
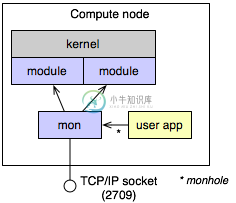
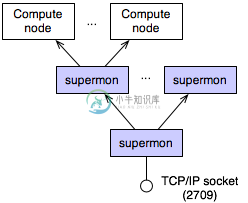
Supermon 是一个高速集群监控系统,特点是低侵入、高采样率和一个可扩展的数据协议和编程接口。可从最基本的单处理器到1024个处理器的大规模集群.
-
集群运行起来后,你可以用 ceph 工具来监控,典型的监控包括检查 OSD 状态、监视器状态、归置组状态和元数据服务器状态。 交互模式 要在交互模式下运行 ceph ,不要带参数运行 ceph ,例如: ceph ceph> health ceph> status ceph> quorum_status ceph> mon_status 检查集群健康状况 启动集群后、读写数据前,先检查下集群的健
-
集群监控的本质是一个聚合功能。 单台机器的监控指标难以反应整个集群的情况,我们需要把整个集群的机器(体现为某个HostGroup下的机器)综合起来看。比如所有机器的qps加和才是整个集群的qps,所有机器的request_fail数量 ÷ 所有机器的request_total数量=整个集群的请求失败率。 我们计算出集群的某个整体指标之后,也会有“查看该指标的历史趋势图” “为该指标配置报警” 这种
-
Kubernetes 使得管理复杂环境变得更简单,但是对 kubernetes 本身的各种组件还有运行在 kubernetes 集群上的各种应用程序做到很好的洞察就很难了。Kubernetes 本身对应用程序的做了很多抽象,在生产环境下对这些不同的抽象组件的健康就是迫在眉睫的事情。 我们在安装 kubernetes 集群的时候,默认安装了 kubernetes 官方提供的 heapster 插件,
-
在前面的安装heapster插件章节,我们已经谈到Kubernetes本身提供了监控插件作为集群和容器监控的选择,但是在实际使用中,因为种种原因,再考虑到跟我们自身的监控系统集成,我们准备重新造轮子。 针对kubernetes集群和应用的监控,相较于传统的虚拟机和物理机的监控有很多不同,因此对于传统监控需要有很多改造的地方,需要关注以下三个方面: Kubernetes集群本身的监控,主要是kube
-
在 v1.1 及更高版本的 TiDB Operator 中,我们可以通过简单的 CR 文件(即 TidbMonitor)来快速建立对 Kubernetes 集群上的 TiDB 集群的监控。 快速上手 前置条件 已经安装了 Operator v1.1.0 及以上版本,并且已经更新了相关版本的 CRD 文件 已经设置了默认的 storageClass,并保证其有足够的 PV(默认情况下需要 6 个 P
-
基于 Kubernetes 环境部署的 TiDB 集群监控可以大体分为两个部分:对 TiDB 集群本身的监控、对 Kubernetes 集群及 TiDB Operator 的监控。本文将对两者进行简要说明。 TiDB 集群的监控 TiDB 通过 Prometheus 和 Grafana 监控 TiDB 集群。在通过 TiDB Operator 创建新的 TiDB 集群时,可以参考通过 TidbMo
-
集群监控的本质是一个聚合功能。 单台机器的监控指标难以反应整个集群的情况,我们需要把整个集群的机器(体现为某个HostGroup下的机器)综合起来看。比如所有机器的qps加和才是整个集群的qps,所有机器的request_fail数量 ÷ 所有机器的request_total数量=整个集群的请求失败率。 我们计算出集群的某个整体指标之后,也会有“查看该指标的历史趋势图” “为该指标配置报警” 这种
-
上节课我们和大家学习了怎样用 Promethues 来监控 Kubernetes 集群中的应用,但是对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。 对于集群的监控一般我们需要考虑以下几个方面: Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标 内部系统组件的状态:比如 kube-scheduler、kub