 2.6。最快的方法是什么: 确定哪个分区包含给定的目录或文件? 例如,假设已安装在和上。我想从琴弦中取出那副。 然后,获取给定分区的使用情况统计信息?例如,给定我想要获得分区的大小和可用的可用空间(以字节为单位或大约以兆字节为单位)。 问题答案: 如果您只需要设备上的可用空间,请参阅下面的使用答案。 如果您还需要与文件关联的设备名称和安装点,则应调用外