
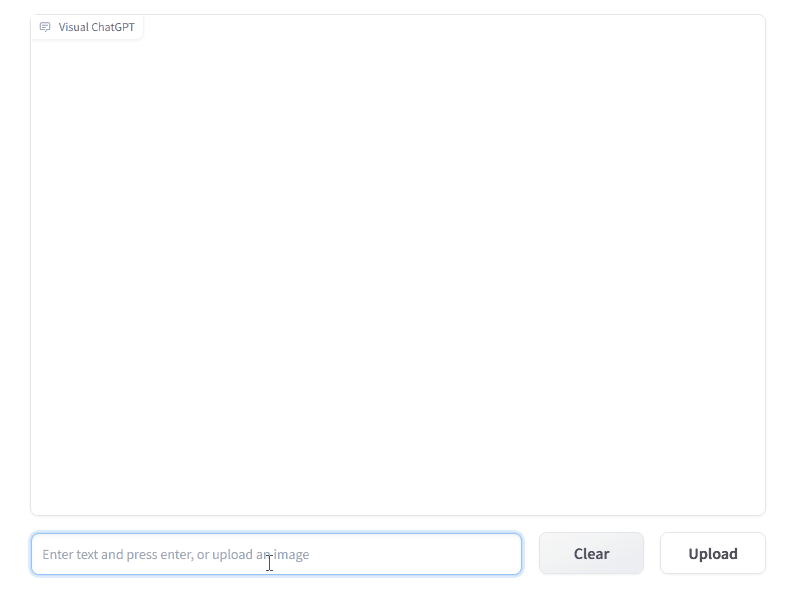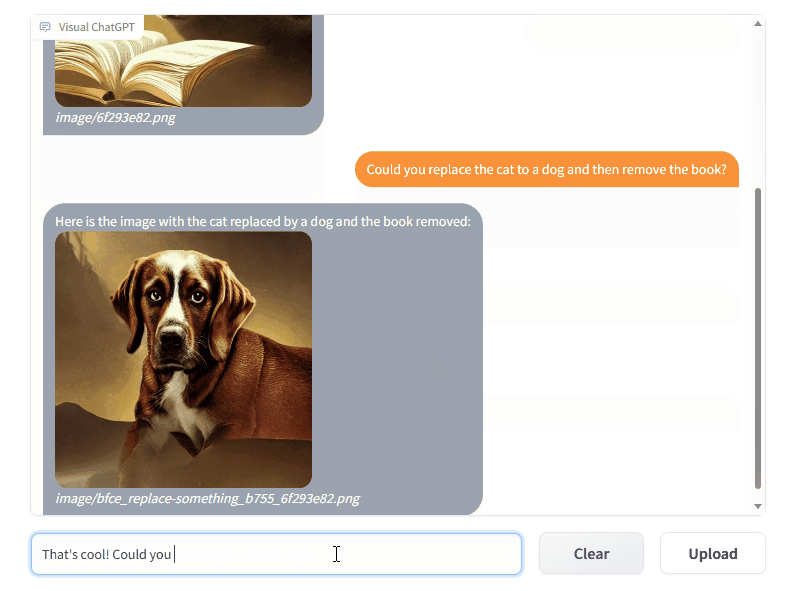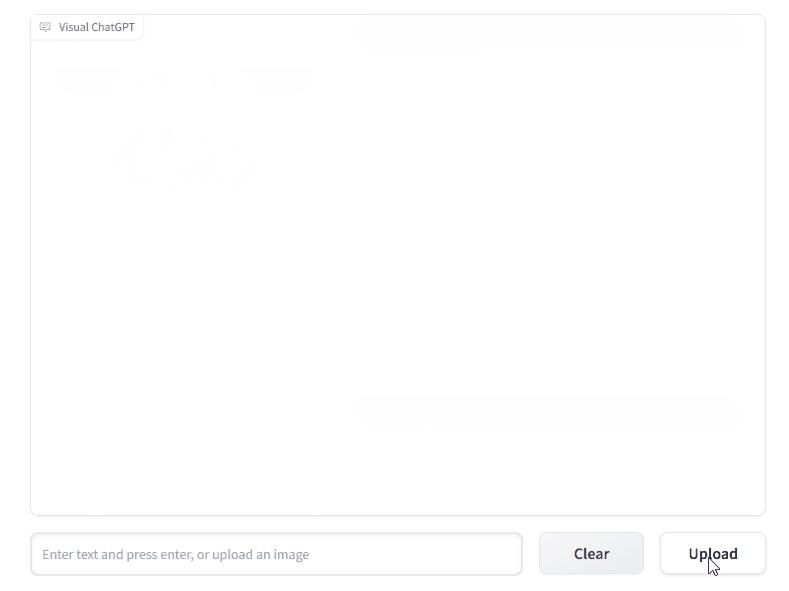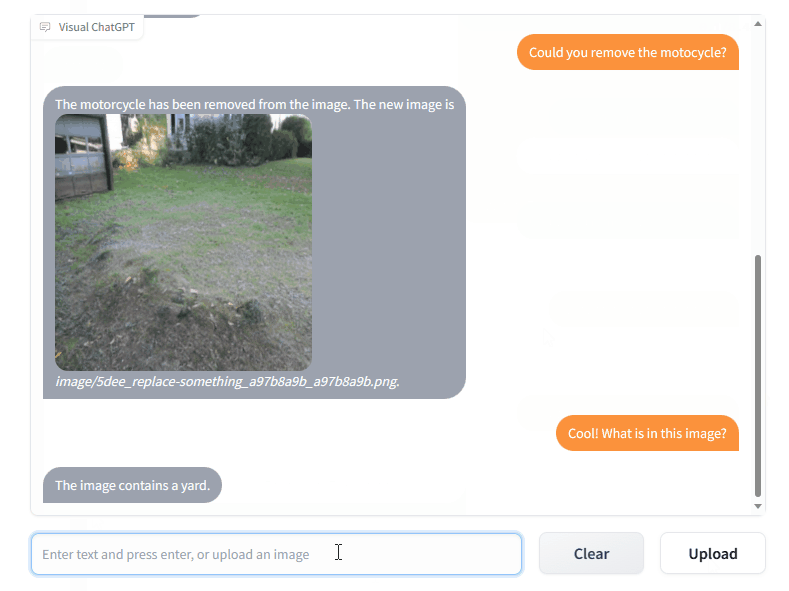
Visual ChatGPT 将 ChatGPT 和一系列视觉基础模型 (Visual Foundation Models, VFM) 连接了起来,以支持在聊天过程中发送和接收图像。
ChatGPT 采用单一语言模态训练而成,因此其处理视觉信息的能力非常有限、相比较而言,视觉基础模型在计算机视觉方面潜力巨大,因而能够理解和生成复杂的图像。
运行 Demo
架构

-
目录 前言 概括 前言 Visual Chatgpt主要是用于AI机器视觉模型的构建,目标是构建能够处理各种任务的AI。 概括 1.安装conda 1.下载安装脚本:#wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh 2.运行脚本:#bash Anaconda3-2022.10-Linux-x8
-
虚拟机镜像(本文简称镜像),是一个包含了虚拟磁盘和一个可启动的操作系统的文件。在云中,镜像可以用来创建虚拟机实例。如欲了解如何创建镜像文件,请参阅OpenStack Virtual Machine Image Guide 如果你权限够大,你可以上传和管理虚拟机镜像。操作人员可能会把上传和管理镜像的权限限制在云管理员和操作人员的角色上。如果你有相应权限,在控制台里,你可以在管理员Project中上传
-
为什么我的代码不起作用?我想把图像从一个活动转移到另一个活动。请帮忙!注意:我已经创建了一个摄像头功能,这就是我获得图像的地方。 这是主要活动。Java语言 这就是结果性。Java语言 如果我做错了什么请告诉我谢谢
-
