
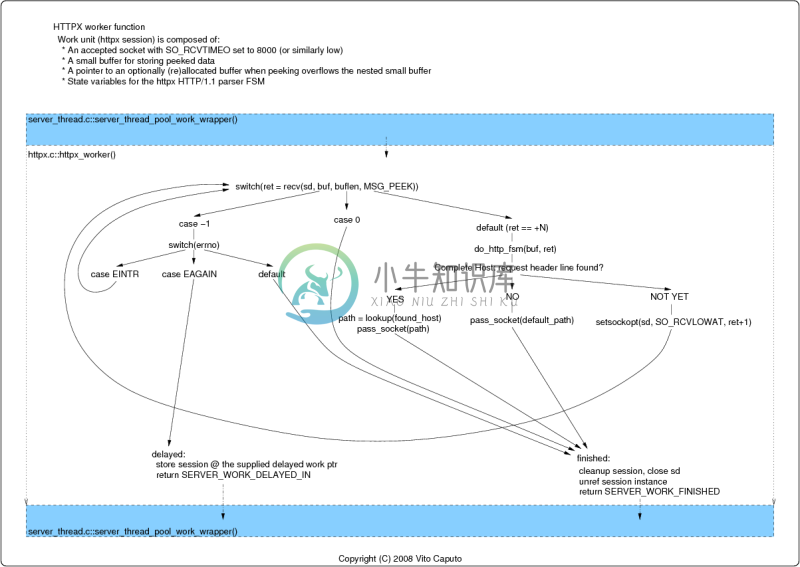
Httpx 接管了虚拟主机服务器前端绑定的主机和端口,通过扫描HTTP请求中的头信息Host,通过配置数据库查询,一旦发现符合某一特定要求,就把请求传递给本地文件系统中的一个UNIX域套接字。在此UNIX域套接字,一个跨进程描述符传发生到Web服务器改性略有收到的TCP套接字描述符通过在UNIX域套接字的不是具有约束力的,听的,并接受TCP套接字。这使得vhosts共享一个IP地址,同时独立的、基于Host的HTTP运行环境。
-
欢迎来到 Python Httpx 教程。在本教程中,我们将深入探讨 Httpx 库,并学习如何使用它来构建高性能的异步网络应用程序。 什么是 Httpx? Httpx 是一个 Python 库,它提供了一个现代化的、易于使用的 HTTP 客户端和服务器。Httpx 可以与 Python 的异步框架协同工作,并支持 WebSocket 和 HTTP/2。Httpx 具有极佳的性能和安全性,并支持对
-
HTTPX是Python3的功能齐全的HTTP客户端,它提供同步和异步API,并支持HTTP/1.1和HTTP/2 安装 pip install httpx 创建请求 通过httpx库发出一个请求非常简单,如下: import httpx response = httpx.get('https://www.baidu.com/') print(type(response), response)
-
使用httpx 1、背景 使用urllib和requests库已经可以爬取绝大部分网站的数据,但对于某些网站任然无能为力,因为这些网站强制使用HTTP/2.0协议访问,这时使用urllib和requests是无法爬取数据的,因为这两个库只支持HTTP/1.1,这个时候就需要用到httpx库了 2、基本使用 1、安装 # 这样安装不支持HTTP/2.0 pip install httpx # 安装
-
导入httpx In [25]: import httpx 获取一个网页 In [26]: r = httpx.get("https://httpbin.org/get") In [27]: r Out[27]: <Response [200 OK]> 同样,发送HTTP POST请求: In [28]: r = httpx.post("https://httpbin.org/post",
-
httpx简单介绍(http1和http2) httpx虽然支持http2,但是默认是http1。发出高度并发的请求,可能需要考虑尝试 HTTP/2 支持(http的版本区别:从技术角度来看,两者最大的区别就是二进制框架层,其中http1.1把所有的请求和响应作为纯文本,而http2是把所有的消息封装成二进制,且仍然保持http语法,http2比http1.1传输信息更加灵活),所以在爬取的时候容
-
安装命令: pip install httpx 请求方式 GET import httpx headers = {'user-agent': 'my-app/1.0.0'} params = {'key1': 'value1', 'key2': 'value2'} url = 'https://httpbin.org/get' r = httpx.get(url, headers
-
关于python异步网络请求库httpx的两个坑 其一:httpx.ReadTimeout 实测发现,网络不稳定的情况下,极其容易出现该错误。 相对于requests库, httpx库是有默认的超时时间的。 参考方案: 初始化时将timeout 赋值为 None 例1: client = httpx.AsyncClient(timeout=None) 例2: httpx.get(url=url,
-
详细注释记录在代码中。。。 # 文档地址https://www.python-httpx.org/ import httpx # pip install httpx # pip install httpx[http2] import asyncio import time # headers = {'user-agent': 'my-app/1.0.0'} # params = {'key1'
-
import asyncio from httpx import AsyncClient #声明该方法为异步方法对象 async def printNum(num): $ 异步版的with as async with AsyncClient() as client: # 等待函数完成 req = await client.get(url="")
-
一般使用python写爬虫大部分用的是requests库,但是这个库只能同步,想要提高速度只能使用多线程的方式,但是当需要爬取的url数量增多的时候,使用python的requests库写爬虫会出现时间很长才能爬完一轮的情况,所以我们今天用httpx库的异步请求来加速爬取,单机爬虫实现分布式爬虫的速度。 PS:不建议爬少量网站的大量内页使用,最好是网站数量多的时候使用,这样可以避免频繁的请求被拉黑
-
