
Dplython是使用Python语言的Dplyr。Dplyr是一个使用R语言快速分析数据的库。 Dplyr的理念是在一些最常见的任务中限制数据操作的部分功能。这种映射思维更接近编码思维,帮助您在分析数据时提高“思维速度”。
安装:
pip install git+https://github.com/dodger487/dplython.git
使用:
from dplython import * diamonds >> select(X.carat, X.cut, X.price) >> head(5) """
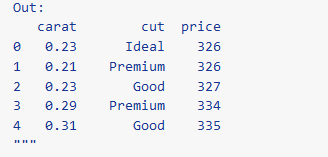
# Filter out rows using dfilter diamonds >> dfilter(X.carat > 4) >> select(X.carat, X.cut, X.depth, X.price) """
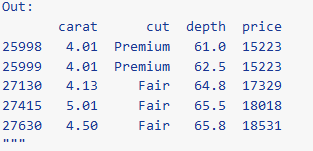
# Sample with sample_n or sample_frac, sort with arrange (diamonds >> sample_n(10) >> arrange(X.carat) >> select(X.carat, X.cut, X.depth, X.price))"""
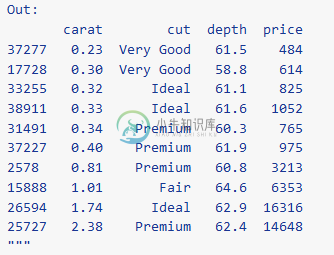
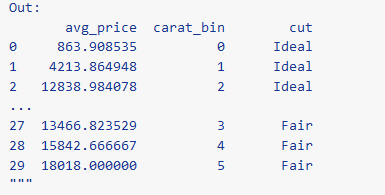
# You can: # add columns with mutate (referencing other columns!) # group rows into dplyr-style groups with group_by # collapse rows into single rows using sumarize (diamonds >> mutate(carat_bin=X.carat.round()) >> group_by(X.cut, X.carat_bin) >> summarize(avg_price=X.price.mean()))"""
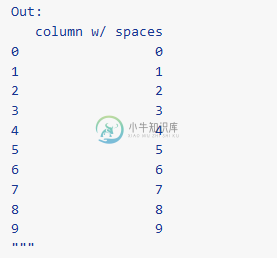
# If you have column names that don't work as attributes, you can use an # alternate "get item" notation with X. diamonds["column w/ spaces"] = range(len(diamonds)) diamonds >> select(X["column w/ spaces"]) >> head() """
# It's possible to pass the entire dataframe using X._ diamonds >> sample_n(6) >> select(X.carat, X.price) >> X._.T """

# To pass the DataFrame or columns into functions, apply @DelayFunction
@DelayFunctiondef PairwiseGreater(series1, series2):
index = series1.index
newSeries = pandas.Series([max(s1, s2) for s1, s2 in zip(series1, series2)])
newSeries.index = index return newSeries
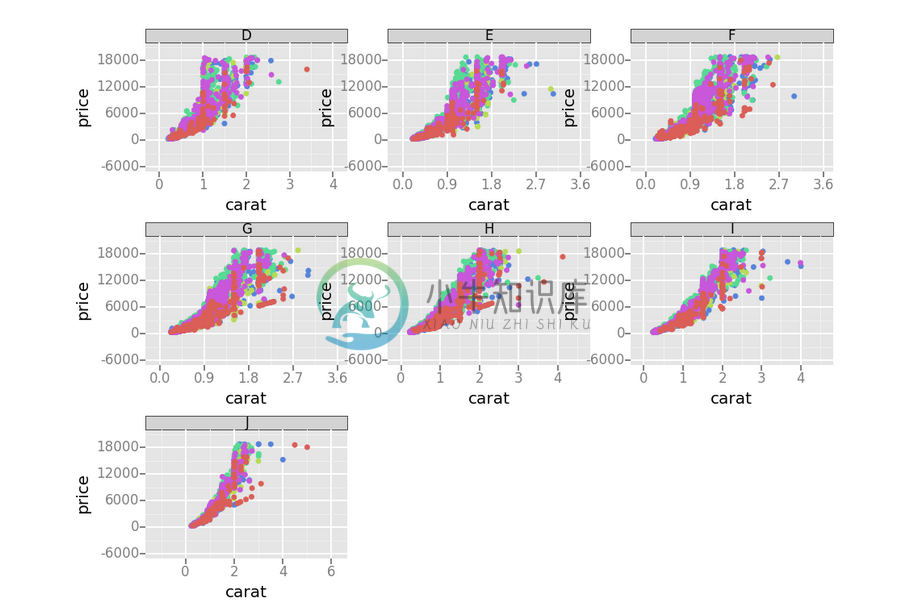