问题内容: 结合我的另一个问题,并在更改了这部分代码之后 从解密部分,我遇到了另一个错误,这是 当我单击SheepTest.png时,文件为空。错误在哪里?谁能帮助我解决错误?谢谢。 问题答案: 我猜想这行返回null: 文档说明: “如果没有注册的ImageReader声称能够读取结果流,则返回null。” 空值将传递给此调用,从而导致NPE: 我不熟悉此API,但是从文档和此处看到的内容中,我
-
我要哭了,因为我尝试了很多解决方案和话题,但都不起作用。 null 您需要发送一个多部分请求(enctype=“multipart/form-data”)。 所以,有人能请帮助我,为什么我有HTTP 400与上面的错误消息?我可以在代码中更改什么以使此调用工作?谢谢你
-
我正在使用JavaFX,在那里我编写了一个包含的代码,通过我想在我的场景上显示图像,但它不起作用。图像不显示。 当我使用它还显示一个错误。虽然我70%的编码已经完成,但我只是坚持在现场显示图像(不上传)。 以下是我正在使用的代码: 所以,我需要的是通过单击按钮并选择图像来显示我的场景中的图像。
-
大多数图像处理和操作技术可以使用两个库进行有效的处理:Python Imaging Library (PIL) 和 OpenSource Computer Vision (OpenCV)。 下面来简单介绍一下这两个库。 Python 图像库 Python 图像库, 全称为 Python Imaging Library,简称PIL,是Python图像操作的核心库之一。遗憾的是,PIL 的开发工作已经
-
Tensorflow封装了很多图像处理的操作,包括读取图像、图像处理、写图像到文件等等。在批量处理图像时,Tensorflow要求所有的图像都要有相同的Size,即$$(height,width,channels)$$。 读取图像 %matplotlib inline import tensorflow as tf import numpy as np #mil.use('svg') mil.us