代码 # -*- coding: utf-8 -*- # @Author : zbz import asyncio import random import ddddocr import httpx class AsyncSpider: def __init__(self, ocr=False): self.ocr = ddddocr.DdddOcr() if
-
httpx包的bug… 改源码的这个文件lib/python3.9/site-packages/httpx/_urlparse.py:149行左右: def urlparse(url: str = "", **kwargs: typing.Optional[str]) -> ParseResult: url = url.replace("::", ":") # Initial ba
-
import httpx link = '要请求的网页链接' r = httpx.get(link) 这里 r.text 返回的内容是中文乱码, 怎么办? 首先查看返回的html页面 header 中 Content-Type 的值是什么 <meta http-equiv="Content-Type" content="text/html; charset=big5"> 然后 r.encodi
-
异步支持 HTTPX默认情况下提供标准的同步API,但是如果需要,还可以为你提供异步客户端的选项 。要发出异步请求,你需要一个httpx.AsyncClient import asyncio import httpx async def main(): async with httpx.AsyncClient() as client: response = awai
-
两个虚拟主机(纯静态-html 支持) - Two Virtual Hosts, Serving Static Files http { : server { : listen 80; : server_name www.domain1.com; : access_log logs/domain1.access.log main; : location / {
-
主要内容:Apache虚拟主机类型,3. 虚拟主机配置示例Apache Web服务器可以在SAME服务器上托管多个网站。每个网站不需要单独的服务器机器和apache软件。这可以使用虚拟主机或VHost的概念来实现。 要在Web服务器上托管的任何域(网站应用)都将在apache配置文件中具有单独的条目。 Apache虚拟主机类型 Apache虚拟主机类型有两种 - 基于名称的虚拟主机 基于地址或基于IP的虚拟主机。 1. 基于名称的虚拟主机 基于名称的虚拟
-
虚拟主机是路由配置中的顶层配置。每个虚拟主机都有一个逻辑名称以及一组域列表,会根据传入请求的主机头路由到对应的域。这允许为单个监听器配置多个顶级域的路径树。一旦基于域选择了虚拟主机,就会进行路由处理,以便查找并路由到相应上游集群或者是否执行重定向。 { "name": "...", "domains": [], "routes": [], "require_ssl": "...",
-
虚拟主机名使用server_name指令定义,用于决定由某台虚拟主机来处理请求。具体请参考《nginx如何处理一个请求》。虚拟主机名可以使用确切的名字,通配符,或者是正则表达式来定义: server { listen 80; server_name example.org www.example.org; ... } server { liste
-
本文档试图解释一些在设置虚拟主机时经常问及的问题。这些示例向你展示了如何在一个服务器上通过基于域名的或是基于IP的虚拟主机来部署多个web站点。另一份关于如何在一个代理服务器后构建基于多个服务器的站点的说明文档也很快就会出来。 在一个IP地址上运行多个基于域名的web站点 您的服务器有只一个IP地址,而在DNS中有很多域名(CNAMES)映射到这个机器。您而您想要在这个机器上运行www.examp
-
本文档说明了如何使用基于域名的虚拟主机。 基于域名的虚拟主机和基于IP的虚拟主机比较 基于IP的虚拟主机使用连接的IP地址来决定相应的虚拟主机。这样,你就需要为每个虚拟主机分配一个独立的IP地址。而基于域名的虚拟主机是根据客户端提交的HTTP头中标识主机名的部分决定的。使用这种技术,很多虚拟主机可以共享同一个IP地址。 基于域名的虚拟主机相对比较简单,因为你只需要配置你的DNS服务器将每个主机名映
-
(我读过许多StackOverflow文章,解决MAMP中的vhost,但没有一篇解决了这个问题。) 我正试图在我的MacBook上设置一个虚拟主机。我使用的虚拟主机设置与我在Windows计算机上使用的完全相同,运行良好。 首先,我编辑了hosts文件。在添加了第一行: 接下来我编辑了/Applications/MAMP/conf/apache/httpd。配置并从vhost中删除,包括: 接下
-
术语"虚拟主机"是指在一个机器上运行多个网站(比如:www.company1.com和www.company2.com)。如果每个网站拥有不同的IP地址,则虚拟主机可以是"基于IP"的;如果只有一个IP地址,也可以是"基于主机名"的,其实现对最终用户是透明的。 Apache是率先支持基于IP的虚拟主机的服务器之一。1.1及其更新版本同时支持基于IP和基于主机名的虚拟主机,今后,不同的虚拟主机有时会