diamonds >> PairwiseGreater(X.x, X.y)# Passing entire dataframe and plotting with ggplotfrom ggplot import *ggplot = DelayFunction(ggplot) # Simple installationdiamonds = DplyFrame(pandas.read_csv('./diamonds.csv')) # Masked in ggplot pkg(diamonds >> ggplot(aes(x="carat", y="price", color="cut"), data=X._) +
geom_point() + facet_wrap("color"))
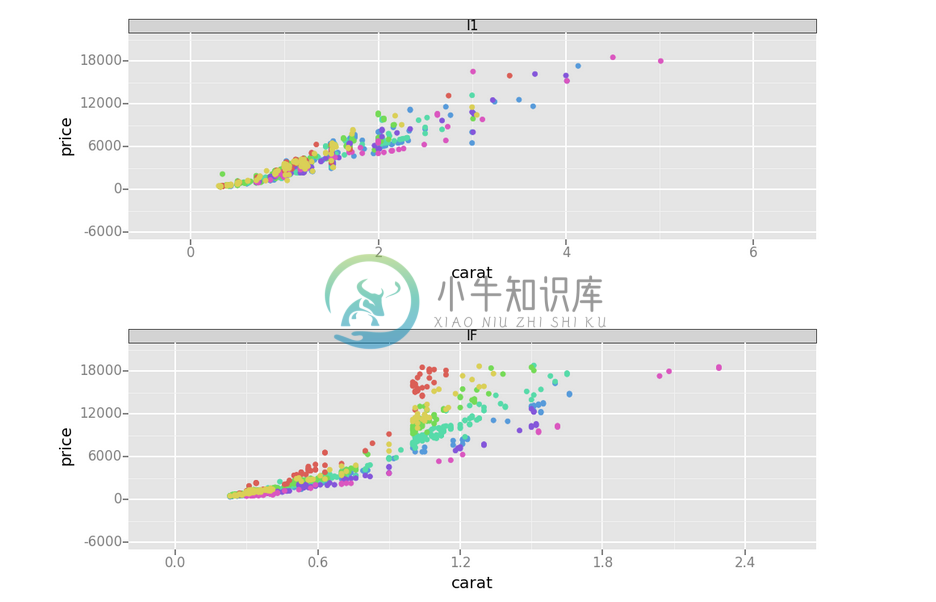
(diamonds >>
dfilter((X.clarity == "I1") | (X.clarity == "IF")) >>
ggplot(aes(x="carat", y="price", color="color"), X._) +
geom_point() +
facet_wrap("clarity"))
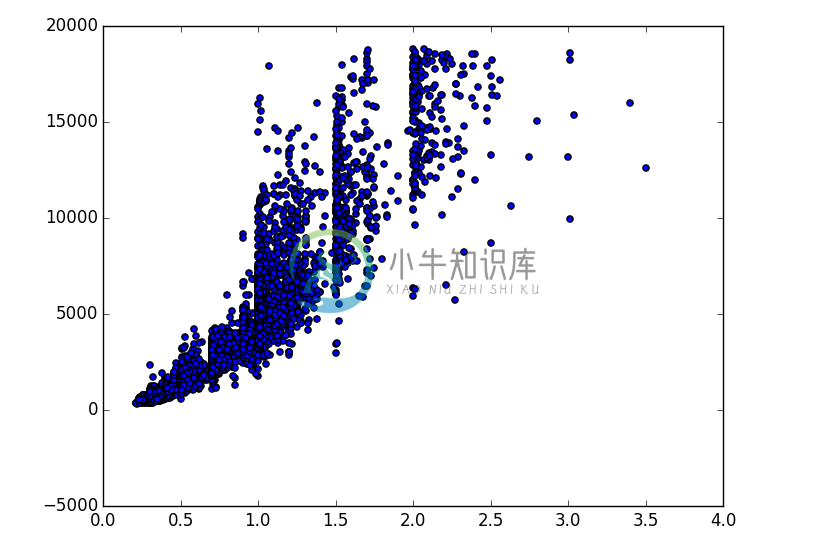
# Matplotlib works as well! import pylab as pl pl.scatter = DelayFunction(pl.scatter) diamonds >> sample_frac(0.1) >> pl.scatter(X.carat, X.price)
-
有时候,对于我们的决定只要有一点点的数据支持就够了。一点点的变化,可能就决定了我们产品的好坏。我们可能会因此而作出一些些改变,这些改变可能会让我们打败巨头。 这一点和 Growth 的构建过程也很相像,在最开始的时候我只是想制定一个成长路线。而后,我发现这好像是一个不错的 idea,我就开始去构建这个 idea。于是它变成了 Growth,这时候我需要依靠什么去分析用户喜欢的功能呢?我没有那么多的
-
笔试+3轮面试,笔试题比较开放,主要考察一些基本的概念,业务一面:首先自我介绍,面试官就简历提问,接着会跟你一个具体的案例让你回答如何识别黑产用户,附加口述一道智力测试题,最后是反问,整体面试很轻松,由于反问阶段表现得很好,所以一面后三分钟就通知结果了。 二面应该是部门leader面,更多的还是深挖简历的内容,真的很细很细,面完以后感觉表现一般,然后hr通知结果待定,基本没戏了。
-
9.20一面hr面 1.自我介绍 2.实习的收获 3.在校成绩以及相关情况 4.实习中有什么做的不足的地方 5.性格的优缺点 6.拉家常 7.反问 没想到一面竟然是hr面 #面经##4399##4399面经##数据分析师#
-
云端业务和数据已接入小米生态云的生态链企业,可以在和小米签署保密协议之后,派工程师入驻小米,以小米内部业务使用数据的流程、方式使用数据;生态链企业和小米join的数据在小米的环境里训练模型并搭建API服务,小米会协助完成生态链企业对小米数据的需求。 后续会在生态云上提供API自助服务。
-
Discover数据分析一面 - Phone Interview - 全英文 手机开了自动拦截垃圾电话,前面几个电话没接到之后才反应过来关了。(被假中国海关的诈骗电话骚扰无数次) 1. 自我介绍 2. 最喜欢的课程,为什么? 3. 怎么知道Discover和这个工作的? 4. 有在信用卡领域的工作经验吗?(没有,只知道刷卡😂) 5. 对简历一个项目详细介绍 6. SQL where和group
-
经纬恒润 1.介绍下数学建模竞赛,你做了啥工作 2.介绍下实习项目 3.你mentor对你的评价 4.薪资要求,工作地点 5.sql题